yolov7算法及其改进
yolov7算法及其改进
- 1、YOLOV7简介
- 2、ELAN架构设计
- 2.1、Partial Residual Networks
- 2.1.1、Masked Residual Layer
- 2.1.2、Asymmetric Residual Layer
- 2.2、Cross Stage Partial Networks
- 2.2.1、Cross stage partial operation
- 2.2.2、Gradient flow truncate operation
- 2.3、Efficient Layer Aggregation Networks
- 3、yolov7改进
- 3.1、backbone
- 3.2、neck
- 3.3、Head
- 4、正负样本匹配与损失函数
1、YOLOV7简介

1、模型层面:
- 提出了扩展高效的层聚合网络(E-ELAN)
- 基于级联的模型缩放方法
- 基于MP的降维组件
2、训练Trick:
- 卷积重参化
- Batch normalization
- YOLOR中的隐式知识结合卷积特征映射和乘法方式
3、标签分配:
- 无辅助头:同YOLOv5
- 有辅助头:辅助头匹配进行正样本的扩充
2、ELAN架构设计
当今主流的网络设计策略大多基于数据路径设计网络架构。ELAN设计了基于梯度路径的网络设计策略。提出了Layer-level、Stage-level和Network-level的梯度路径设计策略,
1、Layer-level:在这个层次上设计了梯度分流策略。调整层数并计算残差连接的通道比率,然后设计Partial Residual Network(PRN)。
2、Stage-level:添加硬件特征以加快网络推理。最大化梯度组合,同时最小化硬件计算成本,因此设计了Cross Stage Partial Network(CSPNet)。
3、Network-level:增加了梯度传播效率的考虑,以平衡网络的学习能力。还考虑了整个网络的梯度传播路径长度,因此设计了Efficient Layer Aggregation Network(ELAN)。

1、数据路径设计策略:主要侧重于设计特征提取、特征选择和特征融合操作,以提取具有特定属性的特征。这些特征可以帮助后续层使用这些特征进一步获得更好的属性,以便进行更高级的分析。
2、梯度路径设计策略:目的是分析梯度的来源和组成,以及如何通过驱动参数更新梯度。然后,可以使用上述分析的结果来设计网络架构。设计理念是希望最终的参数利用率更高,从而达到最佳的学习效果。
2.1、Partial Residual Networks
Partial Residual Networks(PRN)其设计理念属于Layer-level设计策略。在PRN的设计中,主要概念是最大化用于更新每层的权重的梯度组合。
影响梯度组合的主要因素有2个:
- 第一个是梯度的源层。源层由连接到梯度路径的不相交边缘的节点组成;
- 第二个因素是梯度流通过链式法则的操作从损失层到达特定层所需的时间。
需要注意的一点是,当梯度在链规则更新过程中发生变化时,其覆盖的丢失信息量将随着链的增长而逐渐减少,有以下2种结构来改进ResNet:
2.1.1、Masked Residual Layer
在ResNet的设计中,将每个计算块的输出与identity连接一起添加,这样的结构称为残差层。在PRN中,将identity连接乘以二进制Mask,并且只允许将某些通道的特征映射添加到计算块的输出中。
使用Masked residual layer的机制允许将特征图分为两部分,其中与被Mask的通道相对应的权重和与具有identity连接的通道相对的权重,

2.1.2、Asymmetric Residual Layer
在PRN架构下,提出的Masked residual layer可以将通道数量的不一致性视为某些通道被阻塞,从而允许具有不同通道数量的特征图执行Masked residual操作。
将以上述方式操作的层称为Asymmetric residual layer。Asymmetric residual layer以这样的方式设计,即网络架构更灵活,并且更能够保持基于梯度路径的模型的属性。
例如,当进行特征融合时,一般方法需要额外的过渡层来将不同的特征映射投影到同一维度,然后执行ADD操作。然而,上述操作将增加大量参数和计算量,并且还将使梯度路径更长,从而影响网络的收敛。引入Asymmetric Residual Layer可以完美地解决类似问题。

