Python AI 教程之四:无监督学习
什么是无监督学习?
无监督学习是机器学习的一个分支,用于处理未标记的数据。与监督学习(其中数据被标记为特定类别或结果)不同,无监督学习算法的任务是在不了解数据含义的情况下寻找数据中的模式和关系。这使得无监督学习成为探索性数据分析的强大工具,其目标是了解数据的底层结构。
什么是无监督学习?
在人工智能中,在没有人工监督的情况下进行的机器学习被称为无监督机器学习。与监督学习相比,无监督机器学习模型会获得未标记的数据,并允许它们自行发现模式和见解 — 无需明确的指导或指令。
无监督机器学习使用机器学习算法分析和聚类未标记的数据集。这些算法无需任何人工干预即可发现隐藏的模式和数据,即我们不向模型提供输出。训练模型只有输入参数值,并自行发现组或模式。
无监督学习
无监督学习如何进行?
无监督学习通过分析未标记的数据来识别模式和关系。数据没有标记任何预定义的类别或结果,因此算法必须自己找到这些模式和关系。这可能是一项具有挑战性的任务,但它也可能非常有益,因为它可以揭示标记数据集中无法发现的数据洞察。
图 A 中的数据集是购物中心数据,其中包含订阅客户的信息。订阅后,他们会收到一张会员卡,购物中心会获得有关客户及其每次购买的完整信息。现在,使用这些数据和无监督学习技术,购物中心可以根据我们输入的参数轻松地对客户进行分组。
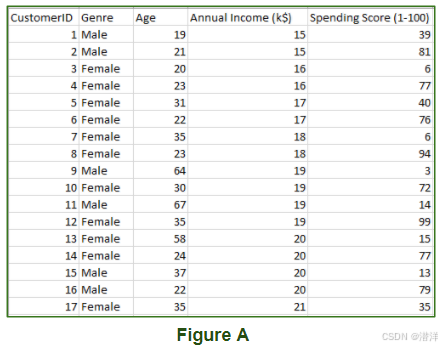
无监督学习模型的输入如下:
- 非结构化数据:可能包含噪声(无意义)数据、缺失值或未知数据
- 未标记数据:数据仅包含输入参数的值,没有目标值(输出)。与监督方法中的标记数据相比,它更容易收集。
无监督学习算法
主要有三种类型的算法用于无监督数据集。
- Cl