一文讲透大模型部署工具ollama--结合本地化部署deepseek实战
Ollama 是一个开源的人工智能平台,专注于在本地高效运行大型语言模型(LLMs)。通过 Ollama,开发者可以在自己的机器上运行多种大规模语言模型,而不必依赖于云端服务。它支持对大模型的管理和本地化部署,并且提供了易于使用的客户端接口和 WebUI 部署,帮助开发者高效地与语言模型交互。
1. Ollama 的功能和作用
Ollama 提供了一系列功能,专门用于本地化大模型的管理、部署和交互。它的核心功能包括:
1.1 本地部署大语言模型
Ollama 允许用户在本地环境中运行大语言模型(例如 GPT 系列、LLama、BERT 等),这意味着数据可以保存在本地机器上,避免了云端处理的隐私和延迟问题。
1.2 高效模型管理
Ollama 提供了一种高效的方式来管理本地模型。用户可以方便地下载、切换、加载和卸载模型,并且可以在本地机器上进行模型调优。
1.3 支持多种大模型
Ollama 支持多种主流的开源大语言模型,包括 GPT-2, GPT-3、LLaMA、T5、BERT 等。它允许用户导入、运行和对这些模型进行本地交互。
1.4 Web UI 可视化界面
Ollama 提供了一个 WebUI,用户可以通过浏览器界面与语言模型进行交互。WebUI 提供了简洁易用的界面,支持文本输入和输出查看。
1.5 Python API 支持
Ollama 提供 Python API,允许开发者通过代码与模型交互,可以集成到自己的应用程序或服务中,进行更加灵活的操作。
2. Ollama 软件安装和参数设置
2.1 Ollama 安装步骤
Ollama 提供了多平台支持(如 Linux、macOS 和 Windows)。以下是通用的安装步骤:
macOS 示例
下载 Ollama 安装包 访问 Ollama 官网下载适用于你的操作系统的最新版本。
安装步骤 对于 macOS,你可以通过 Homebrew 安装:
brew install ollama
安装完成后验证 通过以下命令验证安装是否成功:
ollama --version
Linux 示例
安装依赖项
在 Linux 上,首先需要安装一些依赖项,例如 curl 和 tar:
sudo apt-get install curl tar
下载并解压 Ollama 安装包
使用 curl 下载并解压:
curl -LO https://ollama.com/download/ollama-linux.tar.gz
tar -xvzf ollama-linux.tar.gz
将 Ollama 添加到 PATH
sudo mv ollama /usr/local/bin/
验证安装
ollama --version
2.2 常用参数设置
Ollama 提供了一些常用的命令行参数,以下是几个常见的命令及其参数:
2.2.1 查看当前安装的模型
ollama list
该命令会列出本地已经安装的所有语言模型。
2.2.2 加载特定模型
如果想加载一个特定的模型,可以使用以下命令:
ollama run <model_name>
例如,加载 deepseek-r1 模型:
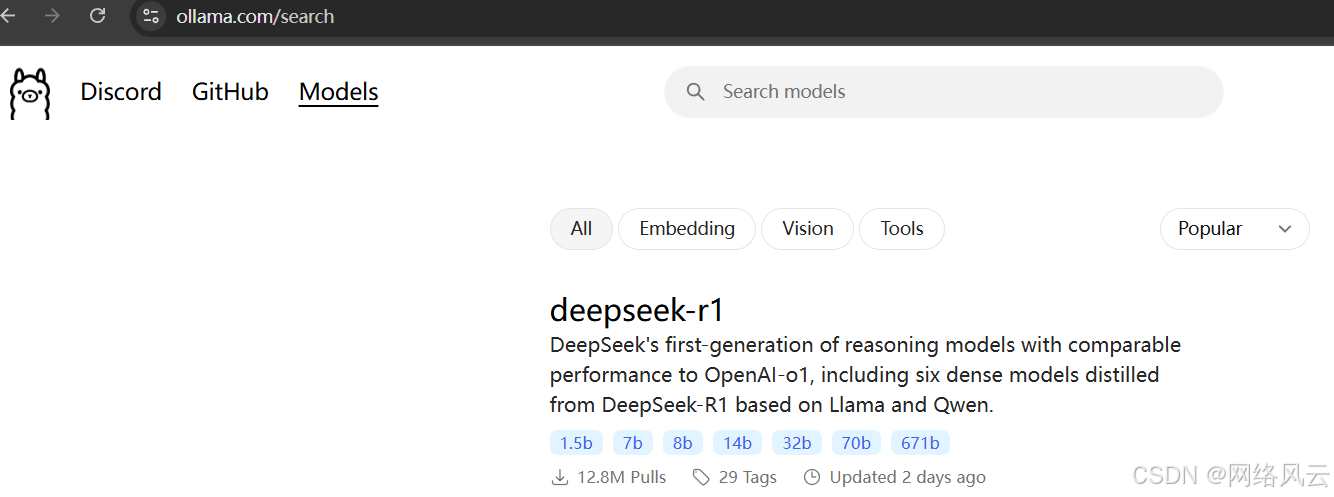
这里说明一下:只有671B是满血deepseek大模型,其它的都是阉割版。另外根据自身电脑配置选择规格参考如下(配置太低是跑不动高规格模型的)