2.2、Cross Stage Partial Networks
CSPNet于2019年提出,它是一个基于Stage-level梯度路径的网络。与PRN一样,CSPNet基于最大化梯度组合的概念。
CSPNet和PRN的区别在于,后者侧重于从理论角度确认梯度组合对网络学习能力的改善,而前者则是为了进一步优化硬件推理速度而额外设计的。
因此,在设计CSPNet时,将架构从Layer-level扩展到Stage-level,并优化整体架构。
CSPNet主要有以下2种结构:
2.2.1、Cross stage partial operation
首先将输入特征图分成两部分,其中一部分通过计算块,该计算块可以是任何计算块,如Res Block、ResX Block或Dense Block。至于另一部分,它直接跨越整个Stage,然后与经过计算块的部分集成。由于只有部分特征图进入计算区进行操作,这种设计可以有效地减少参数量、操作、内存流量和内存峰值,从而使系统实现更快的推理速度。

2.2.2、Gradient flow truncate operation
由于计算块中经常使用shortcut连接,提供2条路径的梯度源必然会重叠很多。当特征图通过kernel函数时,它相当于空间投影。通常可以在两条路径的末端插入过渡层,以截断复制的梯度流。通过以上步骤可以使从2条路径和相邻Stage学习到的信息具有更明显的多样性。作者设计了3种不同的重复梯度流截断操作组合,如图所示。这些操作可以与不同的架构相匹配,例如计算块和下采样块,以获得更好的结果。

2.3、Efficient Layer Aggregation Networks
在Network层面,它属于梯度路径设计Network的范畴。设计ELAN的主要目的是解决在执行模型缩放时深度模型的收敛性会逐渐恶化的问题。
作者分析了通过整个网络中每个层的最短梯度路径和最长梯度路径,从而设计了具有有效梯度传播路径的层聚合架构。ELAN主要由VoVNet和CSPNet组成,并利用计算块中的堆栈结构优化了整个网络的梯度长度。
在接下来的内容中将详细说明计算块中的堆栈是如何工作的。

当在做模型缩放时会出现一种现象,即当网络达到一定深度时,如果继续堆叠计算块,精度增益将越来越小。当网络达到某个临界深度时,其收敛性开始恶化导致总体精度比浅层网络差。
3、yolov7改进
3.1、backbone

在进入Backbone中的第一个 ELAN 块之前,输入图像将通过 Stem 块。

在YOLOv7-p5、YOLOv7-p6架构中主要是使用ELAN作为Backbone的主要模块。
ELAN 由 3 部分组成:
1、Cross Stage Partial
2、Computation Block
3、PointWise-Conv

在YOLOv7-E6E架构中提出了基于ELAN的扩展版本E-ELAN,其主要架构如右图所示。
在大规模ELAN中,无论梯度路径长度和计算模块数量都达到了稳定的状态。但如果更多计算模块被无限地堆叠,这种稳定状态可能会被破坏,参数利用率也会降低。
YOLOv7提出的E-ELAN采用Expand cardinality、Shuffle cardinality、Merge cardinality结构在不破坏原始梯度路径的情况下,提高网络的学习能力。在体系结构方面,E-ELAN只改变了计算模块中的结构,而过渡层的结构则完全不变。
YOLOv7作者的策略是利用分组卷积来扩展计算模块的通道和基数,将相同的Group parameter和Channel multiplier用于计算每一层中的所有模块。然后,将每个模块计算出的特征图根据设置的分组数打乱成G组,最后将它们拼接在一起。此时,每一组特征图中的通道数将与原始体系结构中的通道数相同。
最后,作者添加了G组特征来Merge cardinality。除了维护原始的ELAN设计架构外,E-ELAN还可以指导不同的分组模块来学习更多样化的特征。

这种架构扩展不仅适用于骨干网中的 ELAN,也适用于 Neck 中的 CSP-OSA。当然,YOLOv7-E6E也像YOLOv7-p6家族一样应用了Auxiliary Head

ELAN 块通过过渡块相互连接。每个 Transition Block 都是将特征图的大小缩小 2 倍。

YOLOv7 的完整主干是 ELAN Blocks 和 Transition blocks 的集合,如图 所示。

SPP最早应用在YOLOv4中,在YOLOv5中改进为SPPF,YOLOv6中改进为SimSPPF,在YOLOv7中,SPP继续被优化和改进,也就是CSP思想的加入,名为SPPCSPC。
SPPCSPC 的奇怪之处在于,两条分支的通道数与原始特征图中的通道数相同,而不是像常规 CSP 那样的一半。但是速度和参数量还是比较大的。

3.2、neck

在 YOLOv7 中,用于组合来自 2 个尺度的 2 个特征图的加法运算符已被连接运算符取代。
此外,在与来自上述尺度的特征图结合后,生成一个中间特征图,该特征图继续由 CSP-OSA 模块处理,而不是与来自尺度的特征图连续结合。
在一个典型的 PANet Top Down 路径(左上)中,它只是一个 FPN,来自上层特征图直接与下层结合,没有任何进一步处理。
在YOLOv7的Top Down路径中,16倍下采样的特征进行上采样后与8倍下采样的特征图融合,然后通过CSP-OSA模块进一步处理,然后与8倍下采样的特征图结合。
在 YOLOv7 的 Bottom Up 路径上,来自底部尺度的特征图将通过 CSP-OSA 进行处理,并通过上面提到的主干上的 Transition Block 进行下采样,而不是像 PANet 那样通过 PANet 进行 3×3卷积。

CSP-OSA 是一个自取的名字,因为我把它看成是一个 CSPized OSA 模块。OSA 模块源自VoVNet,是一个极快且省电的模块。
CSP-OSA 模块的架构如图所示。上图是 VoVNet 中的普通 OSA 模块,上图是 YOLOv7 Neck使用的 CSP-OSA 模块
重参化技术是模型在推理时将多个模块合并成一个模块的方法,其实就是一种集成技术。常见的重参化技术有:
1、一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
2、一种是对不同迭代次数下模型权重进行加权平均。
虽然RepConv在VGG上取得了很不错的效果,但将它直接应用于ResNet和DenseNet或其他骨干网络时,它的精度却下降得很厉害。
作者就是用梯度传播路径的方法来分析,因为RepConv结合了3×3卷积,1×1卷积,和在一个卷积层中的identity连接,可是identity破坏了ResNet的残差连接以及DenseNet的跨层连接,为不同的特征图提供了更多的梯度多样性。
因此,作者认为,在同时使用重参化卷积和残差连接或者跨层连接时,不应该存在identity连接,而且作者还分析重参化卷积应该如何与不同的网络结构相结合,并设计了不同的重参化卷积。

CSP-OSA 是一个自取的名字,因为我把它看成是一个 CSPized OSA 模块。OSA 模块源自VoVNet,是一个极快且省电的模块。

3.3、Head
在网络的训练中,标签分配通常是指GT,这个是硬标签,但近年来,需要研究者会利用网络的推理结果来结合GT,去生成一些软标签,如IOU。
在YOLOv7中,有辅助头也有引导头,在训练时,它们二者都需要得到监督。因此,需要考虑如何为辅助头和引导头进行标签分配。因此在这里,作者提出了一种新的标签分配方法,是以引导头为主,通过引导头的推理来指引辅助头和自身的学习。

4、正负样本匹配与损失函数
在过去,在深度网络的训练中,标签分配通常直接指的是GT本身,并根据给定的规则生成hard label(未经过softmax)。然而近年来,以目标检测为例,研究者经常利用网络预测的质量分布来结合GT,使用一些计算和优化方法来生成可靠的软标签(soft label)。
例如,YOLO使用bbox预测和GT的IoU作为软标签。在本文中,YOLOv7将网络预测结果与GT一起考虑后再分配软标签的机制称为“标签分配器”。无论辅助头或引导头,都需要对目标进行深度监督。那么,如何为辅助头和引导头合理分配软标签?这是作者需要考虑的问题。
目前最常用的方法如上图©所示,即将辅助头和引导头分离,然后利用它们各自的预测结果和GT执行标签分配。本文提出的方法是一种新的标签分配方法,通过引导头的预测来引导辅助头以及自身。换句话说,首先使用引导头的prediction作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习,具体可看图(d)和(e)。

首先使用引导头的推理结果作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习。
1、Lead head guided label assigner:引导头引导标签分配是根据引导头的预测结果和GT进行一系列优化计算来生成软标签,然后软标签作为辅助头和引导头的优化方向来训练模型。
这样是由于引导头本身具备比较强的学习能力,因此由此产生的软标签应该更能代表源数据与目标之间的分布和相关性,而且还可以将这种方式当作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,然后引导头就更能专注于学习到它还没有学习到的剩余信息。
2、Coarse-to-fine lead head guided label assigner:从粗到细的引导头引导标签分配 Coarse-to-fine引导头使用到了自身引导头的推理结果GT来生成软标签,进而引导标签进行分配。然而,在这个过程中会生成两组不同的软标签,即粗标签和细标签, 其中细标签与引导头在标签分配器上生成的软标签是一样的,粗标签是通过允许更多的网格作为正目标,不单单只把GT中心点所在的网格当成候选目标,还把附近的3个也加进来了,增加正样本候选框的数量,以降低正样本分配的约束。
因为辅助头的学习能力没有引导头强,所以为了避免丢失需要学习的信息,就提高辅助头的召回率,对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。

YOLOX中直接将中心临近的3×3区域分配为正样本,这样便增加了样本采样的数量,进而可以加快模型训练过程的收敛,同时也一定程度上缓解了正负样本采样极度不均衡的问题,这个过程也就是论文中所说的Multi positives。

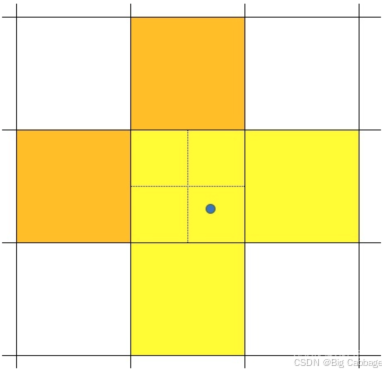
YOLOv7的样本匹配主要是将simOTA中的第1步使用中心先验替换成YOLOv5的策略。
YOLOv5策略与YOLOX中simOTA策略的融合,相较于只使用YOLOv5策略,加入了Loss Cost Aware,利用当前模型的表现,能够再进行一次精筛。而融合策略相较于只使用YOLOX中simOTA,能够提供更精确的先验知识。
Lead head中每个网格与GT如果匹配上,附加周边两个网格,而Aux head附加4个网格。
Lead head中将Top10个样本IOU求和取整,而Aux head中取Top20。
Aux head更关注于Recall,而Lead head从Aux head中精准筛选出样本。
训练时的其它策略
- Batch Normalization:即将Batch Normalization层直接连接到卷积层中。这样可以在推理时将Batch Normalization的均值和方差直接融合到卷积层的偏差和权重中。
- YOLOR中结合隐性知识和卷积特征图的加法和乘法方法:在YOLOR中,它认为隐式知识可以在推理时通过预计算步骤被简化为向量。然后再把这个向量和前一个或后一个卷积层的偏差和权重融合在一起。
- EMA:EMA是一种在mean teacher中使用的技术,在系统中使用EMA模型纯粹作为最终的推理模型。EMA可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关,这里可以取得平滑的作用。如果取n步的平均,就能使得模型更加得鲁棒。