JAVA:HashMap在1.8做了哪些优化的详细解析
1、简述
HashMap 是 Java 中最常用的数据结构之一,它以键值对的形式存储数据,允许快速的插入、删除和查找操作。在 JDK 1.8 之前,HashMap 主要是基于数组加链表的结构实现的。然而,在面对大量哈希冲突时(即多个键的哈希值相同时),链表可能会变得非常长,导致查询效率从 O(1) 退化为 O(n)。为了优化这种情况,JDK 1.8 对 HashMap 进行了几个重要的改进,主要包括引入红黑树(Red-Black Tree)和哈希算法的改进。本文将详细讲解这些优化及其背后的设计思路。
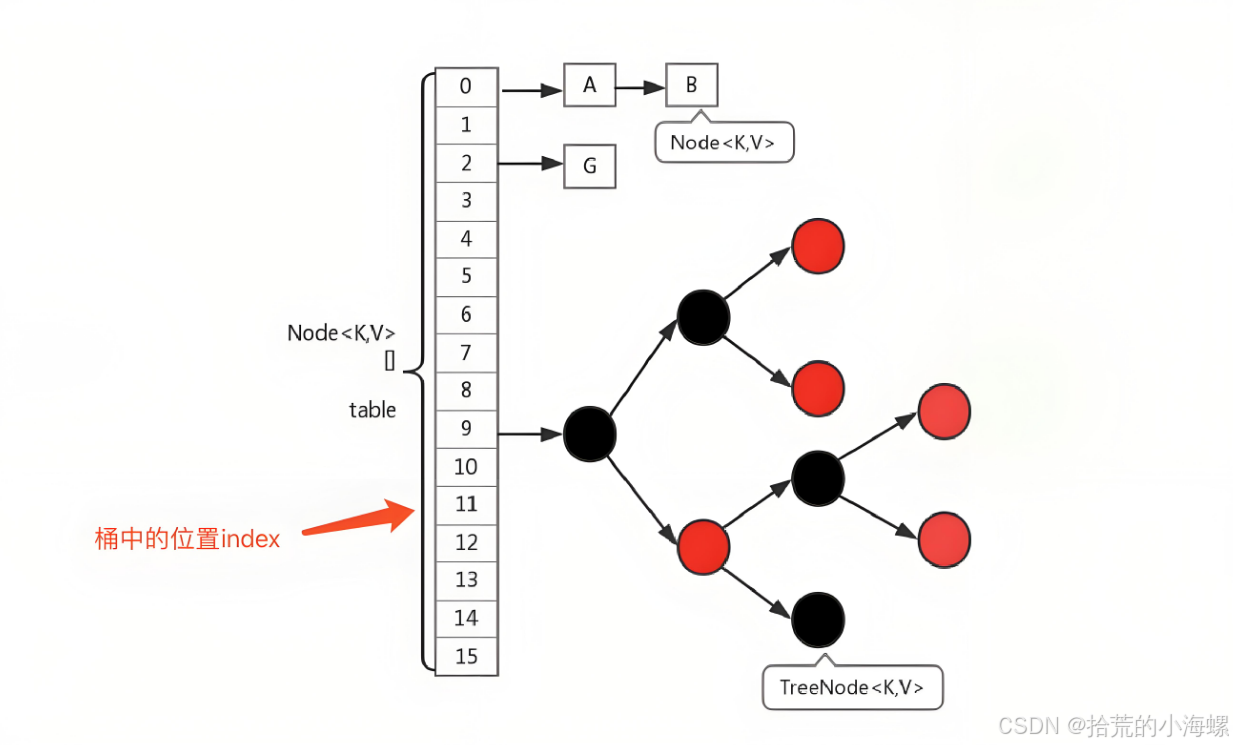
2、JDK 1.8 之前的 HashMap 实现
在 JDK 1.8 之前,HashMap 使用数组和链表的组合结构。当我们插入一个元素时,它首先通过键的哈希值确定数组中的位置(称为桶),如果该位置存在其他元素,新的键值对将被追加到该位置的链表上。
这种结构的优点是简单易实现,且在键分布均匀的情况下性能很好。但在极端情况下,如果大量的键映射到了同一个位置(哈希冲突),链表的长度会增长,查询时间复杂度会从 O(1) 退化到 O(n),这对性能影响较大。
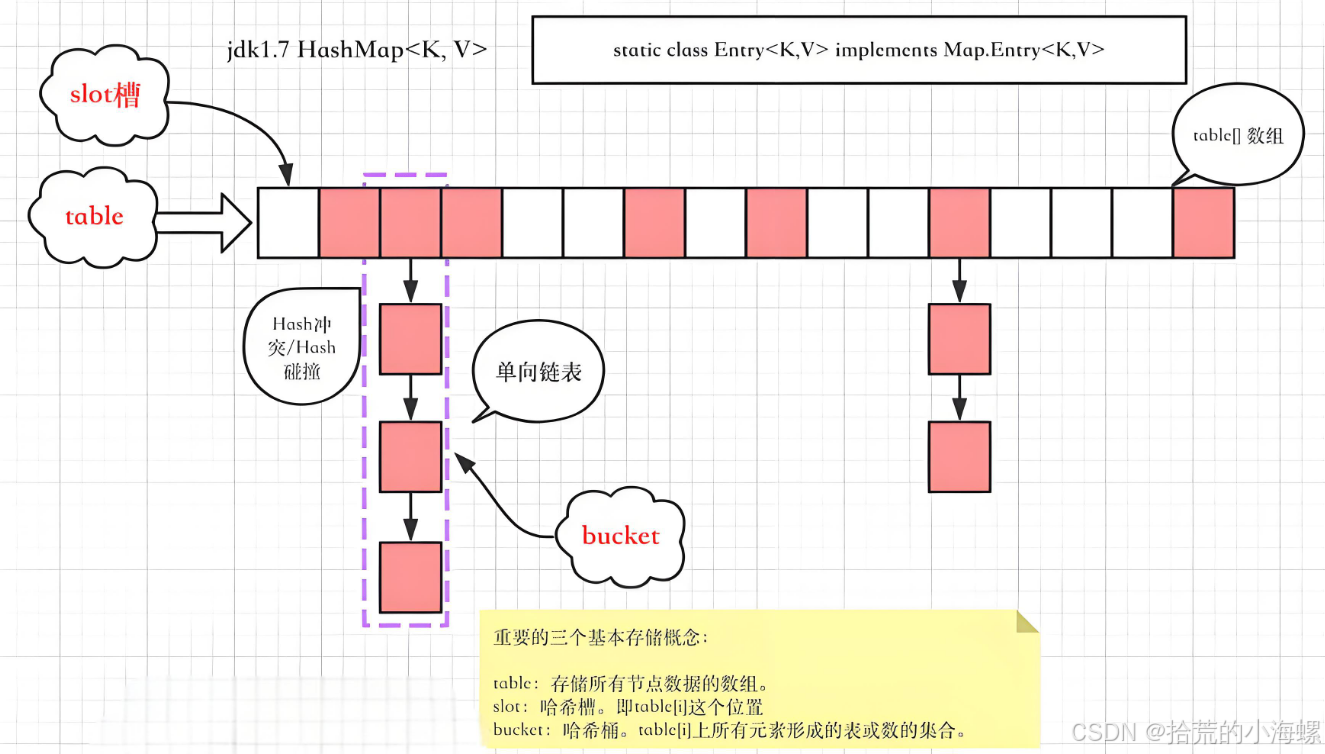
3、JDK 1.8 对 HashMap 的优化
3.1 引入红黑树(Red-Black Tree)
为了优化链表查询的效率,JDK 1.8 引入了红黑树。当链表的长度超过一定阈值(默认是 8)时,链表会自动转换为红黑树。红黑树是一种自平衡二叉搜索树,查找、插入、删除操作的时间复杂度为 O(log n),因此大幅提升了查询性能。
当链表中的元素少于一定数量(默认是 6)时,红黑树会被转换回链表。这种转换机制在哈希冲突较严重时显著提升了 HashMap 的性能,同时也保证了在数据量较少时的内存开销不会过高。
// HashMap 中的链表转红黑树逻辑示例
if (binCount >= TREEIFY_THRESHOLD) {treeifyBin(tab, hash);
}
- TREEIFY_THRESHOLD:定义了链表转化为红黑树的阈值,默认值为 8。
- treeifyBin:负责将链表转化为红黑树。
3.2 动态扩容优化
HashMap 的容量是动态扩展的,当哈希表中的元素数量超过当前容量的 75% 时,会触发扩容操作。在 JDK 1.8 之前,扩容需要重新计算每个键的哈希值并分配到新的位置。JDK 1.8 优化了扩容逻辑,通过更高效的方式重新分配元素。
扩容时,原数组长度翻倍,每个元素要么保持在原位置,要么移动到新的索引位置。通过与新的容量进行简单的按位与运算,JDK 1.8 能快速确定元素在新数组中的位置,从而避免重新计算哈希值,提升了扩容的效率。
// HashMap 扩容时的元素迁移逻辑