| 模型 | 显存需求 | 内存需求 | 推荐显卡 | 性价比方案 |
| 7B | 10-12GB | 16GB | RTX 3060 | 二手2060S |
| 14B | 20-24GB | 32GB | RTX 3090 | 双卡2080Ti |
| 32B | 40-48GB | 64GB | RTX 4090 | 租赁云服务器 |
ollama run deepseek-r1:1.5b(受硬件影响,风云这里下载了一个最低版的入门级,测试一下功能)
如下界面,表示安装成功

2.2.3 获取模型帮助信息
ollama help <command>
例如,查看 run 命令的帮助:
ollama help run
3. Ollama 对大模型的管理
Ollama 允许用户高效管理本地的大模型。它提供了模型下载、切换、卸载、更新等功能,支持用户根据需要进行灵活的操作。
管理命令包括:
- ollama list:显示模型列表。
- ollama show:显示模型的信息
- ollama pull:拉取模型
- ollama push:推送模型
- ollama cp:拷贝一个模型
- ollama rm:删除一个模型
- ollama run:运行一个模型
3.1 下载和安装模型
用户可以通过 Ollama 的命令行工具来下载不同的大模型。以下载 LLaMA 模型为例:
ollama install llama
模型会被自动下载并解压到本地环境中。你可以通过 ollama list 来检查已经安装的模型。
3.2 切换模型
通过 Ollama,用户可以方便地切换不同的模型。例如,你可以切换从 GPT-3 到 LLaMA:
ollama switch llama
3.3 卸载模型
如果不再需要某个模型,用户可以通过以下命令来卸载:
ollama uninstall <model_name>
例如,卸载 LLaMA:
ollama uninstall llama
4. Ollama 导入大模型的具体方式和操作步骤
4.1 导入模型
Ollama 允许用户导入自定义的大语言模型。以下是导入模型的步骤:
准备好模型文件:首先,确保你已经有了一个经过训练的大语言模型的文件。
模型上传:如果你有本地的 .bin、.pth 等模型文件,可以通过 Ollama 命令行工具上传这些文件到本地。
例如,假设你已经下载了一个大模型文件 mymodel.pth,可以使用以下命令导入该模型:
ollama import --file /path/to/mymodel.pth
验证导入的模型:导入后,使用 ollama list 查看已安装的模型,确保它已经正确安装。
5. Web UI 部署 Ollama 可视化对话界面
Ollama 提供了 WebUI 部署功能,可以通过浏览器与语言模型进行交互。以下是 WebUI 的部署步骤:
5.1 安装 WebUI 依赖
首先,需要安装支持 WebUI 的依赖,如 Node.js 和 npm。你可以使用以下命令来安装这些依赖:
sudo apt-get install nodejs npm
5.2 启动 WebUI
风云选择了在Docker上安装一个Open-WebUI组件,让DeepSeek-R1可以通过浏览器界面交互,并赋予它联系上下文的能力。
