jieba+wordcloud 词云分析 202302 QCon 议题 TOP 关键词
效果图

步骤
(1)依赖
-
python 库
pip install jieba wordcloud -
数据
- 概览
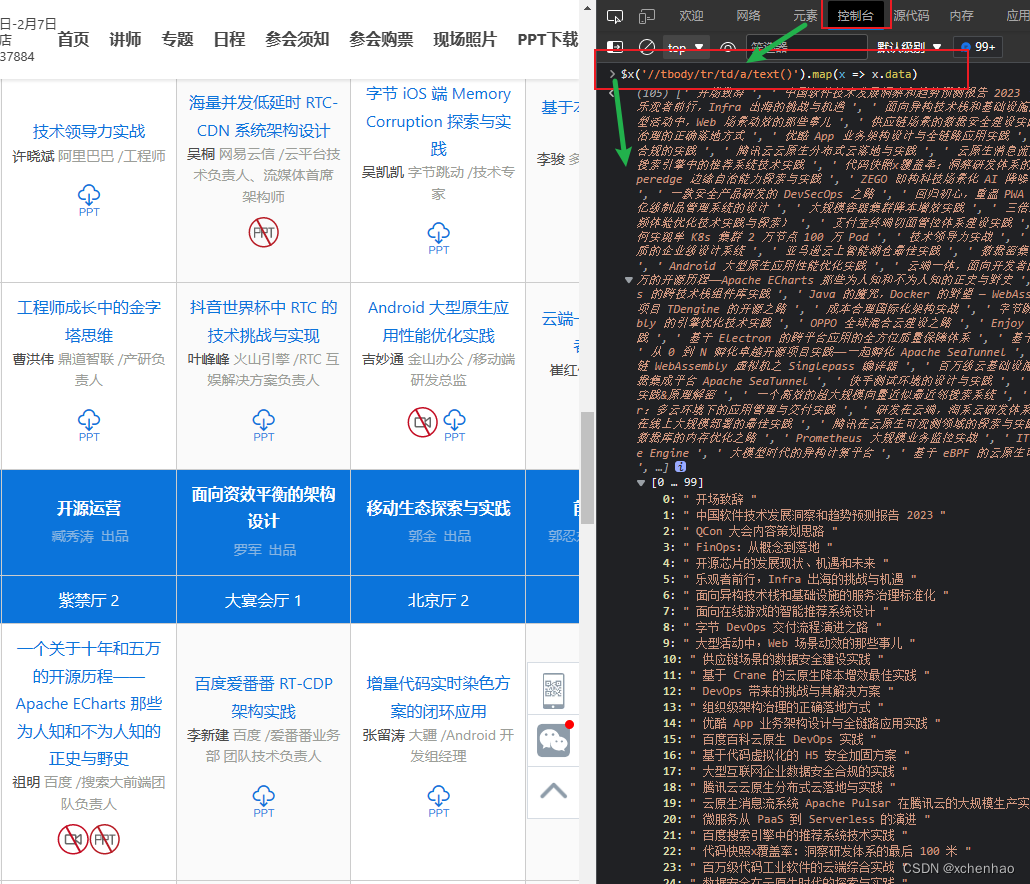
$ head -n 5 input.txt 中国软件技术发展洞察和趋势预测报告 2023 QCon 大会内容策划思路 FinOps:从概念到落地 开源芯片的发展现状、机遇和未来 乐观者前行,Infra 出海的挑战与机遇- 来源:https://qcon.infoq.cn/202302/beijing/schedule
- 提取方法:使用 Chrome 的 XPath 在控制台 Console 提取
$x('//tbody/tr/td/a/text()').map(x => x.data)
(2)源码
import jieba
import wordcloud# 对文本进行分词
# top_num 取前 top_num
# exclude_words 无关词语列表
# user_words 自定义分词
def cut_word(input_path, out_path, top_num=30, exclude_words=[], user_words=[]):file = open(input_path, 'r', encoding='utf-8')txt = file.read()if len(user_words) > 0:for user_word in user_words:jieba.add_word(user_word)words = jieba.lcut(txt)# 对词频进行统计count = {}for word in words:if len(word) == 1:continueelse:count[word] = count.get(word, 0) + 1# 遍历字典的所有键,即所有 wordfor key in list(count.keys()):# 引入停用词if key in exclude_words:del count[key]lists = list(count.items())# 词频排序lists.sort(key=lambda x: x[1], reverse=True)# 打印前 top_num 条词频for i in range(top_num):word, number = lists[i]print("关键字:{:-<5}频次:{}".format(word, number))# 词频写入with open(out_path, 'w', encoding='utf-8') as f:for i in range(top_num):word, number = lists[i]f.write('{}\t{}\n'.format(word, number))f.close()return out_path# 制作词云
def get_cloud(input_path, image_out_path):with open(input_path, 'r', encoding='utf-8') as f:text = f.read()wcloud = wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',background_color='white',width=500,max_words=1000,height=400,margin=5).generate(text)# 指定词云文件路径wcloud.to_file(image_out_path)f.close()print("词云图片已保存")if __name__ == '__main__':cut_word('./input.txt', out_path='./wordcloud.txt', top_num=200, exclude_words=['实践', '技术', '基于', '应用', '建设', '实战', '探索', '系统', '体系'], user_words=['云原生', '研发效能', '分布式', '微服务'])get_cloud(input_path='./wordcloud.txt', image_out_path='./qcon.png')
参考
- https://www.cnblogs.com/yangyezhuang/p/16896980.html
- https://blog.csdn.net/zhangzeyuaaa/article/details/122192065
- https://baijiahao.baidu.com/s?id=1702691581630693235