基于PaddleOCR的图像文字识别与程序打包方法
目录
一、基本介绍
二、程序实现
1)环境配置
2)代码实现
3)程序运行结果
三、程序打包
1)使用pyinstaller打包程序
2)添加依赖和模型数据
四、需要注意的问题
五、总结
一、基本介绍
本文主要介绍利用现有开源的图像文字识别(OCR)库,开发一个简单的程序,用于识别图像中的文字信息。当前,开源的OCR库有很多,比如国外的Tesseract、EasyOCR,国内百度、阿里、腾讯等均提供了相应的开源工具包。百度的PaddleOCR在中文识别上准确率很高,百度开发的paddleocr库也为人工智能开发提供了各类算法模型,在人工智能开发领域运用比较广泛。本文基于PaddleOCR,在python中利用百度已经训练好的OCR模型库,完成对图像中文字识别,并将开发程序打包,使其可移植到其他电脑终端使用。
二、程序实现
1)环境配置
(1)新建工程
python程序开发使用的IDE工具是pyChram2023.1.21版,直接新建一个纯python项目,并新构建一个虚拟环境,基本设置如下,工程路径可自定义。
(2)安装依赖包
使用PaddleOCR需要安装两个依赖包,分别是paddlepaddle和paddleocr。这两个依赖包均安装在上一步建立的虚拟环境下(venv_WZSB)。需要注意的是,paddleocr目前只支持到python3.8到python3.11版本,若使用的python版本不在此区间,需要安装一个在此区间的版本,并将当前python解释器设置为此可用的版本,否则paddleocr将安装失败。
![]()
![]()
2)代码实现
使用python编写一个简易的窗口程序,用于加载显示需要识别的图片,并将识别的结果显示在窗口中。
(1)设置模型存放路径
首先在代码中设置paddleocr训练模型的存放路径,代码如下。由于我们使用百度工程师已经训练好的模型,所以我们不用再编写具体的文字识别模型,直接使用即可。下面的代码分别表明了检测、识别和分类3个模型文件的存放路径。此处设置的是直接放置在当前工作目录下,若目录下不存在路径和模型,则程序在初次运行时会直接从官网上下载相应模型文件,并存放大指定路径中。
# 自定义模型存储路径 模型不存在时,会自动下载到以下路径中
det_model_path = './det_model' # 检测
rec_model_path = './rec_model' # 识别
cls_model_path = './cls_model' # 分类(2)实例化paddleocr对象
以下代码实例化了一个paddleocr对象。对象参数指明了是否启用方向分类、识别的文字类型、模型文件路径、是否使用GPU等。需要进一步说明的是,此处参数中选择不使用GPU,因为我们此处安装的paddleocr版本是CPU版。百度paddle官网中提供了多个GPU版本的paddleocr,使用GPU版本需要英伟达显卡支持,并安装英伟达对应显卡的CUDA驱动平台,其安装操作比较繁琐,且一般电脑显卡也不支持paddleocr所适配的版本。因此,此处直接使用了CPU版,其运行效率也可以接受。
# 初始化OCR实例
ocr = PaddleOCR(use_angle_cls=True, # 启用方向分类lang="ch", # 中文识别det_model_dir=det_model_path,rec_model_dir=rec_model_path,cls_model_dir=cls_model_path,use_gpu=False, # 是否使用GPUpage_num=0 # PDF页数选择
)(3)识别图像文字
完成图像文字识别只需调用对象的ocr()函数即可,参数说明如下:
-
image_path:这是一个字符串类型的参数,表示要进行文字识别的图像文件的路径。可以是本地文件系统中的绝对路径或相对路径。 -
cls=True:这个参数通常用于开启文本方向分类功能。有些图像中的文字可能存在不同的方向(如水平、垂直、倾斜等),开启该功能后,OCR 引擎会先对文字的方向进行分类识别,然后将文字调整到合适的方向再进行识别,从而提高识别的准确性。 -
result:这是一个变量,用于存储 OCR 识别的结果。结果的具体格式和内容取决于所使用的 OCR 库,一般会包含识别出的文字信息以及其在图像中的位置信息等。
程序识别的文字信息放置在word_info[1][0]中,此处直接提取出来用于显示。
result = ocr.ocr(image_path, cls=True)
strs = ''
# 解析并打印结果
for line in result:for word_info in line:text = word_info[1][0]confidence = word_info[1][1]# print(f"识别内容: {text} | 置信度: {confidence:.2f}")# print(text)strs = strs + text + '\n'3)程序运行结果
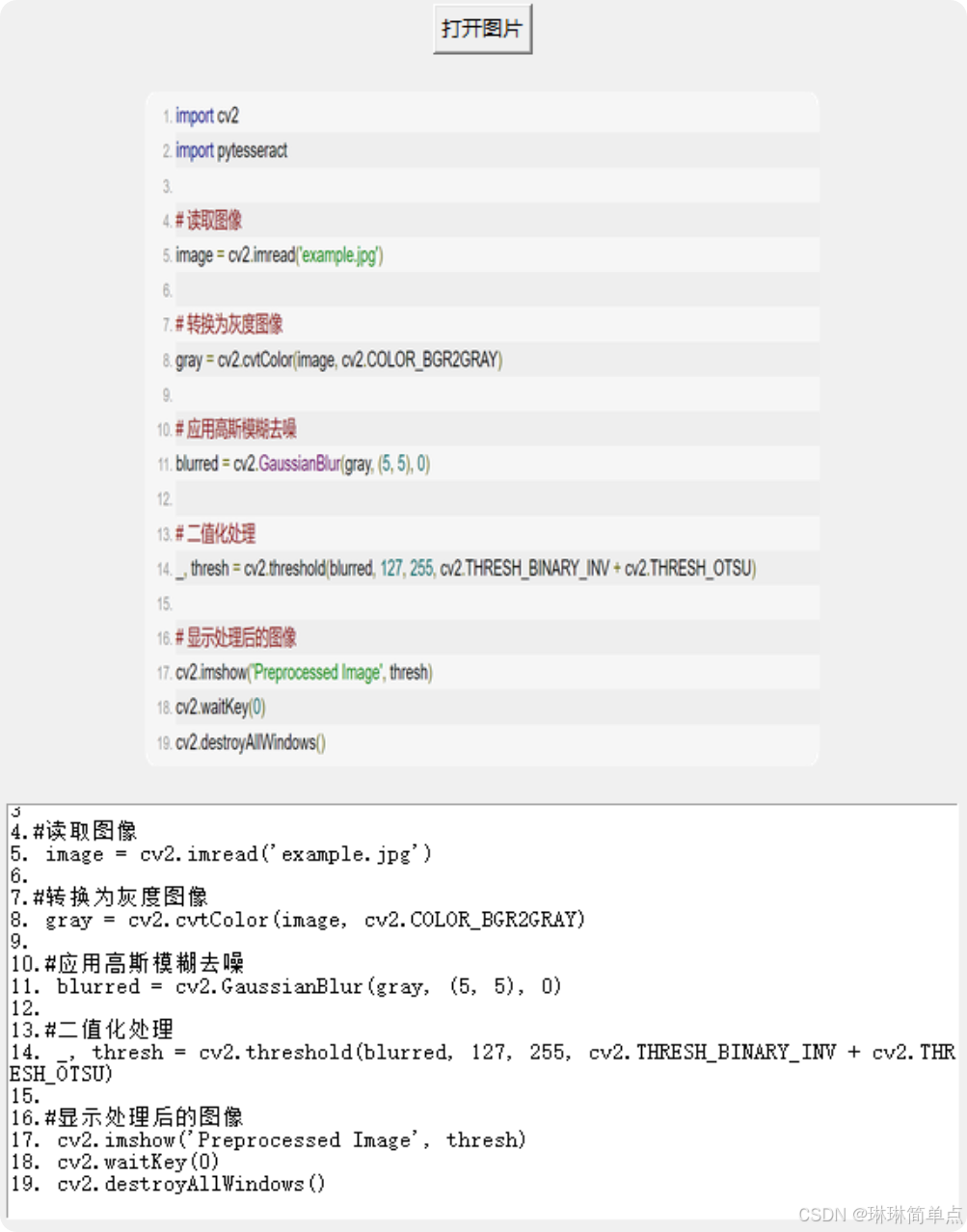
如下图所示,随意选取一张带中英文的图片,图中文字信息能够被全部准确识别,说明百度提供的paddleocr库效果很不错。
三、程序打包
pyinstaller是python提供的一个非常实用的打包工具,但直接使用该工具打包后的本项目exe程序并不能在其他电脑上运行,因为程序运行使用到了模型数据,所以需要对打包后的程序进行一些处理工作。网上也提供了很多其他打包paddleocr程序的方法,限于能力水平,均尝试不成功。下面是自己摸索出的一种可行的替代方式。
1)使用pyinstaller打包程序
在PyCharm终端窗口中执行pyinstaller --onefile --windowed --collect-all paddleocr wenzishibie.py,完成后我们会在当前工程目录下看到新建了一个dist文件夹,在该文件夹中有一个exe可执行程序wenzishibie.exe。
2)添加依赖和模型数据
如果直接执行上一步的wenzishibie.exe,程序会报错,缺少依赖库和模型数据,这时我们需要将模型数据和缺少的依赖库拷贝一份到dist文件夹中,如下图所示。正常情况下,pyinstaller命令会将程序所有依赖打包到wenzishibie.exe,但是此处确实仍然存在有依赖缺失的问题。mklml.dll文件就是缺失的动态库,我们在当前的虚拟环境中搜索到该文件,然后复制一份即可。此时我们在该文件夹下就可以直接运行wenzishibie.exe。
将dist文件夹所有内容直接拷贝到其他电脑后,也可以正常运行wenzishibie.exe程序。若需要将dist文件夹中的内容再次打包为一个exe可执行程序,可以使用Enigma Virtual Box打包工具,也可参见使用winrar打包exe程序方法。

四、需要注意的问题
1) 本项目的程序均是在新建的虚拟环境中编写的,因此所有依赖库的安装均应确保安装在了新的虚拟环境中,否则可能存在程序无法运行的问题。
2)在程序打包过程中,我们可以直接将模型数据文件夹拷贝到dist文件中,使其与可执行文件wenzishibie.exe在同一目录下,以确保程序运行时能找到模型文件,并可进一步将程序封装为一个可执行文件,是因为我们在程序代码实现中加载模型时使用的是相对路径(det_model_path = './det_model' ),程序运行时将直接从wenzishibie.exe所在路径下去查找模型文件。如果我们在代码中不使用此路径,则本文所介绍的程序打包方法将不适用,因为程序运行时将无法找到模型文件,除非在移植的电脑上将模型文件复制到代码指定路径下,但这样做失去了程序打包移植的意义。
五、总结
本文介绍了使用paddleocr库编写一个图像文字识别的简单程序,并通过在代码中的特殊处理,结合pyinstaller工具实现图像识别程序打包移植。使用paddleocr库进行文字识别开发简单高效,文字识别率准确率也很高。项目所使用的源代码和模型数据库可从此处下载,以作参考。