具体来看,需要先下载Docker桌面端(如果不会的,可以再去百度,按照默认的引导完成安装即可),再次打开PowerShell界面复制并执行以下这条指令,风云帮大家省下去Github查找的时间了:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
该命令会启动一个 Web 服务器,默认情况下,WebUI 将会在 http://localhost:3000 上运行。
5.3 访问 WebUI
打开浏览器,访问以下地址:
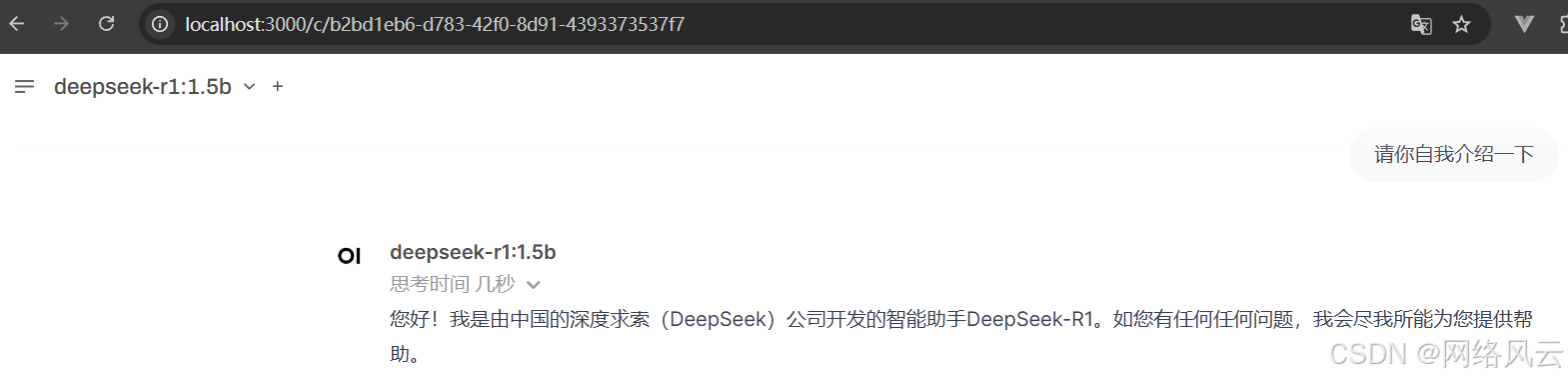
http://localhost:3000
在这个界面上,你可以与模型进行交互,输入问题并得到模型的响应。
6. 用 Python 实现 Ollama 客户端 API 调用
Ollama 提供了 Python API,允许开发者在 Python 环境中与语言模型进行交互。以下是 Python 客户端的集成步骤:
6.1 安装 Ollama Python 库
使用 pip 安装 Ollama 的 Python 客户端:
pip install ollama
6.2 Python 调用示例
以下是一个基本的 Python 示例,展示如何通过 Ollama API 调用模型:
import ollama# 流式输出
def api_generate(text:str):print(f'提问:{text}')stream = ollama.generate(stream=True,model='deepseek-r1:1.5b',prompt=text,)print('-----------------------------------------')for chunk in stream:if not chunk['done']:print(chunk['response'], end='', flush=True)else:print('\n')print('-----------------------------------------')print(f'总耗时:{chunk['total_duration']}')print('-----------------------------------------')if __name__ == '__main__':# 流式输出api_generate(text='天空为什么是蓝色的?')# 非流式输出content = ollama.generate(model='deepseek-r1:1.5b', prompt='天空为什么是蓝色的?')print(content)
在这个示例中,我们加载了deepseek-r1:1.5b 模型,发送了一个简单的问题请求,并打印了模型的响应。
6.3 更多 API 调用
Ollama 的 Python API 提供了更多的功能,例如调整温度、控制生成的最大token数等:
response = model.chat('中国首都是哪里?', temperature=0.7, max_tokens=100)
print(response['text'])
Ollama 是一个强大的本地化大语言模型管理平台,能够让开发者方便地在本地机器上运行和管理各种大模型。通过简单的命令行工具、WebUI 界面和 Python API,用户可以高效地进行模型的管理、交互和集成。无论是对大模型的安装、更新、切换,还是与模型的互动,Ollama 都提供了直观且灵活的方式,帮助开发者充分发挥大语言模型的优势。