Iceberg and AIStor 的Lakehouse Architecture 权威指南

Apache Iceberg 似乎已经掀起了一场(暴风雪)数据世界。它最初由 Ryan Blue(也是 Tabular 的成员,现在是 Databricks 的名人)在 Netflix 孵化,最终被传输到它目前所在的 Apache 软件基金会。从本质上讲,它是一种适用于大规模数据集(想想数百 TB 到数百 PB)的开放表格式。随着 AI 吞噬大量数据用于创建、调整和实时推理,自最初开发以来,对这项技术的需求只增不减。Iceberg 是一种多引擎兼容格式。这意味着 Spark、Trino、Flink、Presto、Snowflake 和 Dremio 都可以独立且同时地对同一数据集进行作。Iceberg 支持 SQL(数据分析的通用语言),并提供原子事务、架构演变、分区演变、时间旅行、回滚和零副本分支等高级功能。本文探讨了 Iceberg 的功能和设计与 AIStor 的高性能存储层搭配使用时,如何提供构建数据湖仓一体所需的灵活性和可靠性。
现代 Open Table 格式的目标
Lakehouse 的前景在于它能够统一最好的数据湖和仓库。存储在对象存储上的数据湖旨在以原生格式存储大量原始数据,从而提供可扩展性、易用性和成本效益。然而,数据湖本身就难以解决数据治理等问题,以及有效查询存储在其中的数据的能力。另一方面,仓库针对结构化数据和 SQL 分析进行了优化,但在大规模处理半结构化或非结构化数据方面存在不足。Iceberg 和其他开放表格式(如 Apache Hudi 和 Delta Lake)代表了一次飞跃。这些格式使数据湖的行为类似于仓库,同时保留了对象存储的初始灵活性和可扩展性。这种新的开放表格式和开放式存储堆栈可以支持各种工作负载,例如 AI、机器学习、高级分析和实时可视化。Iceberg 以其 SQL 优先的方法而著称,并专注于多引擎兼容性。
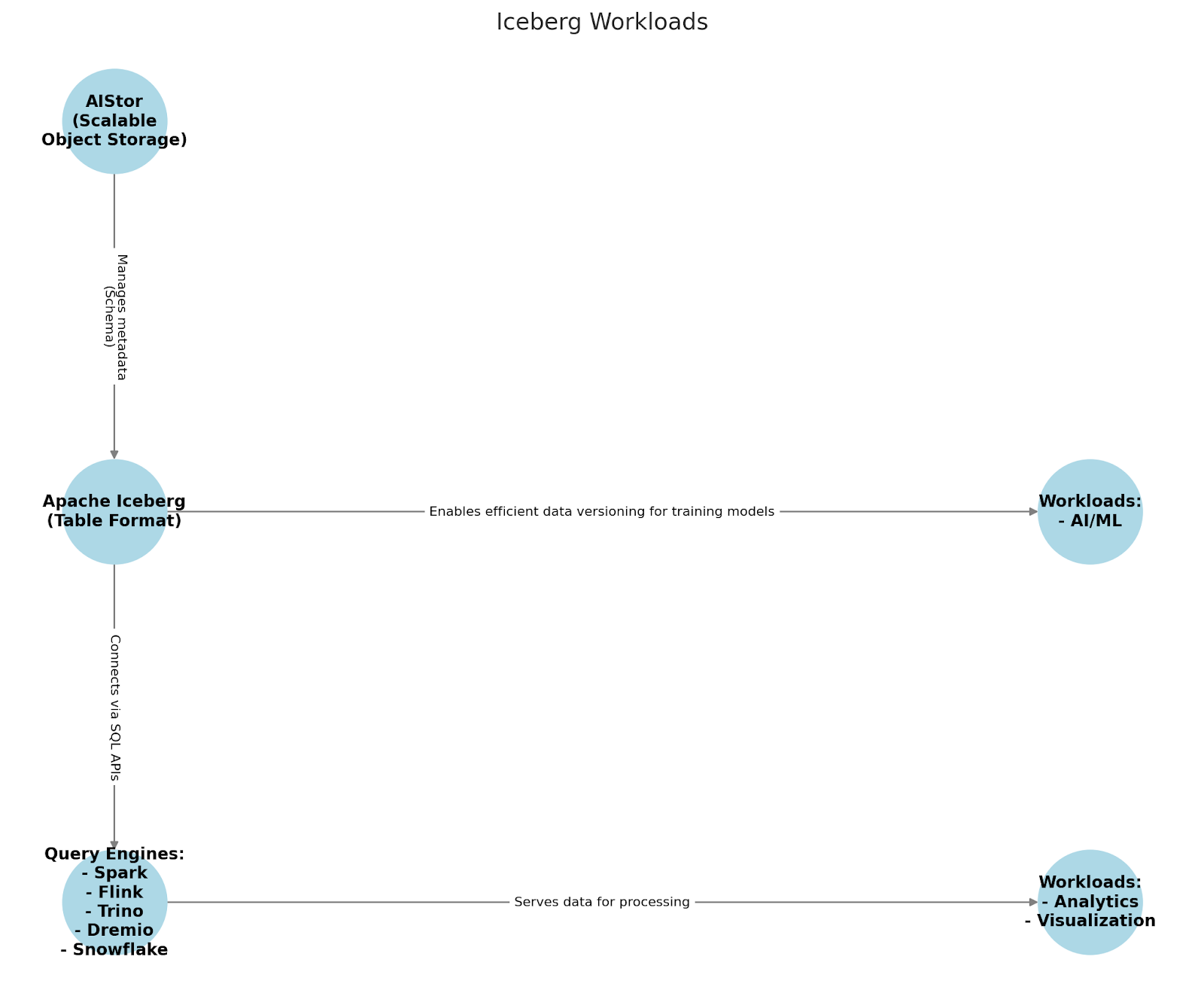
以下是此基础结构的运行方式。查询引擎可以直接位于堆栈中的对象存储之上,并查询其中的数据,而无需迁移。将数据迁移到 d 数据库存储的旧模式不再相关。相反,您可以而且应该能够从任何位置查询 Iceberg 表。分析工具和可视化通常可以直接连接到存储 Iceberg 表的存储,但更常见的是与您的查询引擎交互,以获得更简化的用户体验。最后,AI/ML 具有与查询引擎相同的设计原则。这些 AI/ML 工具将直接在对象存储中使用 Iceberg 表,而无需迁移。虽然目前并非所有 AI/ML 工具都使用 Iceberg,但人们对将 Iceberg 用于 AI/ML 工作负载的兴趣越来越大,特别是因为它们能够轻松维护多个版本的模型和数据集。
Iceberg 的特别之处
Apache Iceberg 通过功能和设计原则的组合将自己与它区分开来,使其与 Apache Hudi 和 Delta Lake 等替代品区分开来。
Schema Evolution:Iceberg 为 Schema Evolution 提供全面支持,允许用户添加、删除、更新或重命名列,而无需完全重写现有数据。这种灵活性确保可以无缝地实施对数据模型的更改,从而保持运营连续性。
分区演变:Iceberg 支持分区演变,允许随着时间的推移修改分区方案,而无需重写数据。此功能允许在访问模式发生变化时动态优化数据布局。
元数据管理:Iceberg 采用分层元数据结构,包括清单文件、清单列表和元数据文件。此设计通过提供有关数据文件的详细信息来增强查询规划和优化,从而促进高效的数据访问和管理。
