【自然语言处理(NLP)】长短期记忆网络(Long - Short Term Memory,LSTM)原理和代码实现(从零实现、Pytorch实现)
文章目录
- 介绍
- 长短期记忆网络(Long - Short Term Memory,LSTM)
- 结构
- 原理
- 候选记忆元
- 符号含义
- 公式含义
- 记忆元
- 符号含义
- 公式含义
- 隐状态
- 符号含义
- 公式含义
- 特点
- 应用
- 实现 LSTM
- pytorch实现
个人主页:道友老李
欢迎加入社区:道友老李的学习社区
介绍
**自然语言处理(Natural Language Processing,NLP)**是计算机科学领域与人工智能领域中的一个重要方向。它研究的是人类(自然)语言与计算机之间的交互。NLP的目标是让计算机能够理解、解析、生成人类语言,并且能够以有意义的方式回应和操作这些信息。
NLP的任务可以分为多个层次,包括但不限于:
- 词法分析:将文本分解成单词或标记(token),并识别它们的词性(如名词、动词等)。
- 句法分析:分析句子结构,理解句子中词语的关系,比如主语、谓语、宾语等。
- 语义分析:试图理解句子的实际含义,超越字面意义,捕捉隐含的信息。
- 语用分析:考虑上下文和对话背景,理解话语在特定情境下的使用目的。
- 情感分析:检测文本中表达的情感倾向,例如正面、负面或中立。
- 机器翻译:将一种自然语言转换为另一种自然语言。
- 问答系统:构建可以回答用户问题的系统。
- 文本摘要:从大量文本中提取关键信息,生成简短的摘要。
- 命名实体识别(NER):识别文本中提到的特定实体,如人名、地名、组织名等。
- 语音识别:将人类的语音转换为计算机可读的文字格式。
NLP技术的发展依赖于算法的进步、计算能力的提升以及大规模标注数据集的可用性。近年来,深度学习方法,特别是基于神经网络的语言模型,如BERT、GPT系列等,在许多NLP任务上取得了显著的成功。随着技术的进步,NLP正在被应用到越来越多的领域,包括客户服务、智能搜索、内容推荐、医疗健康等。
长短期记忆网络(Long - Short Term Memory,LSTM)
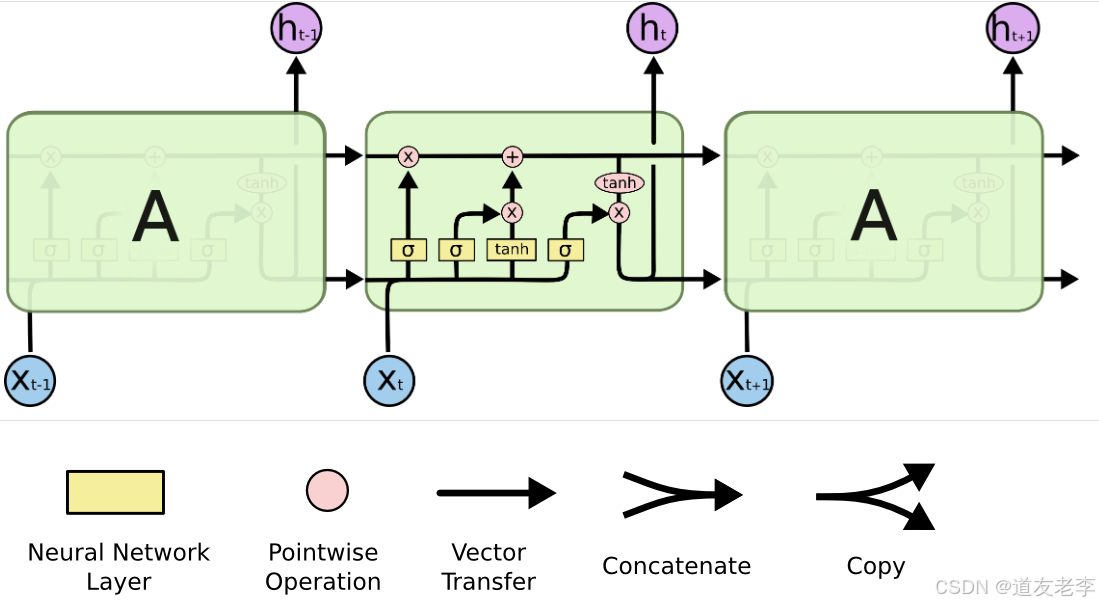
长短期记忆网络(Long - Short Term Memory,LSTM)是一种特殊的循环神经网络(RNN),专门为解决传统RNN中的长期依赖问题和梯度消失/爆炸问题而设计,在自然语言处理、时间序列分析等领域广泛应用。
结构
LSTM 由记忆单元(Memory Cell)、输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)构成。
- 记忆单元:可以看作是LSTM的“记忆体”,它能够保存信息并在不同时间步传递,允许LSTM学习长期依赖关系。
- 输入门:控制当前输入信息有多少能流入记忆单元。
- 遗忘门:决定记忆单元中哪些过去的信息将被遗忘。
- 输出门:确定记忆单元中的哪些信息将作为当前LSTM的输出。
原理
LSTM的设计灵感来源于计算机的逻辑门


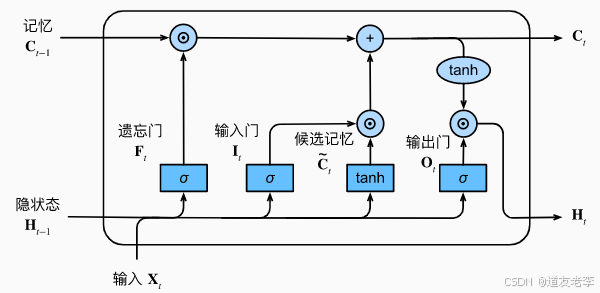
- 遗忘门操作:在时间步 t t t,遗忘门接收上一时刻隐藏状态 h t − 1 h_{t - 1} ht−1和当前输入 x t x_t xt,通过一个sigmoid函数输出一个介于0和1之间的值 f t f_t ft,该值表示记忆单元中每个元素的遗忘程度。 f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f\cdot[h_{t - 1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf),其中 W f W_f Wf是权重矩阵, b f b_f bf是偏置, [ h t − 1 , x t ] [h_{t - 1}, x_t] [ht−1,xt]表示将两者拼接, σ \sigma σ是sigmoid激活函数。
- 输入门操作:输入门首先通过sigmoid函数确定哪些新信息将被添加到记忆单元,记为 i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h_{t - 1}, x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi);同时,通过tanh函数生成一个候选值 C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t=\tanh(W_C\cdot[h_{t - 1}, x_t]+b_C) C~t=tanh(WC⋅[ht−1,xt]+bC) 。然后,新的记忆单元状态 C t C_t Ct通过遗忘门的输出 f t f_t ft和输入门的相关计算来更新: C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t = f_t * C_{t - 1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t,其中 ∗ * ∗表示元素相乘。
- 输出门操作:输出门通过sigmoid函数确定记忆单元的哪些部分将被输出, o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t - 1}, x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo) 。然后,隐藏状态 h t h_t ht通过 h t = o t ∗ tanh ( C t ) h_t = o_t * \tanh(C_t) ht=ot∗tanh(Ct)计算得出。
候选记忆元


符号含义
- 输入与隐藏状态:
- X t \mathbf{X}_t Xt:表示在时间步 t t t的输入矩阵,维度通常为 [ b a t c h _ s i z e , i n p u t _ s i z e ] [batch\_size, input\_size] [batch_size,input_size],其中 b a t c h _ s i z e batch\_size batch_size是批量大小, i n p u t _ s i z e input\_size input_size是每个样本的特征数量。
- H t − 1 \mathbf{H}_{t - 1} Ht−1:时间步 t − 1 t - 1 t−1的隐藏层输出矩阵,维度是 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size], h i d d e n _ s i z e hidden\_size hidden_size是隐藏层神经元数量,体现了LSTM的循环特性,即当前计算依赖于前一时刻隐藏状态。
- 权重矩阵和偏置项:
- W x c \mathbf{W}_{xc} Wxc:输入层到记忆单元的权重矩阵,维度为 [ i n p u t _ s i z e , h i d d e n _ s i z e ] [input\_size, hidden\_size] [input_size,hidden_size],负责将输入特征转换到记忆单元相关的空间。
- W h c \mathbf{W}_{hc} Whc:隐藏层到记忆单元的权重矩阵,维度是 [ h i d d e n _ s i z e , h i d d e n _ s i z e ] [hidden\_size, hidden\_size] [hidden_size,hidden_size],用于在前一时刻隐藏状态与当前输入共同作用时,对记忆单元相关计算进行变换。
- b c \mathbf{b}_{c} bc:记忆单元的偏置向量,维度为 [ h i d d e n _ s i z e ] [hidden\_size] [hidden_size] ,给记忆单元的计算增加可学习的偏置值。
- 激活函数:
- tanh \tanh tanh:双曲正切激活函数,将函数值映射到 - 1 到 1 之间,为计算引入非线性。
公式含义
在LSTM中,候选记忆元 C ~ t \tilde{C}_t C~t的计算是记忆单元更新过程的一部分。公式 C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \tilde{C}_t=\tanh(\mathbf{X}_t\mathbf{W}_{xc}+\mathbf{H}_{t - 1}\mathbf{W}_{hc}+\mathbf{b}_{c}) C~t=tanh(XtWxc+Ht−1Whc+bc)表示,先将当前时间步的输入 X t \mathbf{X}_t Xt与权重矩阵 W x c \mathbf{W}_{xc} Wxc相乘,同时将前一时间步的隐藏状态 H t − 1 \mathbf{H}_{t - 1} Ht−1与权重矩阵 W h c \mathbf{W}_{hc} Whc相乘,然后将这两个乘积结果相加,再加上偏置 b c \mathbf{b}_{c} bc,最后通过 tanh \tanh tanh激活函数对其进行非线性变换,得到候选记忆元 C ~ t \tilde{C}_t C~t 。
候选记忆元 C ~ t \tilde{C}_t C~t后续会与遗忘门、输入门的输出共同作用,用于更新记忆单元的状态,决定哪些新信息将被添加到记忆单元中。
记忆元


符号含义
- 记忆单元状态相关:
- C t \mathbf{C}_t Ct:表示在时间步 t t t的记忆单元状态矩阵,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size], b a t c h _ s i z e batch\_size batch_size是批量大小, h i d d e n _ s i z e hidden\_size hidden_size是隐藏层神经元数量。它存储了LSTM从过去时间步积累的信息。
- C t − 1 \mathbf{C}_{t - 1} Ct−1:时间步 t − 1 t - 1 t−1的记忆单元状态矩阵,维度同样为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],代表前一时刻记忆单元保存的信息。
- C ~ t \tilde{\mathbf{C}}_t C~t:候选记忆元矩阵,维度是 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],它是通过对当前输入和上一时刻隐藏状态进行变换和非线性激活得到的,包含了可能要添加到记忆单元的新信息。
- 门控向量:
- F t \mathbf{F}_t Ft:遗忘门向量,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],它通过sigmoid函数输出介于0和1之间的值,决定了 C t − 1 \mathbf{C}_{t - 1} Ct−1中每个元素的遗忘程度,0表示完全遗忘,1表示完全保留。
- I t \mathbf{I}_t It:输入门向量,维度是 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],同样由sigmoid函数生成,用于控制 C ~ t \tilde{\mathbf{C}}_t C~t中每个元素有多少将被添加到记忆单元中。
- 运算符号:
- ⊙ \odot ⊙:表示哈达玛积(Hadamard product),即两个相同维度的矩阵对应元素相乘。
公式含义
公式 C t = F t ⊙ C t − 1 + I t ⊙ C ~ t \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t - 1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t Ct=Ft⊙Ct−1+It⊙C~t描述了LSTM中记忆单元状态的更新过程:
- 首先, F t ⊙ C t − 1 \mathbf{F}_t \odot \mathbf{C}_{t - 1} Ft⊙Ct−1这部分运算,通过遗忘门 F t \mathbf{F}_t Ft对前一时刻记忆单元状态 C t − 1 \mathbf{C}_{t - 1} Ct−1进行选择性遗忘,丢弃不需要的历史信息。
- 然后, I t ⊙ C ~ t \mathbf{I}_t \odot \tilde{\mathbf{C}}_t It⊙C~t表示利用输入门 I t \mathbf{I}_t It对候选记忆元 C ~ t \tilde{\mathbf{C}}_t C~t进行筛选,确定要添加到记忆单元的新信息。
- 最后,将上述两部分结果相加,得到更新后的记忆单元状态 C t \mathbf{C}_t Ct,它融合了经过筛选的历史信息和新信息,为后续的隐藏状态计算和输出提供了重要的信息基础。
通过这样的更新机制,LSTM能够有效地处理长期依赖问题,有选择地保存和更新记忆单元中的信息。
隐状态

符号含义
- LSTM组件输出:
- H t \mathbf{H}_t Ht:表示在时间步 t t t的隐藏状态矩阵,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size], b a t c h _ s i z e batch\_size batch_size是批量大小, h i d d e n _ s i z e hidden\_size hidden_size是隐藏层神经元数量。它是LSTM在当前时间步的输出之一,会传递到下一时间步,也用于模型最终输出的计算等。
- O t \mathbf{O}_t Ot:输出门向量,维度为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],由sigmoid函数生成,取值介于0和1之间,用于控制记忆单元状态 C t \mathbf{C}_t Ct中信息有多少将被输出到隐藏状态。
- C t \mathbf{C}_t Ct:时间步 t t t的记忆单元状态矩阵,维度同样为 [ b a t c h _ s i z e , h i d d e n _ s i z e ] [batch\_size, hidden\_size] [batch_size,hidden_size],存储了LSTM从过去时间步积累的信息。
- 激活函数:
- tanh \tanh tanh:双曲正切激活函数,将函数值映射到 - 1 到 1 之间,对记忆单元状态进行非线性变换。
- 运算符号:
- ⊙ \odot ⊙:哈达玛积(Hadamard product),即两个相同维度的矩阵对应元素相乘。
公式含义
在LSTM中,隐藏状态 H t \mathbf{H}_t Ht的计算过程为:
首先,对记忆单元状态 C t \mathbf{C}_t Ct使用 tanh \tanh tanh激活函数进行非线性变换,将其值映射到 - 1 到 1 的范围,突出记忆单元中重要的信息特征。
