4D LUT: Learnable Context-Aware 4D LookupTable for Image Enhancement
摘要:图像增强旨在通过修饰色彩和色调来提高照片的审美视觉质量,是专业数码摄影的必备技术。 近年来,基于深度学习的图像增强算法取得了可喜的性能并越来越受欢迎。 然而,典型的努力尝试为所有像素的颜色转换构建统一的增强器。 它忽略了对照片来说很重要的不同内容(例如天空、海洋等)之间的像素差异,导致结果不令人满意。 在本文中,我们提出了一种新颖的可学习上下文感知 4 维查找表(4D LUT),它通过自适应学习照片上下文来实现每个图像中不同内容的内容相关增强。 特别是,我们首先引入一个轻量级上下文编码器和一个参数编码器来分别学习像素级类别的上下文图和一组图像自适应系数。 然后,通过系数整合多个基础4D LUT来生成上下文感知4D LUT。 最后,通过四线性插值将源图像和上下文映射输入融合上下文感知 4D LUT 中,即可获得增强图像。 与相机成像管道系统或工具中通常使用的传统3D LUT(即RGB映射到RGB)相比,4D LUT(即RGBC(RGB+Context)映射到RGB)可以更精细地控制具有不同颜色的像素的颜色变换。 每个图像中的内容,即使它们具有相同的 RGB 值。 实验结果表明,我们的方法在广泛使用的基准测试中优于其他最先进的方法。
I. INTRODUCTION
高精度传感器设备的最新发展见证了低级计算机视觉领域和数字摄影的快速发展。 然而,由于光照、天气、相机传感器、摄影师技巧等因素的影响,拍摄的数码照片质量仍然较低。 图像增强作为一种提高色彩、对比度、饱和度、亮度和动态范围的图像处理技术,可以显着提高照片的审美视觉质量。 与没有专业技能和经验的手动照片修饰相比,图像增强算法可以自动生成满足视觉审美的赏心悦目的照片。 它可以配备在智能手机、数码单镜反光(DSLR)相机和专业级软件(例如Photoshop、Lightroom)中,以提供专业的修饰效果,具有广泛的应用前景[24]、[33]、[35]。
传统的图像增强方法采用手工制作的描述符或滤波器,通过输入低质量的输入图像来调整图像的视觉质量。 手工制作的全局描述符(例如,直方图均衡[41]、颜色校正[27]等)只能用于通过建立颜色映射关系来粗略地改变整个图像的色调,而可选择的局部滤波器(例如, 拉普拉斯滤波器[1]、引导滤波器[10]等)可以根据内容差异精细调整图像的视觉质量。 例如,属于自然风景、人像、古建筑等的像素应根据其内容的差异采用不同的局部滤镜。 然而,这种传统的手动调整依赖于专业的图像修图技巧,并且逐个像素地修图图像既耗时又不够实用。
受益于深度学习的进步,基于学习的图像增强算法正在快速发展[5],[42]。 MIT-Adobe FiveK数据集[2]提出了一个经过专家修饰的数据集,包含5000个自然景观图像对,这是第一个为整个领域建立基准的数据集。 此外,为了促进这项重要且高可见度的任务,PPR10K [23]提出了一个更大规模的肖像照片修饰数据集,其中每张肖像都由三位具有专业经验的专家分别修饰。
典型的基于学习的算法可以分为三个主要范例。 基于强化学习的方法[12]、[32],图像到图像的翻译方法[4]、[9]、[26]和基于物理建模的方法[5]、[37]、[29]、 [30],[46]。 其中,基于强化学习的方法[12]、[32]试图解耦整个过程,并通过逐步修饰过程增强图像。 图像到图像的转换方法[4]、[9]、[26]尝试直接通过神经网络建立从输入到增强输出的映射。 该方法可以通过端到端的训练方式产生全局优化的结果。 然而,这些算法缺乏可解释性和可靠性,就像一个“黑匣子”,而且它们还消耗大量的计算成本,牺牲了它们在实际应用中的有效性。 为了解决这些现有方法的局限性,另一类基于物理建模的方法 [5]、[37]、[29]、[30]、[46] 尝试使用人类可解释的物理模型(例如 Retinex 理论[20],双边过滤[36]等来增强图像。)。 这些方法通常采用两步解决方案,包括1)根据提出的物理模型和假设预测相关物理系数,2)通过物理理论调整原始像素以形成增强图像。 这些努力不仅无法区分不同内容变换的物理系数,而且还导致难以以端到端的训练方式进行学习。 因此,基于物理模型的方法没有提供足够的增强能力。
