对中文汉字排序的方法总结

写在前面
在各个系统中,都随处可见根据某个字段进行升序(ASC)或降序(DESC)进行排序展示。但进行中文汉字排序和查找的时候,对中文汉字的排序和查找结果往往都是错误的。
为了尽量提供全面的解决方法,本文会从各个层面出发告知有需要的人对应的解决方法。
场景一 在MYSQL中如何正确对中文进行排序
解决方法:在查询语句的 order by 部分使用 CONVERT 函数。
-- 对中文排序 升序
select * from tb_resource_type ORDER BY CONVERT(type_name USING gbk)
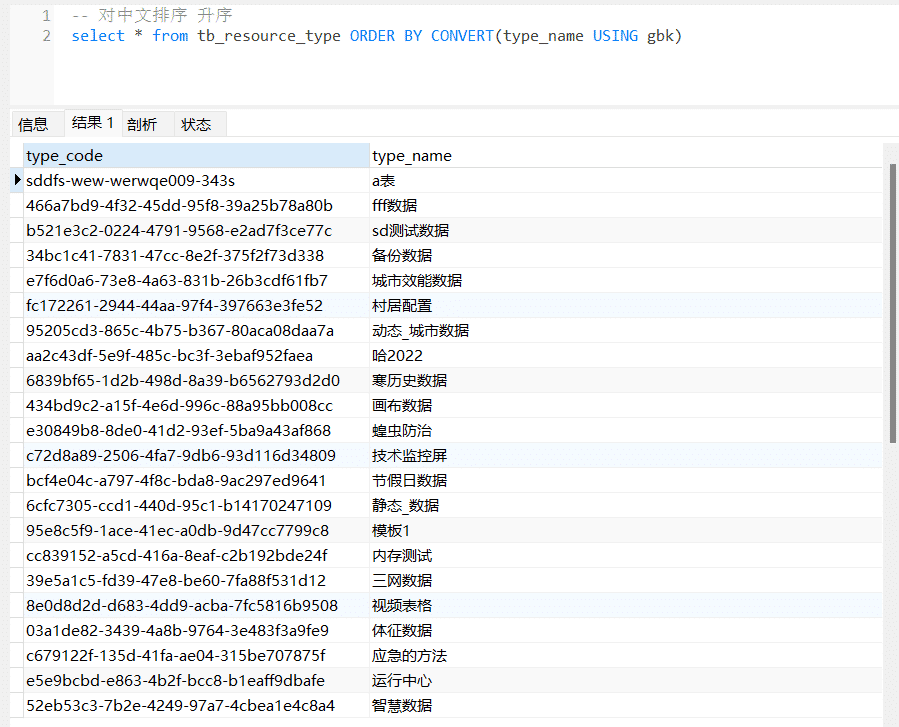
-- 对中文排序 降序
select * from tb_resource_type ORDER BY CONVERT(type_name USING gbk) DESC
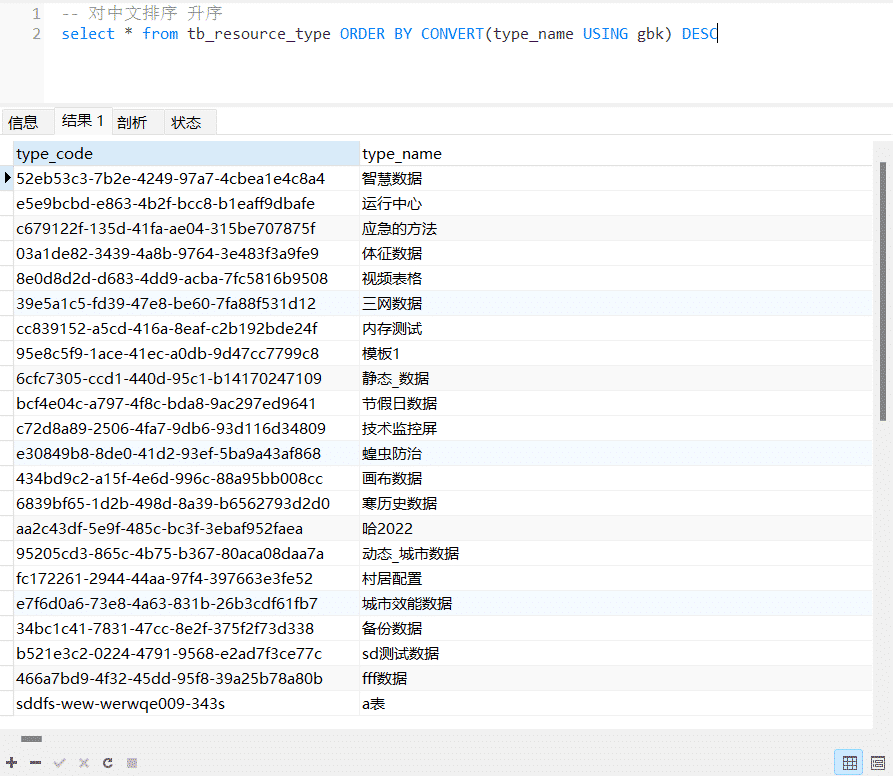
场景二 在接口开发中如何正确对中文进行排序
使用Collections.sort()重新compare方法进行中文 升序,以下仅为代码片段,仅供参考。
Comparator comparator = Collator.getInstance(Locale.CHINA);Collections.sort(codeList, new Comparator<TbmResourceVo>() {@Overridepublic int compare(TbmResourceVo vo1, TbmResourceVo vo2) {return comparator.compare(vo1.getTypeName(), vo2.getTypeName());}});
如何在代码中进行中文倒序排序,可以在升序的基础上,利用 Collections.reverse() 即可完成。
Comparator comparator = Collator.getInstance(Locale.CHINA);Collections.sort(codeList, new Comparator<TbmResourceVo>() {@Overridepublic int compare(TbmResourceVo vo1, TbmResourceVo vo2) {return comparator.compare(vo1.getTypeName(), vo2.getTypeName());}});Collections.reverse(codeList);
其他方式
也可以将汉字转为拼音在进行排序,添加pinyin4j的依赖。
<dependency><groupId>com.belerweb</groupId><artifactId>pinyin4j</artifactId><version>2.5.0</version>
</dependency>
The end.