多引擎兼容性:Iceberg 在设计时充分考虑了开放性,兼容 Apache Spark、Flink、Trino 和 Presto 等各种处理引擎。这种互作性使组织能够灵活地选择最适合其需求的工具,并有效地将查询引擎商品化,从而降低价格并推动这些产品的创新。
开源社区:与所有开放表格格式一样,Iceberg 受益于多元化和活跃的社区,这有助于其稳健性和持续改进。
对象存储和 Iceberg
对象存储构成了现代湖仓一体架构的基础,提供了跨多个环境管理大量数据集所需的可扩展性、持久性和成本效益。在湖仓一体架构中,存储层在确保数据的持久性和可用性方面起着关键作用,而像 Iceberg 这样的开放表格式则管理元数据。AIStor 特别适合这些要求。例如,对于模型训练等高吞吐量工作负载,AIStor 对 S3 over RDMA 的支持可确保对数据的低延迟访问。此功能使这两种技术的组合成为非常有效的解决方案,特别是对于大规模 AI 和分析管道。高性能对于湖仓一体计划的成功至关重要 - 如果您的表格式无法像用户需要的那样快速提供查询,那么它有多酷都无关紧要。
亲自尝试:先决条件
您需要安装 Docker 和 Docker Compose。当两者都需要时,安装 Docker Desktop 通常更容易。从 Docker 官方网站下载并安装 Docker Desktop。按照安装程序中提供的作系统安装说明进行作。打开 Docker Desktop 以确保其正在运行。如果您愿意,您还可以通过打开终端并运行以下命令来验证 Docker 和 Docker Compose 的安装:
docker --version
docker-compose --version
Iceberg 教程
本节演示了如何集成 Iceberg 和 AIStor 以实现强大的湖仓一体架构。我们将使用 Apache Iceberg Spark 快速入门来设置我们的初始环境:
第 1 步:使用 Docker Compose 进行设置
按照 Apache Iceberg Spark 快速入门指南启动预配置 Spark 和 Iceberg 的容器化环境。本指南的第一步是将以下信息复制到一个文件中,并另存为名为 docker-compose.yml 的文件:
version: "3"
services:spark-iceberg:image: tabulario/spark-icebergcontainer_name: spark-icebergbuild: spark/networks:iceberg_net:depends_on:- rest- miniovolumes:- ./warehouse:/home/iceberg/warehouse- ./notebooks:/home/iceberg/notebooks/notebooksenvironment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1ports:- 8888:8888- 8080:8080- 10000:10000- 10001:10001rest:image: apache/iceberg-rest-fixturecontainer_name: iceberg-restnetworks:iceberg_net:ports:- 8181:8181environment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1- CATALOG_WAREHOUSE=s3://warehouse/- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO- CATALOG_S3_ENDPOINT=http://minio:9000minio:image: minio/miniocontainer_name: minioenvironment:- MINIO_ROOT_USER=admin- MINIO_ROOT_PASSWORD=password- MINIO_DOMAIN=minionetworks:iceberg_net:aliases:- warehouse.minioports:- 9001:9001- 9000:9000command: ["server", "/data", "--console-address", ":9001"]mc:depends_on:- minioimage: minio/mccontainer_name: mcnetworks:iceberg_net:environment:- AWS_ACCESS_KEY_ID=admin- AWS_SECRET_ACCESS_KEY=password- AWS_REGION=us-east-1entrypoint: >/bin/sh -c "until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;/usr/bin/mc rm -r --force minio/warehouse;/usr/bin/mc mb minio/warehouse;/usr/bin/mc policy set public minio/warehouse;tail -f /dev/null"
networks:iceberg_net:接下来,在终端窗口中导航到保存 .yml 文件的位置,然后使用以下命令启动 docker 容器:
docker-compose up
然后,您可以运行以下命令来启动 Spark-SQL 会话。
docker exec -it spark-iceberg spark-sql
步骤 2:创建表
打开 Spark shell 并创建一个表:
CREATE TABLE my_catalog.my_table (id BIGINT,data STRING,category STRING
)
USING iceberg
PARTITIONED BY (category);
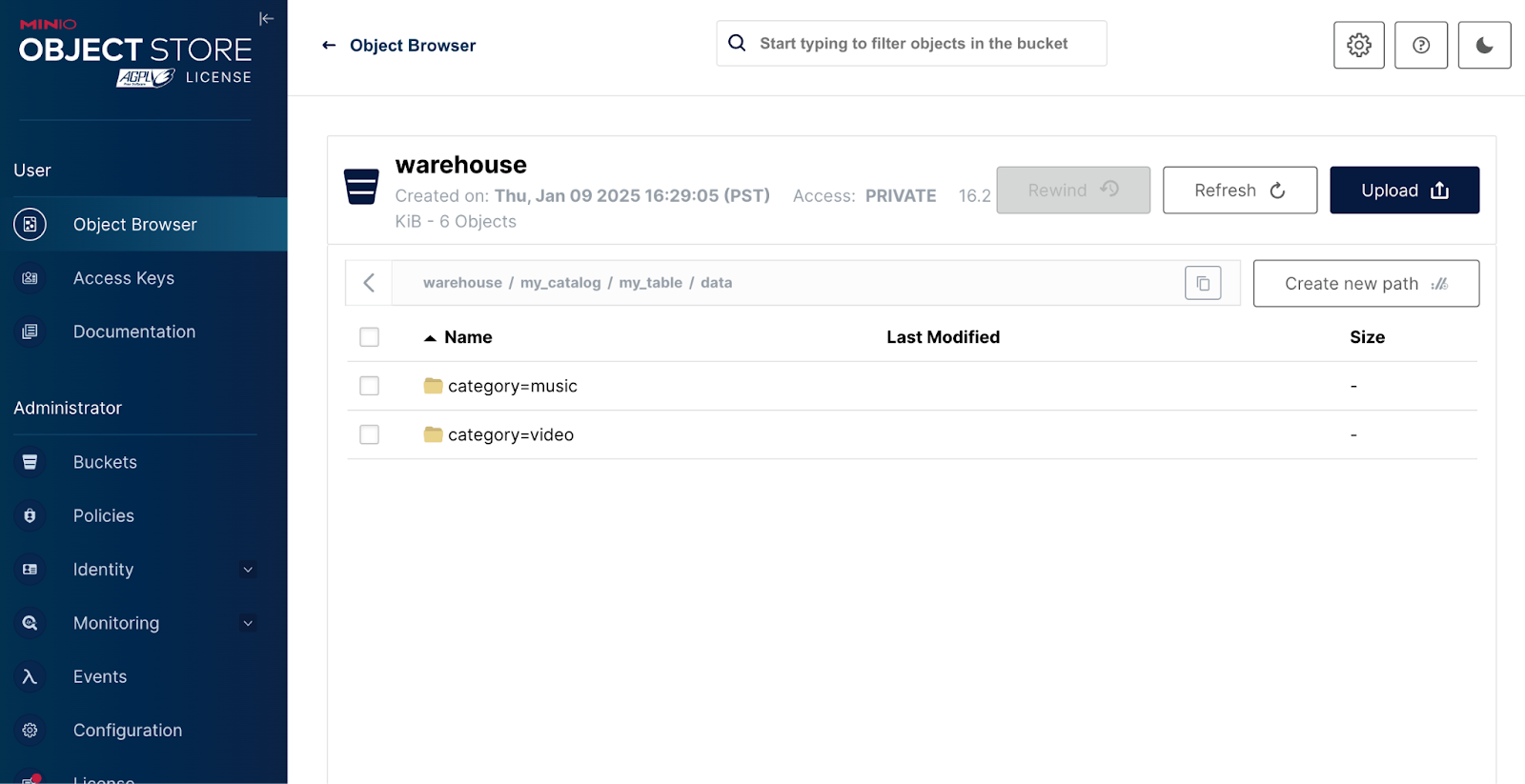
导航到 http://127.0.0.1:9001 并使用 .yml 中的凭证登录,检查您的 MinIO 控制台:AWS_ACCESS_KEY_ID=admin、AWS_SECRET_ACCESS_KEY=password
在这里,观察为表创建的 iceberg/my_table/metadata 路径。最初,不存在任何数据文件,只存在定义架构和分区的元数据。
第 3 步:插入数据
插入一些 mock 数据:
INSERT INTO my_catalog.my_table VALUES
(1, 'a', 'music'),
(2, 'b', 'music'),
(3, 'c', 'video');此作在相应的分区 (my_table/data/category=…) 中创建数据文件并更新元数据。
第 4 步:查询数据
运行基本查询以验证:
SELECT COUNT(1) AS count, data
FROM my_catalog.my_table
GROUP BY data;
您的输出应如下所示:
spark-sql ()> SELECT COUNT(1) AS count, data > FROM my_catalog.my_table > GROUP BY data;
1 c
1 b
1 a
Time taken: 0.575 seconds, Fetched 3 row(s)测试 Iceberg 的关键功能
现在,您已经使用可作的数据建立了基准数据湖仓一体。让我们看看使 Iceberg 独一无二的功能:Schema Evolution 和 Partition Evolution。
