InnoDB引擎的内存结构
InnoDB擅长处理事务,具有自动崩溃恢复的特性
架构图:
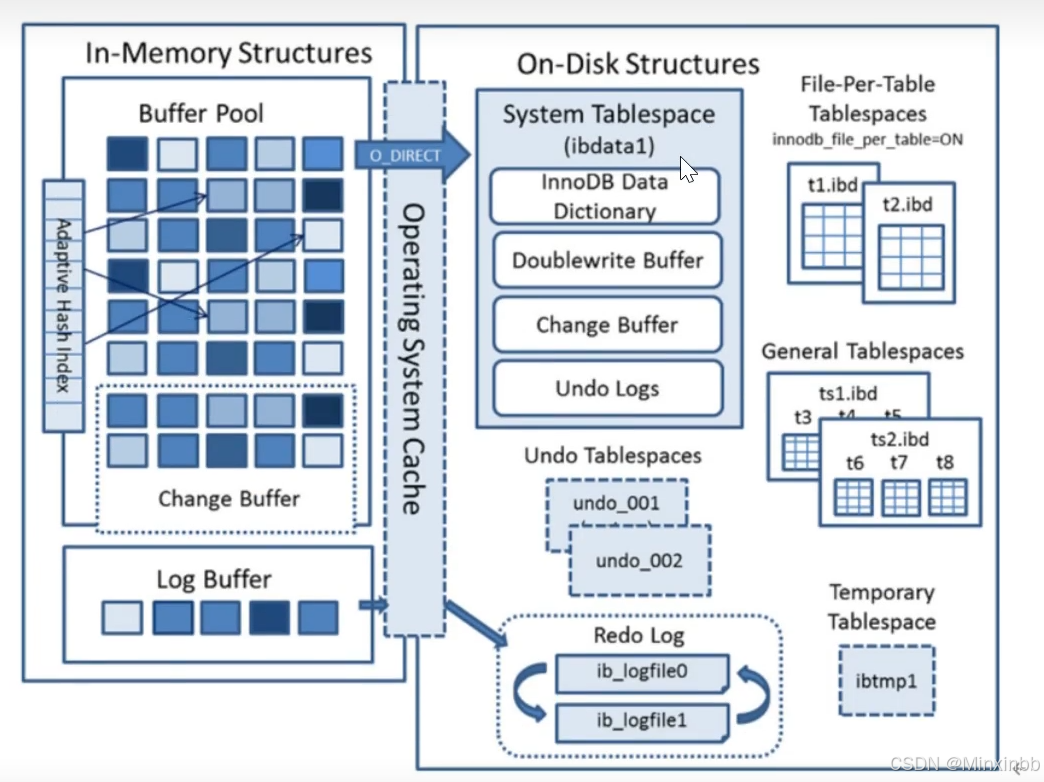
由4部分组成:
1.Buffer Pool:缓冲池,缓存表数据和索引数据,减少磁盘I/O操作,提升效率
2.change Buffer:写缓冲区,针对二级索引页的更新优化措施
3.Log Buffer:日志缓冲区,缓存写入磁盘是log文件的数据,用来优化每次更新操作之后都要写入redo log产生的磁盘I/O
4.Hash index:自适应哈希索引
什么是Buffer Pool
Buffer Pool:有缓存页(Page)和控制块组成
1.缓存页:InnoDB引擎以页为单位,作为磁盘和内存的交互,一个页默认大小16KB
Buffer Pool除了 索引页和数据页,还有undo页,插入缓存页,锁信息,自适应哈希索引页。
2.控制块:存储着缓存页的表空间信息,数据页编号,与缓存页在Buffer Pool的地址信息
3.默认大小是128M,以Page页为单位,Page页16KB,控制块一般为数据页的5%
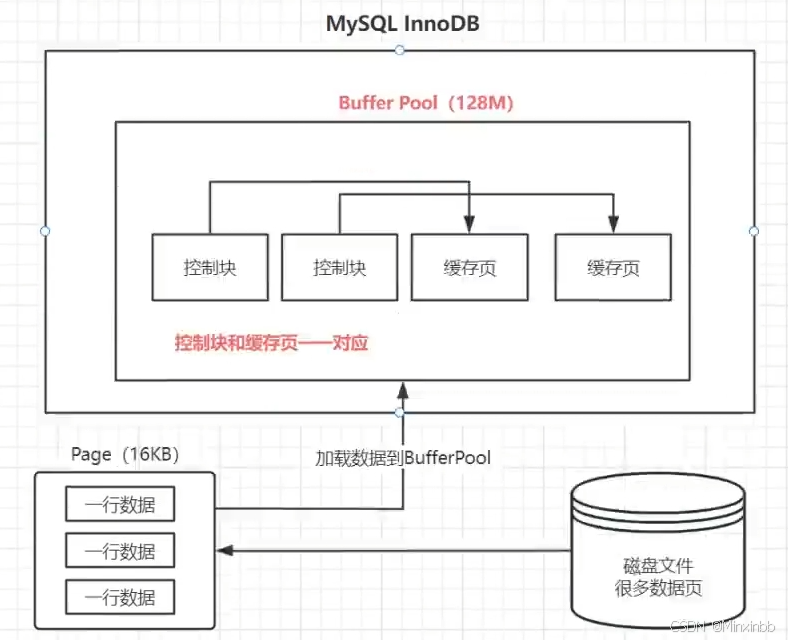
