【Triton-ONNX】如何使用 ONNX 模型服务与 Triton 通信执行推理任务上-Triton快速开始
模型部署系列文章
- 前置-docker 理解:【 0 基础 Docker 极速入门】镜像、容器、常用命令总结
- 前置-http/gRPC 的理解: 【HTTP和gRPC的区别】协议类型/传输效率 /性能等对比
- 【保姆级教程附代码】Pytorch (.pth) 到 TensorRT (.plan) 模型转化全流程
- 【保姆级教程附代码(二)】Pytorch (.pth) 到 TensorRT (.plan) 模型转化全流程细化
- 前面介绍了模型从 PyTorch 到 TensoRT 转化的过程(属于整体流程图的 Model Repo 那部分),接下来几篇则是将重点放到 client-server 之间的部分,需要我们加深对 triton_client 以及不同的 triton inference server 的理解。
- 【Triton Inference Server 多输入|多输出|无输出】如何用 triton_client.infer 调用多输入、多输出的模型进行推理呢?
- 本篇重点是解释如何使用 Python 库与 Triton 通信执行推理任务,参考官方 repo。
文章目录
- 模型部署系列文章
- Client-Server 整体流程
- 关键步骤
- 一、前置特性了解
- 二、创建模型存储库
- 三、启动 Triton(docker)
- 四、Client 发送推理请求
Client-Server 整体流程

关键步骤
- Creating a Model Repository / 创建模型存储库
- Launching Triton / 启动 Triton
- Send an Inference Request / 发送推理请求
一、前置特性了解
-
Python 客户端库使用 numpy 来表示输入和输出张量。
- 其它框架(如 PyTorch)支持张量,其中张量中的每个元素都位于 可变长度二进制数据。
- 每个元素可以包含一个字符串或 任意字节序列。
- 在客户端上,此数据类型为 BYTES(请参阅 数据类型 有关支持的数据类型的信息)。
-
在某些情况下,使用系统共享内存在客户端库和 Triton 之间通信张量可以显著提高性能。
- Python 示例应用程序 simple_http_shm_client.py 和 simple_grpc_shm_client.py 中演示了如何使用系统共享内存。
- Python 没有分配和访问共享内存的标准方法,因此举个例子,一个简单的系统共享内存模块 提供了,可以与 Python 客户端库一起使用来创建, 设置和销毁系统共享内存。
-
在某些情况下,使用 CUDA 共享内存在客户端库和 Triton 之间传递张量可以显著提高性能。
- Python 示例应用程序 simple_http_cudashm_client.py 和 simple_grpc_cudashm_client.py 中演示了如何使用 CUDA 共享内存。
- Python 没有分配和访问共享内存的标准方法,因此举个例子,一个简单的 CUDA 共享内存模块 提供了,可以与 Python 客户端库一起使用来创建, 设置和销毁 CUDA 共享内存。该模块目前支持 numpy 数组(示例用法)和 DLPack 张量(示例用法)。
正式动手,以👉快速开始为案例。
二、创建模型存储库
- 可以在示例中下载模型来进行尝试
cd docs/examples
./fetch_models.sh
- 本文这里只下载了 densenet 作为尝试
# ONNX densenet
mkdir -p model_repository/densenet_onnx/1
wget -O model_repository/densenet_onnx/1/model.onnx \https://github.com/onnx/models/raw/main/validated/vision/classification/densenet-121/model/densenet-7.onnx
三、启动 Triton(docker)
docker run --gpus all --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $(pwd)/densenet_onnx:/models/densenet_onnx docker.io/xxx:v1 tritonserver --model-repository=/models
- 启动特定 Triton 的 docker 时过程中遇到了: Error response from daemon: could not select device driver “” with capabilities,参考方案得到了解决。
- 启动时要注意所在的路径和 docker 命令对应上。
- 如下 -v $(pwd)/densenet_onnx:/models/densenet_onnx:这部分将当前工作目录下的 densenet_onnx 目录挂载到容器内的 /models/densenet_onnx 目录。
- 那么当前目录下就需要有以下的结构才行。

- 验证 Triton 是否正确运行
- 正常运行后会有以下提示,可以看到模型是处于 READY 状态。

- 新开一个 terminal 后输入以下 curl 的语句。
- 用 Triton 的就绪端点来验证服务器和模型是否已准备好进行推理。
- 从主机系统使用curl 访问指示服务器状态的HTTP 端点。
- 正常运行后会有以下提示,可以看到模型是处于 READY 状态。
curl -v localhost:8000/v2/health/ready# 输出为
* Trying 127.0.0.1:8000...
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
- 这个输出说明 Triton Inference Server 已经准备好(ready)。返回的 200 OK 状态码表示服务器正常运行并能够处理请求。
- 通过访问 /v2/health/ready 端点,你确认了 Triton Inference Server 的健康状态,表明它已成功启动并准备好接受推理请求。
四、Client 发送推理请求
- 可以通过 docker 中的客户端来实现。
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdkdocker run -it --rm --net=host nvcr.io/nvidia/tritonserver:24.08-py3-sdk
-
从 nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk 映像中,运行示例图像客户端应用程序,以使用示例 dendensenet_onnx 模型执行图像分类。
-
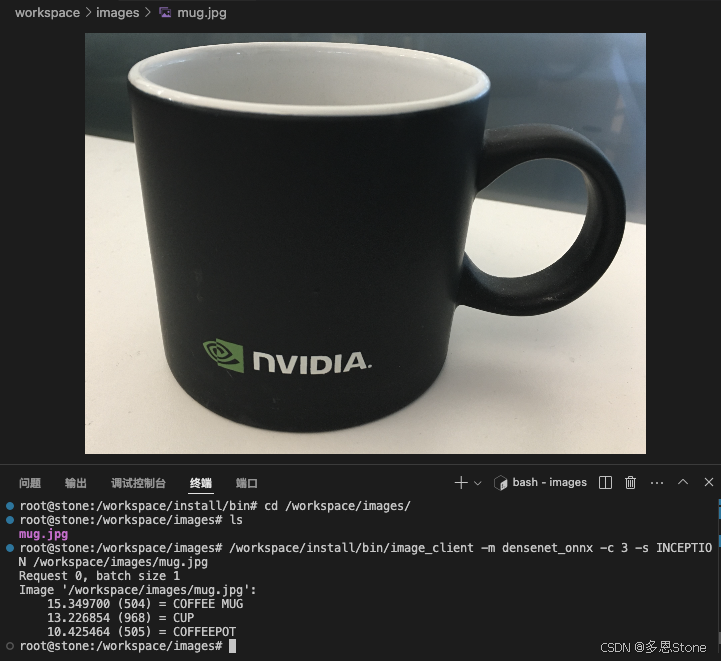
要发送 dendensenet_onnx 模型的请求,请使用 /workspace/images 目录中的图像。在本例中,我们要求前 3 个分类。
$ /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg Request 0, batch size 1 Image '/workspace/images/mug.jpg':15.346230 (504) = COFFEE MUG13.224326 (968) = CUP10.422965 (505) = COFFEEPOT