架构演变
架构演变是 Apache Iceberg 最强大和最具决定性的功能之一,解决了传统仓库系统中的一个重大痛点。它允许您修改表的架构,而无需昂贵且耗时的数据重写,这对于大规模数据集特别有益。此功能使组织能够根据业务需求的发展调整其数据模型,而不会中断正在进行的查询或作。在 Iceberg 中,架构更改仅在元数据级别处理。表中的每一列都分配有一个唯一的 ID,以确保对架构的更改不会影响底层数据文件。例如,如果添加了一个新列,Iceberg 会为其分配一个新 ID,而无需重新解释或重写现有数据。这样可以避免错误并确保与历史数据的向后兼容性。下面是 Schema 演变在实践中如何工作的示例。假设您需要添加新列 buyer 来存储有关交易的其他信息。您可以执行以下 SQL 命令:
ALTER TABLE my_catalog.my_table ADD COLUMN buyer STRING;
此作会更新表的元数据,从而允许新数据文件包含 buyer 列。旧数据文件保持不变,并且可以编写查询以无缝处理新数据和旧数据。同样,如果不再需要某个列,则可以将其删除,而不会影响存储的数据:
ALTER TABLE my_catalog.my_table DROP COLUMN buyer;此作将更新架构以排除 category 列。Iceberg 可确保清理任何关联的元数据,同时保持可能仍引用较旧数据版本的历史查询的完整性。Iceberg 的架构演变还支持重命名列、更改列类型和重新排列列顺序,所有这些都通过高效的纯元数据作实现。这些更改无需更改数据文件即可进行,从而使架构修改即时且经济高效。
这种方法在架构频繁更改的环境中尤其有利,例如由 AI/ML 实验、动态业务逻辑或不断变化的法规要求驱动的环境。
分区演变
Iceberg 支持分区演变,可以处理为表中的行生成分区值的繁琐且容易出错的任务。用户专注于向解决业务问题的查询添加筛选器,而不用担心表的分区方式。Iceberg 会自动避免从不必要的分区中读取数据。Iceberg 为您处理分区和更改表分区方案的复杂性,从而大大简化了最终用户的过程。您可以定义分区,也可以让 Iceberg 为您处理。Iceberg 喜欢根据时间戳进行分区,例如事件时间。分区由清单中的快照跟踪。查询不再依赖于表的物理布局。由于物理表和逻辑表之间的这种分离,Iceberg 表可以随着添加更多数据而随着时间的推移而演变分区。
ALTER TABLE my_catalog.my_table ADD COLUMN month int AFTER buyer;
ALTER TABLE my_catalog.my_table ADD PARTITION FIELD month;
现在,对于同一个表,我们有两个分区方案。从现在开始,查询计划是拆分的,使用旧的分区方案查询旧数据,使用新的分区方案查询新数据。Iceberg 会为您处理这个问题 — 查询表的人不需要知道数据是使用两个分区方案存储的。Iceberg 通过组合幕后的 WHERE 子句和分区筛选器来实现这一点,这些筛选器会删除没有匹配项的数据文件。
时间旅行和回滚
每次写入 Iceberg 表都会创建新的快照。快照与版本类似,可用于时间旅行和回滚,就像我们使用 AIStor 版本控制功能的方式一样。管理快照的方式是通过设置 expireSnapshot 来维护系统。按时间顺序查看支持使用完全相同的表快照的可重现查询,或者允许用户轻松检查更改。版本回滚允许用户通过将表重置为良好状态来快速纠正问题。当表发生更改时,Iceberg 会将每个版本作为快照进行跟踪,然后在查询表时提供时间旅行到任何快照的功能。如果要运行历史查询或重现以前查询的结果(可能用于报告),这可能非常有用。在测试新代码更改时,时间旅行也很有帮助,因为您可以使用已知结果的查询来测试新代码。要查看已为表保存的快照,请运行以下查询:
SELECT * FROM my_catalog.my_table.snapshots;
您的输出应如下所示:
2025-01-10 00:35:03.35 4613228935063023150 NULL append s3://warehouse/my_catalog/my_table/metadata/snap-4613228935063023150-1-083e4483-566f-4f5c-ab47-6717577948cb.avro {"added-data-files":"2","added-files-size":"1796","added-records":"3","changed-partition-count":"2","spark.app.id":"local-1736469268719","total-data-files":"2","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"1796","total-position-deletes":"0","total-records":"3"}
Time taken: 0.109 seconds, Fetched 1 row(s)
一些例子:
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM my_catalog.my_table TIMESTAMP AS OF '1986-10-26 01:21:00';-- time travel to snapshot with id 10963874102873
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;
您可以使用快照执行增量读取,但必须使用 Spark,而不是 Spark-SQL。例如
scala> spark.read()
.format(“iceberg”)
.option(“start-snapshot-id”, “10963874102873”)
.option(“end-snapshot-id”, “10963874102994”)
.load(“s3://iceberg/my_table”)
您还可以将表回滚到某个时间点或特定快照,如以下两个示例所示
CALL my_catalog.system.rollback_to_timestamp(‘my_table’, TIMESTAMP ‘2022-07-25 12:15:00.000’);
CALL my_catalog.system.rollback_to_snapshot(‘my_table’, 527713811620162549);
富有表现力的 SQL
Iceberg 支持所有富有表现力的 SQL 命令,如行级删除、合并和更新,需要强调的最重要的一点是 Iceberg 同时支持 Eager 和 lazy 策略。我们可以对所有需要删除的内容进行编码(例如,GDPR 或 CCPA),但不会立即重写所有这些数据文件,我们可以根据需要懒惰地收集垃圾,这有助于提高 Iceberg 支持的巨大表的效率。例如,您可以删除表中与特定谓词匹配的所有记录。以下内容将从 video 类别中删除所有行。
DELETE FROM my_catalog.my_table WHERE category = 'video';
或者,您可以使用 CREATE TABLE AS SELECT 或 REPLACE TABLE AS SELECT 来完成此作:
CREATE TABLE my_catalog.my_table_music AS SELECT * FROM my_catalog.my_table WHERE category = 'music';
你可以很容易地合并两个表:
MERGE INTO my_catalog.my_data pt USING (SELECT * FROM my_catalog.my_data_new) st ON pt.id = st.id WHEN NOT MATCHED THEN INSERT *;数据工程
Iceberg 是开放分析表标准的基础,它使用 SQL 行为并应用数据仓库基础知识,在我们知道自己有问题之前就解决了问题。通过声明式数据工程,我们可以配置表,而不必担心更改每个引擎以适应数据的需求。这将解锁自动优化和推荐。通过安全提交,数据服务成为可能,这有助于避免人工照看数据工作负载。以下是这些类型配置的一些示例:
为了检查表的历史记录、快照和其他元数据,Iceberg 支持查询元数据。元数据表是通过在查询中的原始表名称后添加元数据表名称(例如,history)来标识的。要显示表的数据文件:
SELECT * FROM my_catalog.my_table.files;
要显示清单:
SELECT * FROM my_catalog.my_table.manifests;
显示表历史记录
SELECT * FROM my_catalog.my_table.history;
显示快照
SELECT * FROM my_catalog.my_table.snapshots;
您还可以联接快照和表历史记录,以查看写入每个快照的应用程序
select
h.made_current_at,
s.operation,
h.snapshot_id,
h.is_current_ancestor,
s.summary['spark.app.id']
from my_catalog.my_table.history h
join my_catalog.my_table.snapshots s
on h.snapshot_id = s.snapshot_id
order by made_current_at;现在您已经了解了基础知识,请将一些数据加载到 Iceberg 中,然后从 Iceberg 文档中了解更多信息。
集成
各种查询和执行引擎都实施了 Iceberg 连接器,从而可以轻松创建和管理 Iceberg 表。支持 Iceberg 的引擎包括 Spark、Flink、Presto、Trino、Dremio、Snowflake,而且这个列表还在不断增加。这种广泛的集成环境确保组织可以采用 Apache Iceberg,而不必局限于单个处理引擎,从而提高其数据基础架构的灵活性和互作性。
目录
在任何权威指南中,更不用说目录了。Iceberg 目录是管理表元数据和促进数据集和查询引擎之间连接的核心。这些目录维护表架构、快照和分区布局等关键信息,从而启用 Iceberg 的高级功能,如时间旅行、架构演变和原子更新。有多种目录实施可供选择,以满足不同的运营需求。例如,Polaris 提供针对现代数据基础设施量身定制的可扩展云原生编目解决方案,而 Dremio Nessie 则引入了类似 Git 的语义的版本控制,使团队能够精确跟踪数据和元数据的更改。Hive Metastore 等传统解决方案仍然被广泛使用,特别是为了向后兼容旧系统。
使用 Iceberg 和 AIStor 构建数据湖很酷
Apache Iceberg 作为数据湖的表格格式受到广泛关注。不断壮大的开源社区以及来自多个云提供商和应用程序框架的集成数量不断增加,这意味着是时候认真对待 Iceberg,并开始试验、学习和规划将其集成到现有数据湖架构中了。将 Iceberg 与 AIStor 配对,实现多云数据湖仓一体和分析。