最近,一些优秀的作品[23]、[46]、[38]提出通过改进数字图像处理中的基本物理模型3D查找表来增强图像。 这些方法试图在增强过程上花费更少的运行时间,并专注于学习统一的增强器,以实现增强结果的所有区域的全局总体平均值。 虽然增强结果可以实时获得,但缺乏精细控制每幅图像中不同内容的像素颜色变换的能力,只能获得全局次优的结果。 此问题严重限制了增强图像的色彩丰富度,并且无法通过 3D 查找表来处理。 例如,如图1(a)所示,图像中的天空(由橙色表示)和海洋(由蓝色表示)(即使具有相同的RGB值)也应该通过不同的变换进行调整,以变得更蓝和更绿 分别,而不是平等对待。 直观上,自然风景和肖像的内容应该分别具有高色彩对比度和亮度,而古代建筑则需要较低的色温和额外的光学效果来描述其历史。

基于上述观察和动机,我们提出了一种新颖的可学习上下文感知4D查找表(4D LUT),它可以在不显着增加计算成本的情况下实现内容相关的图像增强,从而实现更好的视觉效果(如图1(c)所示)。 如图1(b)所示,4D LUT通过引入额外的上下文维度将3维查找表扩展到4维空间,其中4D LUT的输入索引(即RGBC)随上下文映射而变化, 增加了4D LUT的色彩增强能力,可以更精细地控制色彩变换和更强的图像增强。 具体来说,如图2所示,它包括四个密切相关的组件。 1)我们提出了一种上下文编码器,通过端到端学习生成上下文映射。 上下文图根据内容差异表示图像中的像素级类别,可以将图像从 RGB 扩展到 RGBC。 2)参数编码器,用于通过端到端学习生成一组系数。这些系数可以根据输入图像自适应地改变,以帮助最终的上下文感知 4D LUT 生成。 3)基于上面获得的多个预定义的可学习基础4D LUT和系数,我们提出了一种跨越不同颜色空间的4D LUT融合模块,并将它们集成为最终的具有更强增强能力的上下文感知4D LUT。 4)我们建议使用四线性插值,它可以将输入图像和上下文映射转换为四维空间索引,以输入到上下文感知的4D LUT中,最后在插值操作后输出增强的图像。 与传统的 3D LUT(即 RGB 映射到 RGB)相比,上下文感知 4D LUT(即 RGBC 映射到 RGB)的设计鼓励采用内容相关的方式来实现对颜色转换的更精细控制,从而增强像素的颜色 输入图像到增强图像。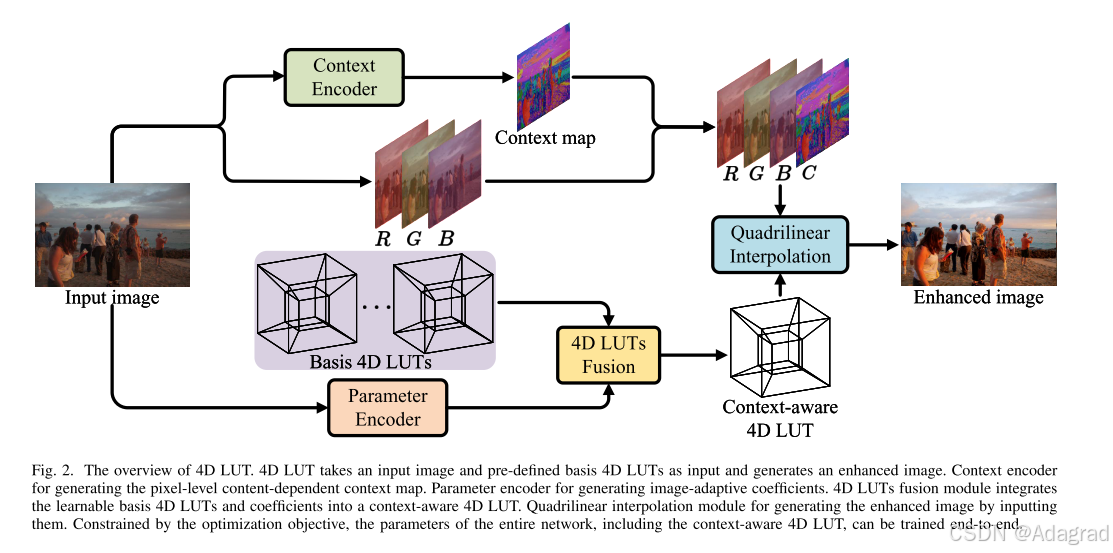
我们的贡献总结如下:
•据我们所知,我们是第一个将查找表架构扩展到四维空间并实现与内容相关的图像增强而不会显著增加计算成本的人。更具体地说,我们提出了一个可学习的上下文感知四维查找表(4D LUT),它由上下文编码器、参数编码器、四维LUT融合和四线性插值四个密切相关的组件组成。
•广泛的实验表明,所提出的4D LUT可以获得更准确的结果,并在三个广泛使用的图像增强基准中显著优于现有的SOTA方法。
本文的其余部分组织如下。第二节对相关工作进行了回顾。第三节详细阐述了所提出的上下文感知4D LUT。实验评估、分析和烧蚀研究在第四节中进行。相关参数和组件的讨论在第五节中进行。最后,我们在第六节中总结这项工作。
我们的贡献总结如下:•据我们所知,我们是第一个将查找表架构扩展到四维空间并实现与内容相关的图像增强而不会显著增加计算成本的人。更具体地说,我们提出了一个可学习的上下文感知四维查找表(4D LUT),它由上下文编码器、参数编码器、四维LUT融合和四线性插值四个密切相关的组件组成。•广泛的实验表明,所提出的4D LUT可以获得更准确的结果,并在三个广泛使用的图像增强基准中显著优于现有的SOTA方法。本文的其余部分组织如下。第二节对相关工作进行了回顾。第三节详细阐述了所提出的上下文感知4D LUT。实验评估、分析和烧蚀研究在第四节中进行。相关参数和组件的讨论在第五节中进行。最后,我们在第六节中总结这项工作。
II. RELATED WORK
在本节中,我们首先简要回顾了传统的图像增强算法,然后回顾了最近流行的基于深度学习的算法研究。
A. Traditional Algorithms
传统的图像增强方法通过使用手工制作的全局描述符和局部滤波器来提高图像的视觉质量。例如,颜色校正[27]和颜色直方图均衡化[41]通过建立颜色映射关系来调整图像颜色。局部拉普拉斯滤波器[1]和引导滤波器[10]通过细节平滑/锐化等操作增强图像的视觉质量。然而,只有经验丰富的专家才能使用这些手工制作的特征描述符或过滤器,而且它们在时间上很昂贵。
B. Learning-based Algorithms
近年来,基于学习的图像增强算法得到了迅速发展。这些主要算法可以分为三种范式。基于强化学习的方法,图像到图像的翻译方法,以及基于物理建模的方法。
1)基于强化学习的方法:基于强化学习[12]、[32]、[44]、[19]的增强方法,试图通过模拟人类一步一步的修图过程,将整个过程解耦,逐步提高图像的视觉质量。典型地,白盒[12]提出将图像增强过程解耦为一系列合适的参数。并且使用深度强化学习方法来学习在当前状态下下一步采取什么行动的决策。扭曲和恢复[32]将颜色增强过程转换为马尔可夫决策过程,其中动作定义为全局颜色调整操作。然后训练智能体学习最优的全局增强动作序列。深度曝光[44]和UIE[19]采用类似的强化学习策略,以对抗的方式学习未配对的光增强模型,严重牺牲了效率。
2)图像到图像的转换方法:图像到图像的转换增强方法[14]、[47]、[3]、[25]、[4]、[45]、[15]、[26]将图像增强视为图像到图像的转换问题,试图通过卷积网络学习输入图像与增强图像之间的映射关系。具有代表性的是,随着生成对抗机制[6]的普及,已有的一些作品[13]、[47]、[25]使用残差网络[11]进行风格迁移和增强未配对图像。Pix2Pix[14]研究了条件对抗网络作为图像到图像转换问题的通用解决方案,并学习了一个损失函数来训练从输入图像到输出图像的映射。MIEGAN[31]提出了一种多模块级联生成网络和一种自适应多尺度判别网络来捕获移动图像的全局和局部信息。DPE[4]将U-Net[34]改进为照片增强器,将输入图像转换为具有给定一组照片特征的增强图像。GSGN[18]提出了第一个实用的多任务图像增强网络,它能够学习一对多和多对一的图像映射。PieNet[16]针对人们主观上对图像美学有不同的偏好这一事实,提出了首个用于个性化图像增强的深度学习方法,可以通过选择偏好来增强用户的图像。MIRNet[45]提出了一种架构,其共同目标是通过整个网络保持空间精确的高分辨率表示,并从低分辨率表示中接收强上下文信息。CSRNet[9],[26]分析了图像增强的数学公式,提出了一个由1 × 1卷积层组成的轻量级框架。然而,这些方法在整个增强过程中缺乏透明度,就像一个“黑盒子”,这使得它们的可靠性变得模糊。
3)基于物理建模的方法:受到专业级软件(如Photoshop, Lightroom)中的参数化(渐变,径向滤镜),笔刷工具等的启发,基于物理模型[8],[5],[40],[7],[37],[29],[30],[46]的增强,[21]根据提出的物理模型和假设,通过预测相关的物理参数和变量来调整图像颜色。受双边网格处理和局部仿射颜色变换的启发,HDRNet[5]在双边空间中预测局部仿射模型的系数,以近似期望的图像变换。retexnet[40],[22]假设观测图像可以分解为反射率和照度,以增强弱光图像。DeepUPE[37]引入了中间照明,将输入与预期的增强结果相关联,以学习复杂的摄影调整。ZeroDCE[7]将光增强作为图像特定曲线估计的任务,并估计输入图像的动态范围调整的像素和高阶曲线。SCI[28]建立了一个具有权重共享的级联照明学习过程来处理弱光增强任务。DeepLPF[29]提出了三种不同类型的可学习的空间局部滤波器(椭圆滤波器,渐变滤波器,多项式滤波器),并对这些滤波器的参数进行回归,然后自动应用这些滤波器来增强图像。受Photoshop曲线工具的启发,CURL[30]设计了一个多色空间神经修饰块,并使用人类可解释的图像增强曲线调整全局图像属性。
特别是为了提高图像增强的质量和效率,已有的一些研究[23]、[46]、[38]、[43]提出通过改进数字图像处理中的基本物理模型3D LUT来增强图像。这些方法通常采用两步解决方案,1)基于三维LUT预测相关系数得到增强器,2)根据每个原始像素的RGB值逐一调整颜色,通过均匀增强器形成增强图像。虽然这些方法在增强过程中花费较少的运行时间,但它们只能对增强结果的所有区域实现全局总体平均,缺乏对每张图像中具有不同内容的像素的颜色变换进行精细控制的能力。因此,在本文中,我们将3D LUT扩展到4D空间,并通过引入额外的维度(即上下文信息)来指导与内容相关的图像增强。
III. METHODOLOGY
在本节中,为了帮助理解新提出的4D LUT,我们首先简要回顾了关于3D LUT和三线性插值的初步介绍。然后详细描述了4D LUT的概述和各个组成部分。
A. Preliminary
1) 3D LUT: 3D LUT是不同相机成像管道系统和软件中常用的图像增强工具,可以通过手动或算法调整来实现不同类型的增强。三维LUT可以表示为三维晶格,晶格中每个元素的值可以表示为三元组(R(i,j,k) out, G(i,j,k) out, B(i,j,k) out),其中i,j,k∈{0,…,Nbin−1},Nbin是三个维度上每个维度上的bin个数。这样一个格子一共包含N3个bin采样点,构成了一个完整的三维颜色变换空间。如图图(a)所示,通过对RGB色彩空间进行均匀离散化,可以将输入到该色彩空间的元素(rin, gin, bin)映射为一个索引。相应的转换输出RGB颜色(route, gout, bout)是与索引对应的值。值得注意的是,随着Nbin值的增大,3D色彩变换空间对于色彩变换来说变得更加精确,反之亦然。
2)三线性插值:如上所述,LUT中元素的分布在空间上是离散的,不能通过输入指标直接采样。因此,当对3D LUT中的元素进行采样时,输入颜色将根据其索引找到最近的采样点,并通过三线性插值[23],[46]计算其变换后的输出。具体来说,为了找到输入索引附近最近的8个相邻元素,我们首先根据输入的RGB颜色(r(x,y,z) in, g(x,y,z) in, b(x,y,z) in)构建3D LUT的输入索引(x,y,z),其过程描述如下:
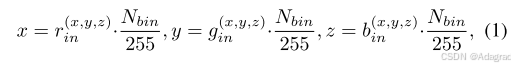
其中Nbin是三维LUT中每个三维的箱子数。我们用(i, j, k)表示定义的采样点的位置,其计算公式如下:

B. Context-aware 4D LUT
现有作品[23]、[46]、[38]、[43]对3D LUT进行了改进以增强图像,在图像中缺乏必要的内容信息。因此,我们提出了可学习的上下文感知4D LUT,以实现与内容相关的图像增强,并能够更好地控制每个图像中具有不同内容的像素的颜色转换。
如图图2所示,我们的方法将输入图像和几个预定义的基4D lut作为输入,最终生成增强图像。它包括四个密切相关的组件,上下文编码器,参数编码器,4D LUTs融合模块和四线性插值模块。具体来说,它涉及以下几个阶段:1)我们首先使用上下文编码器通过端到端学习从输入图像生成表示像素级类别的上下文映射。2)同时,我们使用参数编码器生成图像自适应系数,用于融合可学习的预定义基础4D lut。3)然后,基于参数编码器的输出,我们使用4D LUT融合模块将可学习的基础4D LUT整合成最终的具有更多增强功能的上下文感知的4D LUT。4)最后,将原始输入图像和上下文感知的4D LUT输入到四线性插值模块中,得到增强图像。在下文中,我们将分别描述它们。
1)上下文编码器:上下文编码器可以在目标函数的约束下,以可学习的方式自适应生成与内容相关的上下文映射。我们使用Econtext(·)来表示上下文编码器,它由一系列堆叠的剩余块组成。它包括4个3 × 3内核大小的残差块和1个1 × 1内核大小的残差块。其中,3 × 3残差块用于从输入图像中提取相同分辨率的高级图像特征,1 × 1残差块用于压缩图像特征并输出上下文地图。假设给定一个输入图像Iinput∈R3×H×W。生成的上下文映射C∈R1×H×W可表示为:
![]()
直观地说,上下文编码器可以看作是一个函数,它将输入图像中每个位置的内容信息映射到一个紧凑的标量表示。在训练期间,上下文编码器由后面连接的模块的反向传播梯度更新。在推理过程中,根据不同区域的高级语义差异自适应生成更适合增强的上下文映射。
2)参数编码器:为了方便多个预定义的基础4D LUT融合,提高4D LUT增强能力,参数编码器在端到端训练过程中提取一组图像自适应系数用于4D LUT融合。我们使用Eparam(·)表示参数编码器,它由一系列堆叠的残差块和一个由卷积层组成的参数输出层组成。假设给定一个输入图像Iinput∈R3×H×W。生成的参数W∈RNw×1×1, B∈RNb×1×1可表示为:

在训练过程中,参数编码器通过后面连接模块的反向传播梯度进行更新。在推理过程中,参数编码器可以被视为一个参数预测器,它将可学习的基础4D LUT集成在软加权策略中,以实现自适应上下文感知的4D LUT生成,从而更好地增强图像。
3) 4D lut融合:在端到端训练过程中,自定义基4D lut的元素逐渐更新,以适应色彩空间的变化。为了获得具有更强颜色转换能力的上下文感知4D LUT, 4D LUT融合模块利用参数编码器获得的系数对多个可学习的基4D LUT进行融合。

一般来说,权重的增加允许不同的色彩空间相互作用和融合,从而产生更合适的色温(类似于白平衡)。偏置的加入可以自适应地增强图像的整体亮度。这种融合方法的设计使得融合后的上下文感知4D LUT具有更优越的增强能力。
4) quadrilinelinear Interpolation:基于原始RGB图像、生成的上下文映射以及上下文感知的4D LUT,通过插值运算得到增强图像。然而,与第III-A节描述的3D LUT和三线性插值不同,我们提出的4D LUT的索引是在4维空间上(即RGB+Context)。


其中输入r({i,i+1},{j,j+1},{k,k+1},{l,l+1}) out是4D LUT中定义的最近的16个相邻采样点({i,i+1},{j,j+1},{k,k+1},{l,l+1})对应的变换后的输出红色。同样,我们也可以用同样的方法得到其他颜色(即g(x,y,z) out和b(x,y,z) out)。四线性插值操作是可微的,可以传播梯度来更新网络的权值和上下文感知的4D LUT的元素值。
C. Training
为了更新4D LUT的元素和网络的参数,在本节中,我们使用了几个目标函数来监督整个训练过程。
1)四维平滑正则化:为了避免四维LUT中极端颜色变化造成的伪影,需要保证从输入空间(即RGBC)到获得的颜色空间(即RGB)的转换足够稳定。我们对4D LUT的元素和参数编码器的输出系数引入l2范数正则化,以提高上下文感知的4D LUT的平滑度。
具体来说,我们在已有工作[46]的启发下,在学习四维LUT的基础上,将三维光滑正则化扩展为四维光滑正则化项,以保证四维LUT中元素的局部平滑。4D LUT Llut s的光滑正则化可计算如下:

2) 4D单调性正则化:为了保持增强过程中的鲁棒性和相对色彩亮度/饱和度,我们按照已有的工作[46]将3D单调性正则化扩展为4D单调性正则化项Lm,如下所示:

4)损失函数:如上所述,在训练过程中,我们的方法总共包括三个损失分量,4D平滑正则化损失、4D单调正则化损失和成对重建损失。对于网络来说,平衡这三者是至关重要的。因此,我们将Ls和Lm(如式14和式15所述)分别乘以αs和αm的权重,以使上下文感知的4D LUT有效,同时不损害增强的性能。总损失函数的表达式为:
![]()
IV. EXPERIMENTS
A. Experimental Settings
1)数据集:我们评估了所提出的4D LUT,并将其与其他最先进(SOTA)方法的性能在三个广泛使用的具有挑战性的基准上进行了比较,这些基准来自两个公共数据集:MIT-Adobe-5K-UPE [37], MIT-Adobe-5K-DPE[4]和PPR10K[23]。
MIT-Adobe- 5k - upe:从MIT-Adobe FiveK数据集[2]中划分一个基准,遵循DeepUPE[37]的数据集预处理过程。MIT-Adobe FiveK数据集是一个常用的风景照片修图数据集,其中有5000张使用各种数码单反相机拍摄的图像。每张图像包含由五位经验丰富的专家(A/B/C/D/E)制作的相应修图版本。为了公平比较,我们遵循之前的作品[4],[29],[30],使用C专家修饰的照片作为图像增强真实值(GT)。我们按顺序选择4500对图像作为训练集,500对图像作为测试集,所有图像在长边上调整为510像素。
MIT-Adobe- 5k -DPE:另一个基准测试包含与MIT-Adobe FiveK数据集[2]相同的图像上下文,但遵循DPE[4]的数据集预处理过程。我们遵循之前的作品[37],[29],[30],使用C专家修图的照片作为真实值 (GT)。不同之处在于,我们依次选择2250对图像作为训练集,500对图像作为测试集。
