MySQL索引——让查询飞起来
文章目录
- 索引是什么??
- 硬件理解
- MySQL与存储
- MySQL 与磁盘交互基本单位
- 索引的理解
- B+ vs B
- 聚簇索引 VS 非聚簇索引
- 索引操作
- 创建主键索引
- 唯一索引的创建
- 普通索引的创建
- 全文索引的创建
- 查询索引
- 删除索引
在现代数据库应用中,查询性能是决定系统响应速度和用户体验的关键因素之一。MySQL作为最流行的关系型数据库之一,提供了强大的索引功能来优化查询性能。本文将深入探讨MySQL索引的工作原理、类型以及如何通过索引优化查询,让你的数据库查询飞起来。
索引是什么??
对应文章标题:让查询飞起来
显然索引就能让加快查询速度
首先我们知道MySQL的服务器本质就是在内存中的,对于数据库的CRUD操作,全部是在内存中进行的!对于索引也是这样的;
我们在下面做一个测试
我们先创建一个数据库,里面填充一个名为EMP的表,插入大量数据,我们发现耗时很久才插入完成

由于数据量太大,我们仅仅查看前十条
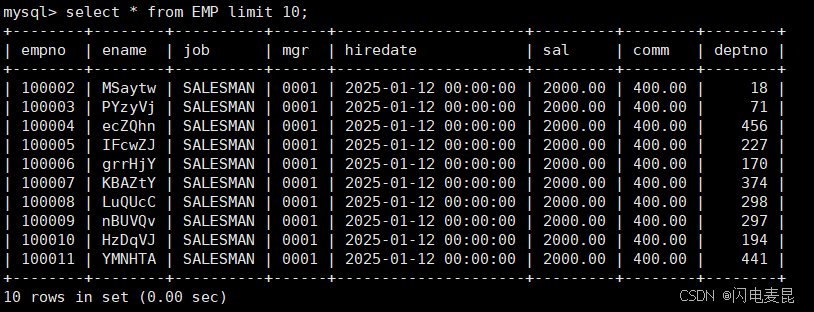
我们随便查询一条,发现时间好像有点久

这还是在本机一个人来操作,在实际项目中,如果放在公网中,假如同时有1000个人并发查询,那很可能就死机;
如何解决??
那就是本文所提到的索引;
- 解决方法,创建索引
当我们用下列SQL语句,对原表的empo列添加索引时,数据库底层就会为员工表中的数据记录构建特定的数据结构
alter table EMP add index(empno);
由于当前员工表中的数据量较大,因此建立索引时也需要花费较长时间

我们用同样的方法查询,可以看见时间非常短

原因:
常见的索引分为:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引(fulltext)
硬件理解
MySQL与存储
MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。磁盘是计算机中的一个机
械设备,相比于计算机其他电子元件,磁盘效率是比较低的。
我们看一个磁片,可以看到扇区的大小为512字节
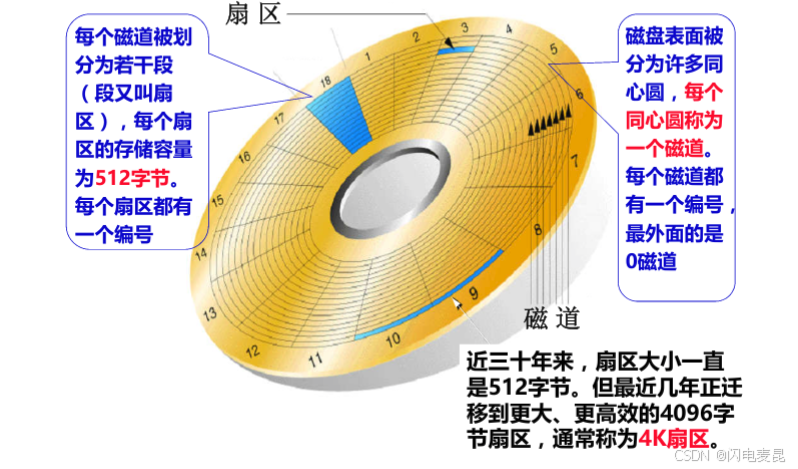
那么在系统软件上 IO一定是512字节吗?
并不是
- 如果操作系统直接使用硬件提供的数据大小进行交互,那么如果硬件发生变化,系统必须跟着变;
- 而且单次访问512字节还是有点小,这样的话读取同样的内容,单次访问小也就意味着访问的次数需要提高,即效率降低;
磁盘随机访问(Random Access)与连续访问(Sequential Access)
- 随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需
要作比较大的移动动作才能重新开始读/写数据; - 连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次
IO操作,这样的多个IO操作称为连续访问;
MySQL 与磁盘交互基本单位
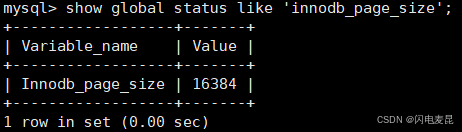
而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高
基本的IO效率, MySQL 进行IO的基本单位是 16KB
-
MySQL 中的数据文件,是以page为单位保存在磁盘当中的;
-
MySQL 的 CURD 操作,都需要通过计算,找到对应的插入位置,或者找到对应要修改或者查询的数据;
-
为了更高的效率,要尽可能的减少系统和磁盘IO的次数
索引的理解
为什么MySQL与磁盘交互的基本单位是Page
当我们要查询第一条内容时会进行一次IO,再次查询第三条内容时又会进行一次IO,此时已经IO两次;
但如果将其放在同一个Page下的话,查询第一条内容时,整个Page就会被放在缓冲池Buffer Pool中,后面再查询该Page中的内容时,就不用IO直接在Page中找,这样相当于只用了第一次查询的IO
我们无法保证下次要查询的内容在该Page中,但是由于局部性原理,很大概率下次的访问会在该Page中
- 局部性原理:大多数业务场景中,相邻数据(如同一表的连续记录)可能被同时访问
- 当需要某一行数据时,整个Page会被加载到内存,后续对同一Page内的数据访问无需再次触发磁盘I/O
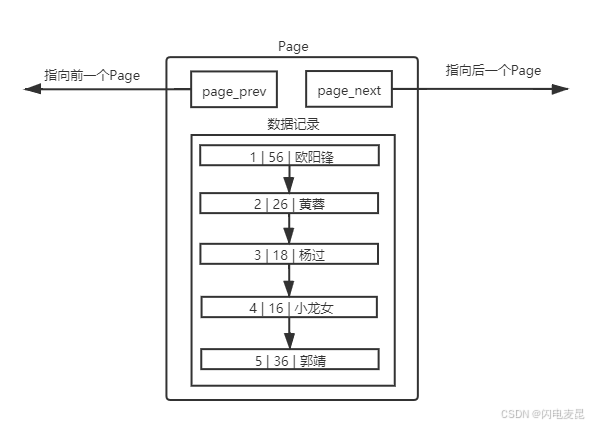
理解单个Page
MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要 先描述,在组织 ,我们目前可以简单理解
成一个个独立文件是有一个或者多个Page构成的
- 主键优化使数据的按序存储也是对查询的一种优化
- 正是因为有序,在查找的时候,从头到后都是有效查找,没有任何一个查找是浪费的
对于单个Page如果数据较多,线性遍历查找,对于最后一个数据来说并不友好;
所以我们在单个Page下创建一个目录,
也就是说对于1 2条数据我们放在目录1下,对于3 4条数据放在目录2下,也就是下图
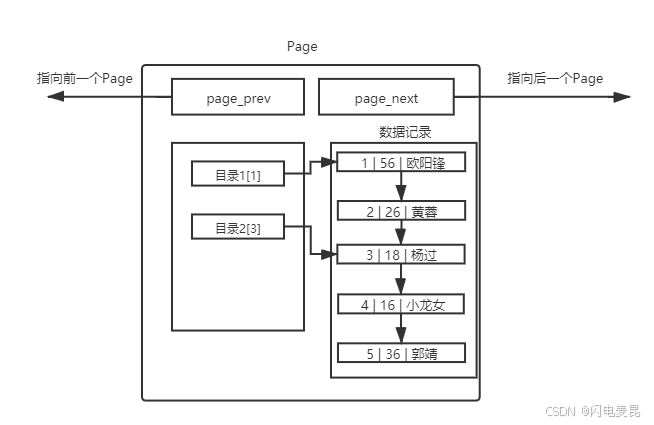
- 这也就对应了上述所说,主键的有序也是一种优化,如果不是有序的话,目录下的内容是混乱的,此时效率非常低
- 随着数据量不断增大,单个Page中无法存下所有数据,这时就需要用多个Page来存储数据
- 这时在查询数据时就需要,先遍历Page双链表确定目标数据在哪一个Page,然后再在该Page内部找到目标数据
多个Page
随着数据量不断增大,单个Page中无法存下所有数据,这时就需要用多个Page来存储数据
- 在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能
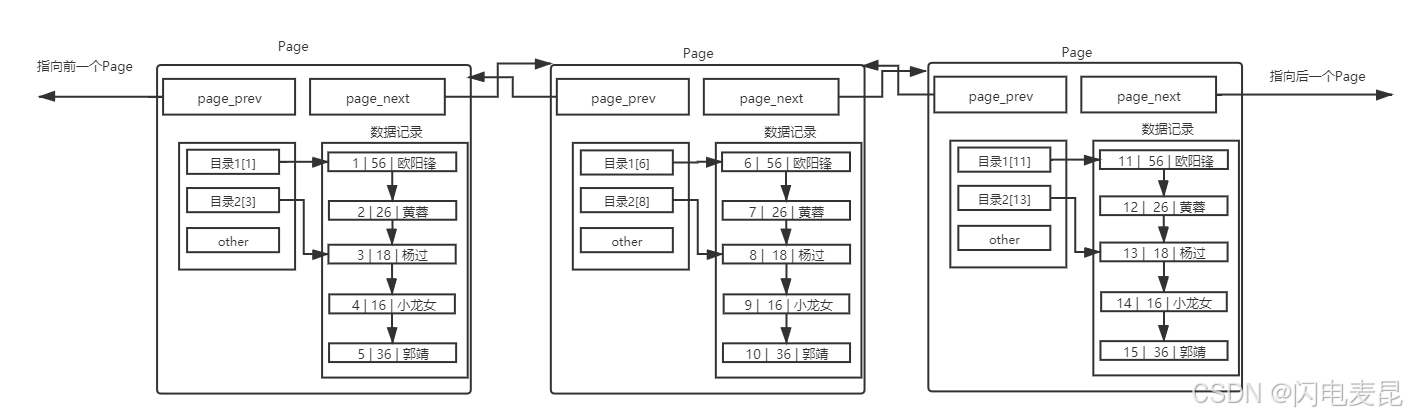
- 虽然在单个Page内部能够通过页内目录来快速定位数据,但在遍历Page双链表寻找目标Page时本质进行的还是线性遍历
- 这时可以给各个Page结构体也建立页目录,页目录中的每个目录项都指向一个Page,而这个目录项存放的就是其指向的Page中存放的最小数据的键值
- 在给各个Page结构体建立页目录后,在查询数据时就可以先通过遍历页目录找到目标数据所在的Page,然后再在该Page内部找到目标数据
所以我们给Page也带上目录
给Page也带上目录
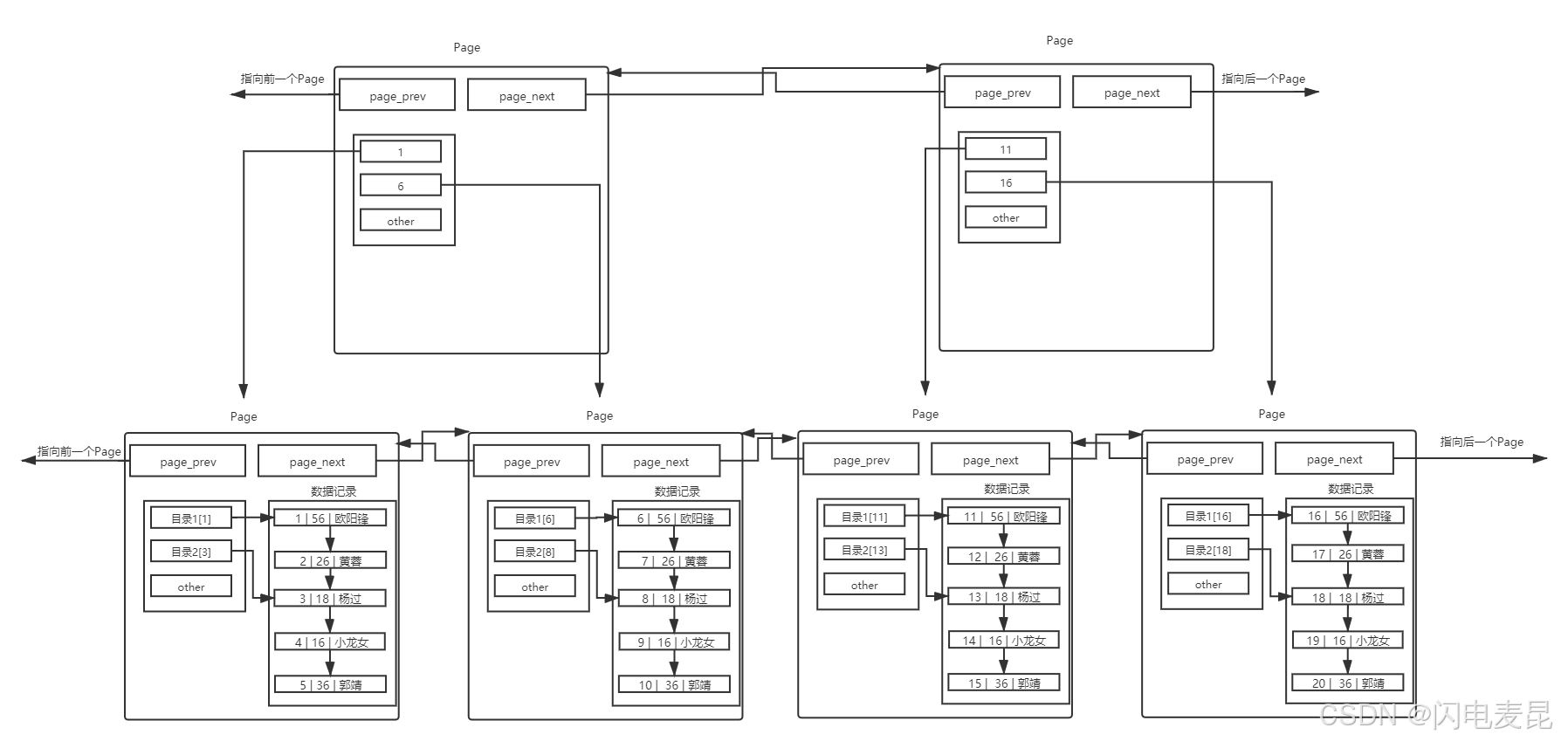
- 目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址
-
- 顶层的目录页少了,但是还要遍历啊
-
- 随着数据量不断增大,页目录的数量也会越来越多,这时在遍历页目录寻找目标Page时本质进行的还是线性遍历
结论:"套娃"——给目录页加一个目录
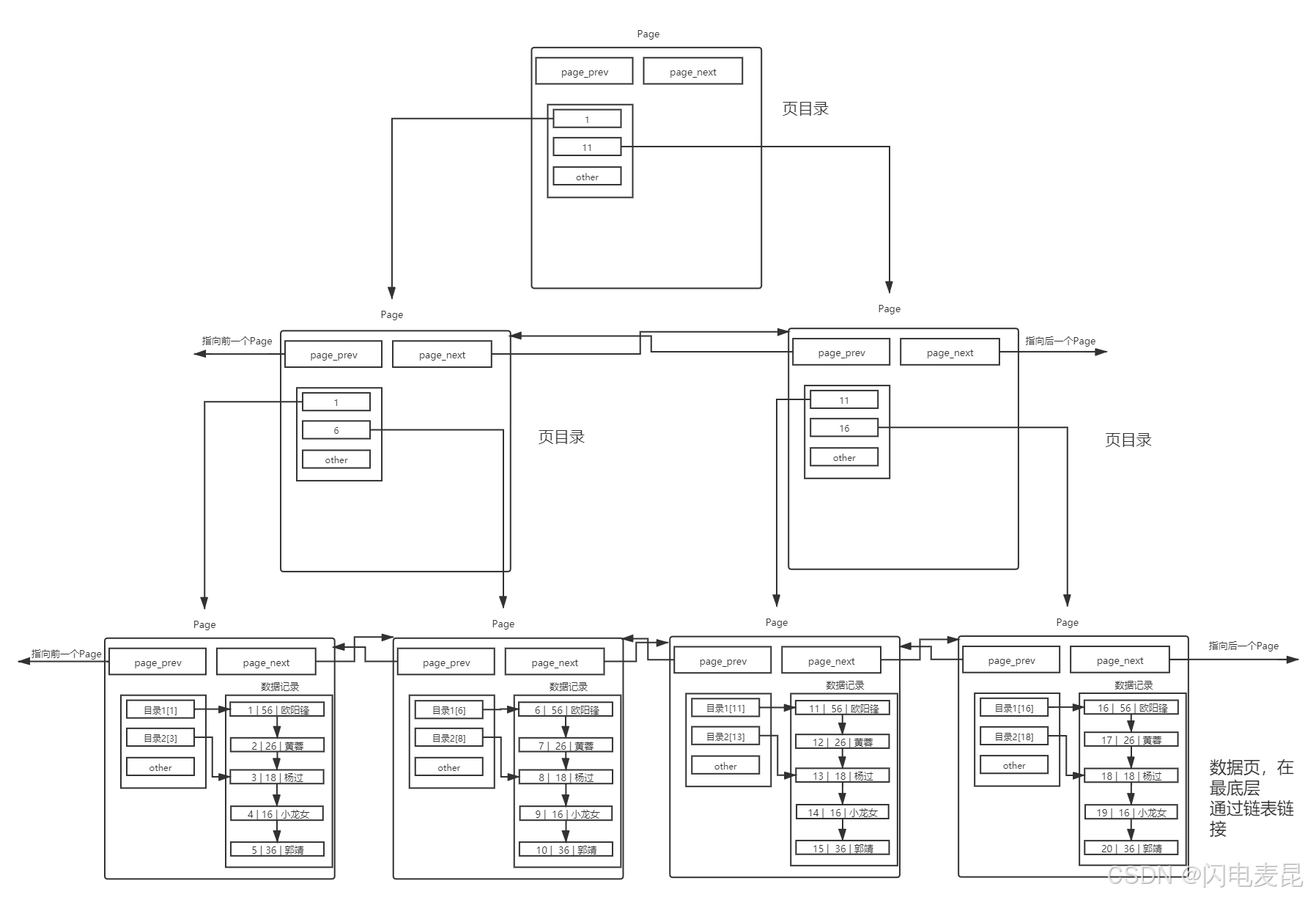
豁~~,这不就是B+树吗
这棵B+树就是InnoDB的索引结构
B+ vs B
B树
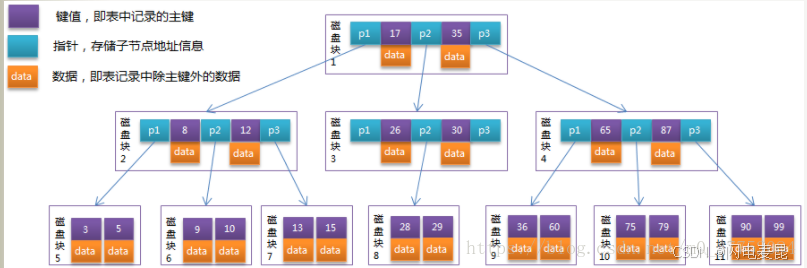
B+树

| - | B树 | B+树 |
|---|---|---|
| 数据存储位置 | 所有节点均可存储数据 | 仅叶子节点存储数据,内部节点为索引 |
| 叶子节点链接 | 无 | 叶子节点通过双向链表串联 |
| 树的高度 | 相对较高(相同数据量) | 相对较低 |
| 查询稳定性 | 可能在任何层级命中数据 | 必须查找到叶子节点 |
| 范围查询效率 | 低(需回溯父节点) | 高(链表直接遍历相邻叶子) |
| 冗余数据 | 无 | 键值在内部节点重复存储 |
| 适用场景 | 随机读写密集、数据离散访问 | 范围查询频繁、顺序扫描需求高 |
-
B树
- 每个节点(包括内部节点和叶子节点)均可存储数据
- 查询可能在任意层级终止(若命中内部节点)
-
B+树
- 仅叶子节点存储数据,内部节点仅存储键值作为索
- 叶子节点通过双向链表连接,支持高效顺序访问
- 所有查询必须走到叶子节点才能获取数据
查询性能
单次查询:B树更快,可能在内部节点提前命中
范围查询:B+树更快,通过叶子节点的链表直接遍历,无需回溯父节点,效率高
聚簇索引 VS 非聚簇索引
MyISAM 存储引擎-主键索引
MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM
表的主索引, Col1 为主键。
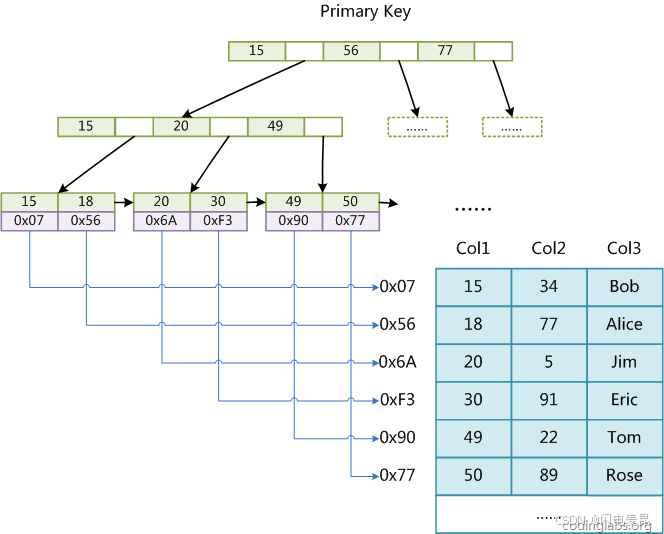
- 引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址
- MyISAM 这种用户数据与索引数据分离的索引方案,叫做非聚簇索引
- 所以, MyISAM 这种用户数据与索引数据分离的索引方案,叫做非聚簇索引
索引操作
创建主键索引
- 第一种方式
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));
- 第二种方式
- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));
- 第三种方式
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);
唯一索引的创建
- 第一种方式
-- 在表定义时,在某列后直接指定unique唯一属性。
create table user4(id int primary key, name varchar(30) unique);
- 第二种方式
-- 创建表时,在表的后面指定某列或某几列为unique
create table user5(id int primary key, name varchar(30), unique(name));
- 第三种方式
create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);
普通索引的创建
- 第一种方式
create table user8(id int primary key,name varchar(20),email varchar(30),index(name) --在表的定义最后,指定某列为索引
);
- 第二种方式
create table user9(id int primary key, name varchar(20), email varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引
- 第三种方式
create table user10(id int primary key, name varchar(20), email varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);
全文索引的创建
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)
)engine=MyISAM;
查询索引
- 第一种方法
show keys from 表名;
- 第二种方法
show index from 表名;
- 第三种方法
desc 表名;
删除索引
- 第一种方法,删除主键索引
alter table 表名 drop primary key;
- 第二种方法,其他索引的删除
alter table 表名 drop index 索引名;
- 第三种方法
drop index 索引名 on 表名;
索引创建原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引
- 不会出现在where子句中的字段不该创建索引