如何判断一个页是否在BP中存储? 在MySQL中有一个Hash表数据结构,它使用表空间号+数据页编号,作为一个key,value是缓存页对应的控制块。当我们需要访问某个 页的数据时,先从Hash表中根据表空间号+页号,查看是否有对应的缓存页。
Buffer Pool中如何管理Page
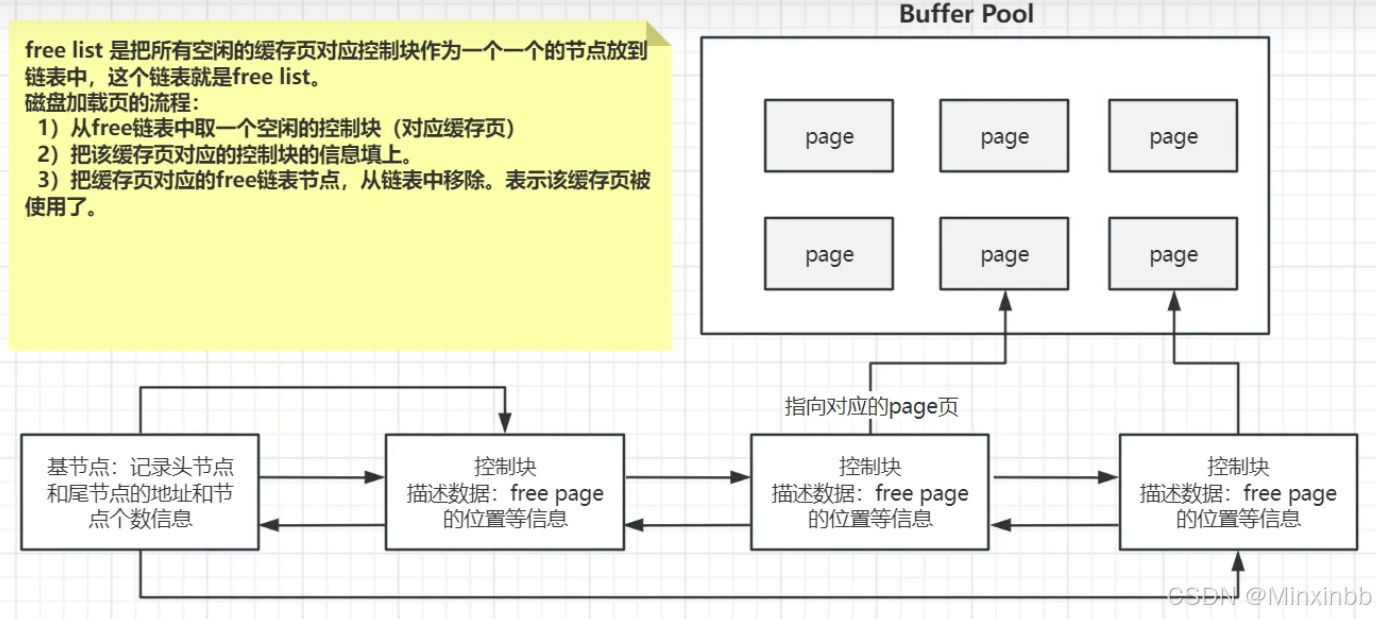
Page页分类:在BP的底层采用的是链表数据结构管理Page,根据状态分为3种类型:
-
free Page:空闲的页,未被使用的页
-
clean Page: 被使用的页,但数据没有修改过
-
dirty Page:脏页,被使用过的页,并且数据被修改了,缓存页中的数据与磁盘数据不一致
上面说的三种类型,InnoDB采用三种链表结构进行维护和管理
-
free list:表示空闲缓冲区,管理free Page
-
flush list:表示是需要刷新到磁盘的缓冲区,管理脏页,内部页按照修改时间排序

-
lru list:表示正在使用的缓冲区,管理被使用的页以及脏页,该缓冲区以 midpoint 为基点,前面的链表称为new 列表区,存放经常被访问的数据,占63%,后面的链表称为old列表区,存放的是使用较少的数据占37%
注意:脏页在fiush链表和LRU链表中互不影响,LRU链表负责管理page的可用性和释放,而fush list负责管理脏页的刷盘操作。