PPR10K:将于2021年发布的全新大规模人像修图数据集,共包含11161张高质量RAW人像。每张图像都包含由三位经验丰富的专家(a/b/c)制作的相应修图版本。为了公平比较,我们遵循官方的分割[23]将数据集划分为8,875对训练对和2,286对测试对。我们比较了所有专家修改的结果,图像尺寸为360p。
2)评价指标:为了公平比较,我们遵循之前的增强作品[5],[46],[26],使用峰值信噪比(PSNR)和结构相似性指数(SSIM)[39]作为常用指标,评估增强结果与相应的专家修饰图像之间的颜色和结构相似性。
3)实现细节:我们的实验是通过PyTorch在NVIDIA 2080Ti GPU上进行的。为了公平比较,我们遵循之前的工作[23],[46],[38],[43],并使用亚当优化器[17],β1 = 0.9和β2 = 0.999,批大小为1。将初始学习率设置为1 × 10−4,当测试集的损失持续20次而不减小时,将学习率降低0.2倍。我们共同训练了整个模型400个epoch。除了添加尺度在[0.6,1.0]范围内的随机裁剪图像块外,没有使用水平翻转等其他数据增强方法。此外,我们参照前人[23]、[46]的工作,将LUT中的bin个数Nbin和基4D LUT的个数Nlut分别设置为33和3。我们将权重Nw和偏置Nb的个数分别设置为27和3。通过讨论实验,我们将αs和αm分别设为0.0001和10。
B. Comparison with State-of-the-art Methods
我们比较了我们的4D LUT与其他经典的SOTA方法。这些方法可以归纳为三类:基于强化学习的方法(即WhiteBox [12], Dis-Rec[32]和UIE[19]),图像到图像转换方法(即DPED [13], 8Resblock [47], [25], CRN [3], U-Net [34], DPE [4], GSGN [18], MIRNet [45], CSRNet[9],[26]),以及基于物理建模的方法(即HDRNet [5], DeepUPE [37], DeepLPF [29], TED+CURL [30],3d lut [46], 3d lut + hrp[23])。为了公平比较,我们从他们的原始论文中获取性能,或者根据作者官方发布的模型的推荐配置重现结果。1)定量比较:各算法在数据集MIT-Adobe-5K-UPE[37]和MITAdobe-5K-DPE[4]上的评估结果如表所示。I和Tab。II,分别。利用基于图像到图像转换方法(即DPED[13]、8Resblock[47]、[25]、CRN[3]、U-Net[34]、DPE[4]、GSGN[18]、MIRNet[45]、CSRNet[9]、[26])的纯CNN结构的强大功能,通过设计庞大复杂的网络模型来进行图像增强;其性能通常与模型大小正相关。最新的CSRNet算法[9],[26]使用1 × 1卷积核设计了一个轻量级增强模型,但仍然缺乏增强能力。此外,基于强化学习的算法(White-Box[12]、Dis-Rec[32]、UIE[19])通过多步解耦提高了增强能力,也取得了令人满意的效果,但计算成本太大。基于物理模型的方法(即HDRNet[5]、DeepUPE[37]、DeepLPF[29]、TED+CURL[30]、3D LUT [46], 3D LUT+HRP[23])基于理论物理模型和假设,在增强过程中是透明的。具有代表性的是,最新算法3D LUT[46]的性能普遍优于其他方法。然而,该方法侧重于学习一个统一的增强器,并在增强结果的所有区域上获得全局总体平均值,这降低了增强的准确性,并可能导致次优性能。
我们提出的4D LUT将查找表架构扩展到4维空间,并实现了与内容相关的图像增强。如Tab所示。I和Tab。II,实现了24.96dB和24.61dB的PSNR结果,在所有数据集上都明显优于其他算法。具体而言,在MIT-Adobe-5K-UPE[37]和MIT-Adobe-5K-DPE[4]数据集上,4D LUT分别比3D LUT[46]高0.36dB和0.28dB。如此大的边缘显示了4D LUT在图像增强方面的强大功能。为了进一步验证4D LUT的泛化能力,我们在另一个更大规模人像照片修图数据集PPR10K[23]上对4D LUT进行了评估。如Tab所示。III,由于4D LUT设计良好,并且具有内容依赖学习能力,因此4D LUT在三种专家润色结果中都取得了更好的效果,优于其他SOTA方法在0.22dB到0.30dB之间。结果表明,在不同场景下,4D LUT具有较强的泛化能力。
2)定性比较:为了进一步比较不同算法的视觉质量,我们在图和图4中展示了所提出的4D LUT和其他SOTA方法在不同数据集上增强的视觉结果。为了公平比较,我们要么直接取作者发布的原始增强结果,要么使用作者发布的模型得到结果。
可以看出,4D LUT在视觉质量和评价指标(即PSNR和SSIM)上都有很大的提高。例如,在图的第一行中,相对于其他使用统一增强器对风景和肖像进行增强的方法,4D LUT可以同时获得蓝色的风景和舒适的彩色肖像。在图的第三行,我们的4D LUT可以通过引入额外的上下文维度来实现更强的增强能力,这可以产生更明亮的绿色植物和肖像。如前所述的分析,结果验证了4D LUT具有更强的增强能力,可以达到更好的效果,特别是对于内容丰富的照片。
3)复杂性分析:模型大小和推理时间在实际应用中通常很重要。我们遵循以前的工作[9],[26]报告他们通过使用RTX 2080Ti GPU增强360p图像。如Tab所示。第三,与其他SOTA方法相比,4D LUT在保持#Param可比性的同时实现了更高的性能。需要强调的是,由于维度的扩展,4D LUT的参数数比3DLUT的[46],[23]要大(即216K vs 108K)。此外,由于上下文图的生成和四线性插值,4D LUT比3D LUT[46]要慢,但也明显超过了实时运行时间(即30fps)。需要强调的是,每个像素的四线性插值是相互独立的,这种转换可以很容易地使用GPU并行化,因此不会增加太多额外的时间。
C. Ablation Study
在本节中,我们在MIT-Adobe-5K-UPE[37]数据集上进行了模型设计和损失函数的消融实验。
1)模型设计:为了验证4D LUT中各部件的有效性,我们对各部件进行了烧蚀实验。实验结果见表四。“Base”表示无上下文编码器(即上下文图为全零图像)和无参数编码器(即直接将基础4D lut求和进行融合)的结果。“CE”和“PE”分别表示上下文编码器和参数编码器。结果表明,加入CE后,PSNR提高了1.34dB。结果表明,上下文编码器的加入使网络能够学习依赖于内容的图像增强,从而产生更强的增强能力。PE的加入使PSNR提高了2.01dB,验证了可学习的图像自适应系数可以更好地融合到上下文感知的4D LUT中,增强了上下文感知的4D LUT的能力。当CE和PE同时参与相互增强时,性能提高2.32dB。
我们进一步探讨了视觉差异,如图5所示,上下文编码器可以产生与内容相关的图像增强,而参数编码器可以产生更丰富的颜色。证明了4D LUT各分量的优越性,可以获得更好的图像增强性能。
2)损失函数:为了验证各个损失函数在4D LUT中的有效性,我们对它们进行了烧蚀实验。实验结果见表V。“Lr”表示两两重建损失。“Ls”和“Lm”分别表示四维平滑正则化损失和四维单调正则化损失。加入Ls后,PSNR可以从24.74dB提高到24.79dB,验证了4D平滑正则化损失可以保证从输入空间(即RGBC)到获得的颜色空间(即RGB)的稳定过渡。当涉及到Lm时,色彩变换可以保留相对色彩亮度/饱和度,覆盖整个RGBC空间,性能提高到24.96dB。证明了4D LUT各损失函数的优越性,可以获得更好的图像增强性能。
V. DISCUSSIONS
在本节中,为了进一步证明4D LUT的合理性,我们首先将提出的上下文地图和上下文感知的4D LUT可视化。然后讨论了在四维LUT中,箱数Nbin的影响以及四维LUT的基数Nlut。最后讨论了光滑正则化权αs和单调正则化权αm的敏感性。
A. Visualization of Context Map
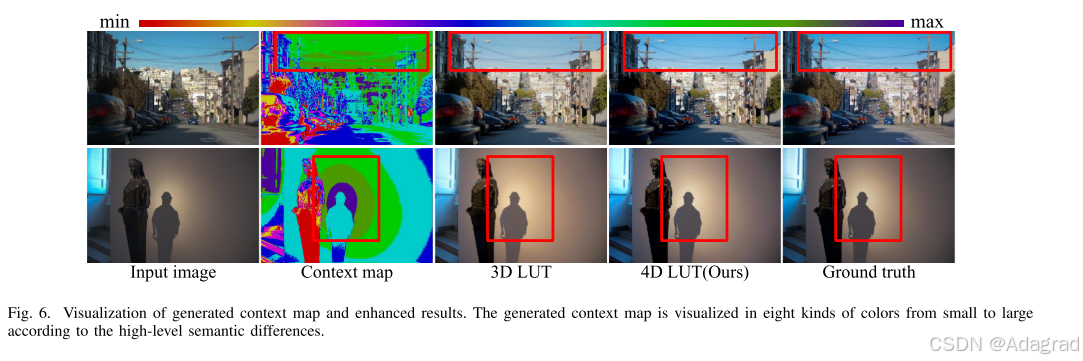
上下文映射用于区分不同区域之间的高级语义差异。为了探索上下文图C在4D LUT中的有效性,我们将其可视化,如图图6所示。其中,我们用8种颜色将生成的上下文图中的不同内容从小到大可视化,可以看出生成的上下文图有效地自适应划分了具有不同高层语义差异的区域。与不涉及上下文图的3D LUT结果相比,结果(红框所示)表明,我们的上下文4D LUT有效地实现了内容依赖增强,效果更好。