int idx = e.hash & (newCapacity - 1);
3.3 改进的哈希算法
在 JDK 1.8 中,HashMap 采用了更好的哈希扰动函数(hash function),目的是减少哈希冲突的发生。通过对哈希值进行一系列位运算,使得高位和低位都能影响最终的数组索引,减少了低质量哈希函数带来的冲突问题。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这一优化主要是通过异或操作,将高位和低位的信息混合在一起,以提高哈希值的随机性,进而降低哈希冲突的概率。
4、优化的性能影响
JDK 1.8 的这些改进显著提升了 HashMap 在大数据量、高冲突场景下的性能:
- 在链表转换为红黑树后,查找性能从 O(n) 提升为 O(log n),尤其在高冲突情况下,性能提升明显。
- 动态扩容时避免了重复计算哈希值,扩容效率得到了提升。
- 改进的哈希算法进一步减少了哈希冲突的概率,提高了哈希表的整体性能。
以下是一个简单的示例代码,展示了 HashMap 在 JDK 1.8 中的工作机制:
import java.util.HashMap;public class HashMapDemo {public static void main(String[] args) {HashMap<String, Integer> map = new HashMap<>();// 插入元素,触发红黑树转换for (int i = 0; i < 20; i++) {map.put("key" + i, i);}// 输出 HashMap 内容map.forEach((key, value) -> System.out.println(key + ": " + value));// 扩容前后检查性能System.out.println("Size before expansion: " + map.size());for (int i = 20; i < 50; i++) {map.put("key" + i, i);}System.out.println("Size after expansion: " + map.size());}
}
5、总结
JDK 1.8 对 HashMap 的优化主要集中在两个方面:提高哈希冲突情况下的查找效率和优化扩容过程。通过引入红黑树结构,HashMap 能够在面对大量哈希冲突时依然保持高效的查询性能;而动态扩容的优化则减少了不必要的哈希值重计算操作。这些优化使得 HashMap 在 JDK 1.8 中性能更加稳定和高效,特别是在大数据量的高并发环境中,表现尤为出色。
这也是为什么在性能敏感的系统中,升级到 JDK 1.8 后 HashMap 的表现更加优越的原因。希望这篇文章能帮助你更好地理解这些优化的实现原理,并在实际开发中加以应用。