生存网络与mlr3proba
在R语言中,mlr3包是一个用于机器学习的强大工具包。它提供了一种简单且灵活的方式来执行超参数调整。
生存网络是一种用于生存分析的模型,常用在医学和生物学领域。生存分析是一种统计方法,用于研究事件发生的时间和相关因素对事件发生的影响。生存网络可以用来预测个体在给定时间点发生事件的概率,并分析影响事件发生的因素。
而mlr3proba是一个R语言包,提供了一套机器学习算法,可用于生存分析和预测。mlr3proba基于mlr3框架,提供了多种生存模型及其评估指标,方便用户进行生存分析的建模和评估。
通过结合生存网络和mlr3proba,可以使用生存网络模型来预测个体在给定时间点发生事件的概率,并使用mlr3proba提供的工具进行模型的训练、评估和选择最佳模型。这样可以更准确地预测个体的生存概率,并分析影响事件发生的因素。
主题与背景
本文是一篇关于在R语言环境中使用生存神经网络(survival networks)的高级演示文章。作者旨在回答读者关于如何在R中安装Python模块、使用特定的生存分析模型、调优这些模型以及比较不同模型性能的问题。文章假设读者已经了解生存分析、神经网络的基本概念以及常见的超参数、基本的机器学习方法如重采样和调优。
主要观点
目标读者
面向对生存神经网络感兴趣的R用户。
假设读者熟悉生存分析、神经网络和基本的机器学习方法。
主要内容
安装Python模块在R中:
使用install.packages和remotes::install_github安装必要的R包。
安装survivalmodels中的Python模块,如pycox和keras,通过sinstall_pycox和install_keras函数。
设置随机种子以确保结果可重复性,使用sset_seed函数。
使用survivalmodels和mlr3proba:
survivalmodels:包含多个神经网络模型,前五个使用reticulate连接Python的pycox包,后一个使用R的keras包。
mlr3proba:用于概率监督学习,包括生存分析。提供更全面的功能,如数据预处理和模型调优。
模型调优与数据预处理
调优:使用mlr3tuning包进行超参数配置和调优控制。
创建超参数搜索空间,使用paradox包。
定义自动调参器AutoTuner,设置调参策略。
数据预处理:使用mlr3pipelines包进行数据预处理。
使用管道操作符po进行独热编码和特征标准化。
模型训练与评估
实验设置:使用多个生存数据集进行训练和测试。
获取数据集,创建任务对象。
训练与调优:训练并调优神经网络模型。
应用自动调参器到各个学习器。
基准测试与比较:使用mlr3benchmark包进行模型比较。
设置交叉验证策略,添加其他基线模型(如Kaplan-Meier和Cox PH)。
聚合结果,使用Harrell’s C指数和Integrated Graf Score作为评价指标。
进行Friedman检验,绘制关键差异图。
结果分析
在玩具示例中,初步结论是Cox PH表现最佳,DeepHit表现最差。
通过mlr3benchmark进一步详细比较模型结果,发现没有显著差异。
总结
本文通过一系列步骤展示了如何在R环境中利用mlr3家族的包来安装、使用、调优和比较生存神经网络模型。核心观点在于,mlr3接口简化了从生存模型选择、调优到比较的整个过程,使得研究人员能够更高效地探索和应用这些先进的生存分析技术。尽管示例中的模型由于数据集较小而表现不佳,但所展示的方法和工具为实际应用提供了有价值的指导。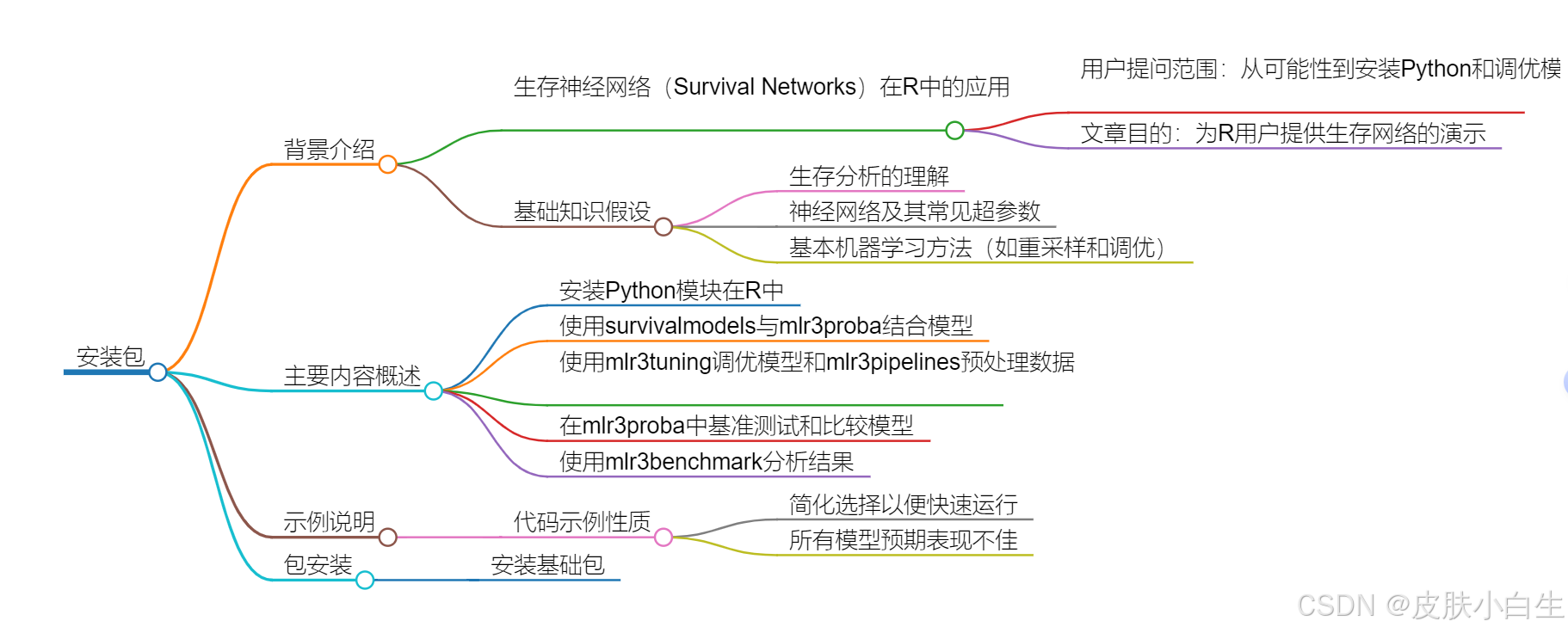
mlr3家族的包之间存在紧密的关联和协作,共同构成了一个完整的机器学习生态系统。以下是基于文档内容对mlr3家族包之间关系的总结:
-
mlr3:这是核心包,提供了基本的机器学习框架和接口,包括任务、学习器和评估方法。
-
mlr3proba:这是mlr3的一个扩展包,专注于概率监督学习,特别是生存分析。它提供了专门用于生存分析的任务和学习器。
-
mlr3extralearners:这个包包含了额外的学习器,可以与mlr3和其他扩展包一起使用,增加了可用模型的数量。
-
mlr3tuning:这个包提供了模型调参的功能,允许用户通过不同的搜索策略(如随机搜索)来优化模型的超参数。
-
mlr3pipelines:这个包提供了数据预处理的功能,通过管道操作符(%>>%)连接不同的预处理步骤,如编码和标准化。