B. Visualization of Context-aware 4D LUT
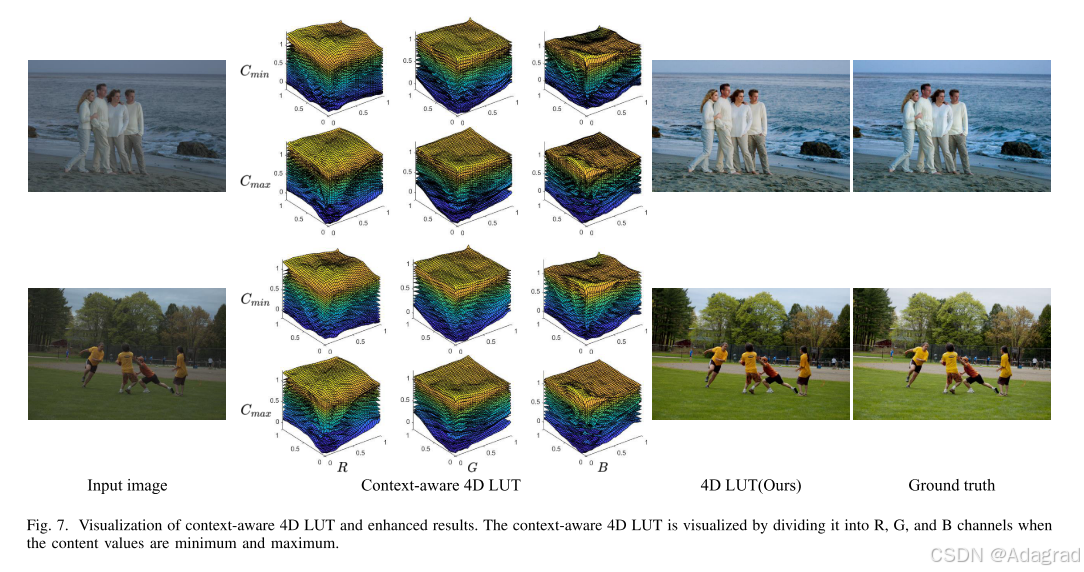
为了更好地研究上下文感知4D LUT的这种内容依赖增强特性,在图中,我们将两幅不同图像的上下文感知4D LUT可视化,并显示其相应的增强结果。此外,为了更清晰地显示上下文感知4D LUT上每个R、G、B通道的差异,我们分别将上下文映射的值固定为最大值和最小值,然后可视化17个切片(即{1,3,…, 31,33}),共33个切片。
由图7可以看出,对于含有蓝海和绿草的图像,我们的方法可以针对不同的形状自适应生成不同的4D LUT。这说明4D LUT具有针对不同内容的图像建立颜色变换关系的能力。此外,每个图像中不同c维对应的可视化LUT的形状也存在显著差异。这证明了4D LUT具有根据每张图像中不同的内容进行不同颜色变换的能力,可以更精细地控制颜色变换,增强图像效果。可以发现,对于不同的图像或每张图像中不同的内容,4D LUT都可以获得令人满意的视觉效果。
C. Discussion on Number of Bins Nbin in 4D LUT
探讨4D LUT中Nbin个数对增强效果的影响。如Tab6所示,我们将4D LUT划分为不同数量的bin(即{9,17,33,64})。随着Nbin的值从9增加到33,PSNR从24.67dB增加到24.96dB。这是因为Nbin的增加使得用于颜色变换的插值元素更加准确,反之亦然。此外,为了防止4D LUT过度拟合训练数据的颜色变换,并保持颜色变换的泛化性,我们在实验中选择Nbin为33。
D. Discussion on Number of Basis 4D LUTs Nlut
探讨Nlut使用的基四维lut数量对增强效果的影响。如Tab7所示,我们使用不同数量的基4D LUT(即{1,2,3,4,5})融合成第III-B3节中描述的上下文感知的4D LUT。性能与基4D lut的数量呈正相关。它证明了使用多基4D lut可以提高颜色变换的表现力。此外,可以很容易地看出,当基4D lut的数量从1个增加到3个时,其PSNR从22.92dB显著提高到24.96dB,而当基4D lut的数量进一步增加时,其提高幅度变小。因此,通过模型参数数量和性能之间的权衡,我们在实验中将Nlut设置为3。

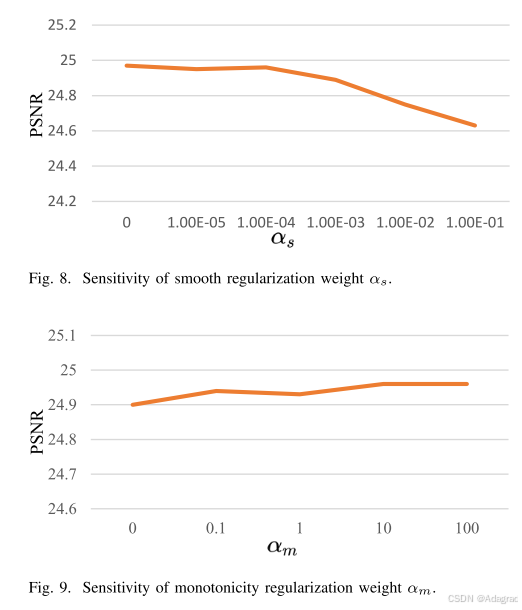
E. Discussion on Smooth Regularization Weight αs
如上文第III-C1节所述,我们使用4D平滑正则化来保证局部颜色变换的稳定性。因此,我们通过设置分布在{0,e−5,e−4,e−3,e−2,e−1}的光滑正则化权值αs来进行实验,选择公式17中合适的值。由图可以看出,当αs过大时,过多的平滑会使A缺少对颜色变换的详细描述,降低了性能。相反,当αs过小时,平滑不足会使网络缺乏对颜色变换的泛化能力。在最后的实验中我们将αs设为0.0001。
F. Discussion on Monotonicity Regularization Weight αm
探讨第III-C2节中单调性正则化权值对色彩增强效果的影响。我们在公式17中设置分布在{0,0.1,1,10,100}的平滑正则化权值αm进行实验。实验结果如图图所示。与不添加单调性正则化相比,4D LUT的单调性正则化可以保持相对色彩亮度,使色彩变换覆盖整个RGBC空间。较大的单调性正则化权αm的影响较小,最后实验将αm设为10
VI. CONCLUSION
在本文中,我们将查找表架构扩展到四维空间,并提出了一种新的可学习上下文的四维查找表(4D LUT)。它包括四个密切相关的组件。1)使用上下文编码器生成依赖于内容的上下文映射。2)用于生成图像自适应系数的参数编码器。3) 4D LUT融合模块将系数和可学习基4D LUT集成为内容感知的4D LUT。4)四线性插值模块输出增强后的图像。该设计引入了图像内容,并能够更好地控制每个图像中像素的颜色转换,从而通过自适应学习图像内容来实现依赖于内容的图像增强。实验结果表明,所提出的四维LUT模型与现有的SOTA模型具有显著的优越性。未来,我们将通过更多的探索,将我们的4D LUT扩展到更多的低级视觉任务中。