然后,输出门向量 O t \mathbf{O}_t Ot与经过 tanh \tanh tanh变换后的记忆单元状态 tanh ( C t ) \tanh(\mathbf{C}_t) tanh(Ct)进行哈达玛积运算。由于 O t \mathbf{O}_t Ot的值介于0和1之间,这一运算过程实现了对 tanh ( C t ) \tanh(\mathbf{C}_t) tanh(Ct)中各元素的选择性输出,使得隐藏状态 H t \mathbf{H}_t Ht只包含记忆单元中被输出门允许输出的信息。
通过这样的计算方式,LSTM的隐藏状态能够根据当前任务需求,从记忆单元中筛选出合适的信息,为后续的预测、分类等任务提供有效的特征表示。
特点
- 有效处理长期依赖:通过门控机制,LSTM能选择性地保留或遗忘信息,缓解了传统RNN的长期依赖问题。
- 缓解梯度消失/爆炸:门控机制使得梯度在反向传播过程中更稳定,减少了梯度消失或爆炸的影响。
应用
- 自然语言处理:如机器翻译、文本生成、情感分析等任务,利用LSTM处理文本序列中的语义依赖。
- 语音识别:处理语音信号的时间序列信息,将语音转换为文本。
- 时间序列预测:例如股票价格预测、电力负荷预测等,挖掘时间序列中的长期模式和趋势。
实现 LSTM
有了前面的RNN实现经验,这里就直接上完整代码了
import torch
from torch import nn
import dltoolsbatch_size, num_steps = 32, 35
train_iter, vocab = dltools.load_data_time_machine(batch_size, num_steps)# 初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01def three():return (normal((num_inputs, num_hiddens)),normal((num_hiddens, num_hiddens)),torch.zeros(num_hiddens, device=device))W_xi, W_hi, b_i = three() # 输入门参数W_xf, W_hf, b_f = three() # 遗忘门参数W_xo, W_ho, b_o = three() # 输出门参数W_xc, W_hc, b_c = three() # 候选记忆元参数# 输出层W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q]for param in params:param.requires_grad_(True)return params# 初始化隐藏状态和记忆
def init_lstm_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device),torch.zeros((batch_size, num_hiddens), device=device))# 定义lstm主体结构
def lstm(inputs, state, params):[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params(H, C) = stateoutputs = []# 准备开始进行前向传播计算. for X in inputs:I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)C = F * C + I * C_tildaH = O * torch.tanh(C)Y = (H @ W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H, C)# 训练和预测
vocab_size, num_hiddens, device = len(vocab), 256, dltools.try_gpu()
# 可自己调整epoch和学习率
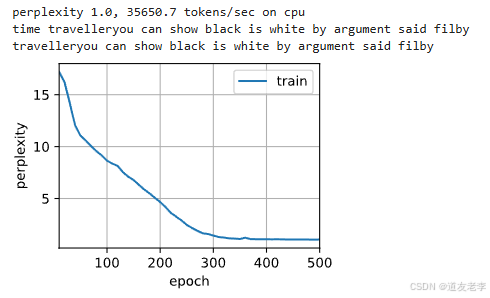
num_epochs, lr = 500, 1
model = dltools.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params, init_lstm_state, lstm)
dltools.train_ch8(model, train_iter, vocab, lr, num_epochs, device)




pytorch实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = dltools.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
dltools.train_ch8(model, train_iter, vocab, lr, num_epochs, device)