-
mlr3benchmark:这个包用于模型的基准测试和比较,提供了统计检验和可视化工具来分析不同模型的表现。
这些包之间的关系可以概括为:
-
mlr3作为核心框架,其他扩展包在其基础上提供特定功能。
-
mlr3proba扩展了mlr3,提供了生存分析相关的功能。
-
mlr3extralearners增加了更多的学习器,丰富了模型选择。
-
mlr3tuning提供了调参功能,帮助优化模型性能。
-
mlr3pipelines提供了数据预处理功能,确保数据适合模型训练。
-
mlr3benchmark提供了模型比较和结果分析的功能,帮助用户选择最佳模型。
这是一个高级演示,我将假设你知道:i)什么是生存分析; ii)什么是神经网络(以及常见的超参数); iii)基本的机器学习(ML)方法,如重新排序和调整。如果需要,我很乐意在以后的文章中全面介绍这些主题。
In this article we will cover how to: i) install Python modules in R; ii) use models implemented in survivalmodels(Sonabend 2020) with mlr3proba(Sonabend et al. 2021) ; iii) tune models with mlr3tuning(Lang, Richter, et al. 2019) and preprocess data with mlr3pipelines(Binder et al. 2019); iv) benchmark and compare models in mlr3proba; v) analyse results in mlr3benchmark(Sonabend and Pfisterer 2020). Many of these packages live in the mlr3 family and if you want to learn more about them I’d recommend starting with the mlr3book(Becker et al. 2021a).
在本文中,我们将介绍如何:i)在R中安装Python模块; ii)使用带有mlr 3 proba(Sonabend et al.2021)的survivalmodels(Sonabend 2020)中实现的模型; iii)使用mlr 3 tuning(Lang,Richter,et al.2019)调优模型,并使用mlr 3 pipelines(Binder et al.2019)预处理数据; iv)在mlr 3 proba中对模型进行基准测试和比较; v)在mlr3benchmark中分析结果(Sonabend and Pfisterer2020)。这些软件包中的许多都存在于mlr 3家族中,如果你想了解更多关于它们的信息,我建议你从mlr 3book开始(Becker et al.2021a)。
The code in this demonstration is a ‘toy’ example with choices made to run the code quickly on my very old laptop, all models are expected to perform poorly.
这个演示中的代码是一个“玩具”示例,选择在我非常旧的笔记本电脑上快速运行代码,所有型号的性能都很差。
Let’s get deep learning! 让我们开始深度学习吧!
Installing Packages 安装包
We will be using several packages, to follow along make sure you install the following:
我们将使用几个软件包,沿着确保您安装以下软件包:
install.packages(c("ggplot2", "mlr3benchmark", "mlr3pipelines", "mlr3proba", "mlr3tuning", "survivalmodels"))
remotes::install_github("mlr-org/mlr3extralearners")I have installed the following versions:
我已经安装了以下版本: