【python自动化六】UI自动化基础-selenium的使用
selenium是目前用得比较多的UI自动化测试框架,支持java,python等多种语言,目前我们就选用selenium来做UI自动化。
1.selenium安装
安装命令
pip install selenium

2.selenium的简单使用
本文以chrome浏览器为例,配套selenium中chrome相关的操作方法,先给一个简单的示例:
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byoptions = webdriver.ChromeOptions()
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('prefs', {'credentials_enable_services': False,'profile.password_manager_enabled': False})
options.add_experimental_option('excludeSwitches', ['enable-automation'])
service = Service()
driver = webdriver.Chrome(options=options, service=service)
driver.maximize_window()driver.get('https://www.baidu.com/')
driver.find_element(By.ID, 'kw').send_keys('csdn')
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="su"]').click()
time.sleep(5)
driver.quit()
它的效果如下:

下面我们看下具体的代码:
配置项
这部分是参数部分,主要是我们在启动谷歌浏览器时的一些配置
options = webdriver.ChromeOptions()
options.add_experimental_option('useAutomationExtension', False) # 隐藏“chrome正在受到自动化软件的控制”
options.add_experimental_option('prefs', {'credentials_enable_services': False,'profile.password_manager_enabled': False}) # 禁止弹出密码保存弹窗
options.add_experimental_option('excludeSwitches', ['enable-automation']) # 防止自动化检测
上述配置主要是隐藏了页面最上方的“chrome正在受到自动化软件的控制”和禁止弹出密码保存弹窗,当然还有其他各种配置,我们在进行自动化测试时,可以选用我们需要的配置,避免自动化受到不必要的干扰。
这些配置就是Chrome浏览器的启动项,实际就和我们命令行中启动chrome浏览器时,chrome.exe后带的参数是一样的。目前没有找到所有配置项的汇总,这里附上一份Chromium Command Line Switches列表
https://peter.sh/experiments/chromium-command-line-switches/,这个由chromium团队维护,但不一定全。
下面再附上我们自动化常用的一些配置
options.add_argument('lang=zh_CN.UTF-8') # 设置中文
options.add_argument('--headless') # 无头参数,浏览器隐藏在后台运行
options.add_argument('--disable-gpu') # 禁用GPU加速
options.add_argument('--start-maximized')#浏览器最大化
options.add_argument('--window-size=1280x1024') # 设置浏览器分辨率(窗口大小)
options.add_argument('--user-agent=""') # 设置请求头的User-Agent
options.add_argument('--incognito') # 隐身模式(无痕模式)
prefs = {"download.default_directory":"D:\download", # 设置浏览器下载地址(绝对路径)"profile.managed_default_content_settings.images": 2, # 不加载图片
}
chrome_options.add_experimental_option('prefs', prefs) # 添加prefs # 设置无账号密码的代理
options.add_argument('--proxy-server=http://ip:port')
Selenium Manager
这边开始启动浏览器,可以注意的是,这里没有设置chrome driver的地址,新版selenium已经无需设置驱动地址,它会自己寻找,若是没有或者版本不一致,会自动下载对应版本的驱动到本地,然后启动chrome浏览器
service = Service()
driver = webdriver.Chrome(options=options, service=service)
前文在日志打印中已经配置了日志,这里我们可以本地打印一下日志,看下selenium启动浏览器的过程

可以看着这部分的日志,首先selenium查找了下PATH中没有设置chrome driver的路径,然后查找chrome.exe的本地路径,获取到本地chrome的版本号后,从known-good-versions-with-downloads.json中获取当前chrome版本对应的driver的版本,然后将对应版本的driver下载到本地。这个就是未配置driver路径时,selenium管理chrome和其driver的过程。
下面我们再执行一次,看下本地已有对应版本的driver时,有什么区别

可以看到已经检测到driver已存在,未再次下载。
下面我们在代码中设置下driver的路径
service = Service('C:\\Users\\12056\\.cache\\selenium\\chromedriver\\win64\\131.0.6778.204\\chromedriver.exe')
driver = webdriver.Chrome(options=options, service=service)

可以看到这里就不再寻找dirver的路径,而是直接使用已经设置好的driver开始启动浏览器。
这里建议,我们平时用于自动化的机器上,浏览器最好设置成禁用更新,然后将driver的路径设置好,这样能减少寻找driver和下载driver的时间,因为有时候涉及到网络安全,有些企业的外网访问是有限制的。我们只需固定一段时间更新一下浏览器版本和驱动版本即可,无需一直实时更新。
driver的调用
我们先简述下其大概的工作原理:测试代码先启动webdriver,我们在测试代码中发送命令给driver(http请求),driver将执行命令发送给浏览器,浏览器执行后将返回结果给driver,driver再将结果返回给测试代码。
如下图日志所示:

selenium将要对浏览器进行的操作封装成http请求(这里看到有启动浏览器、打开百度、寻找页面元素等),发送给webdriver,然后webdriver驱动浏览器操作后,将结果通过http响应返回给测试脚本。更详细的大家可以结合代码一起看下。。。
元素定位
元素定位大家使用得就比较多了,这里大概列一下常见的元素定位方法。
ID = "id"XPATH = "xpath"LINK_TEXT = "link text"PARTIAL_LINK_TEXT = "partial link text"NAME = "name"TAG_NAME = "tag name"CLASS_NAME = "class name"CSS_SELECTOR = "css selector"
ID
通过id属性定位,一般独立的元素都会有一个id,不同的元素id不同,但由于现在有些页面用的相同的组件,id还是会重复的,所以使用时需注意id是否唯一
driver.find_element(By.ID, 'kw')
当然这里也可以不用By.ID,直接使用“id”,毕竟这些都是常量,只是这样写符合统一规范,人容易看得懂。

NAME
通过name属性定位
driver.find_element(By.NAME, 'wd')
CLASS_NAME
通过class name属性定位,即class属性
driver.find_element(By.CLASS_NAME, 's_ipt').click()
TAG_NAME
通过tag name属性定位,即标签属性,比如下面的输入框,其标签就是input,但是由于一个页面相同tag的元素过多,所以我们一般不使用这个属性
driver.find_element(By.TAG_NAME, 'input')

LINK_TEXT
通过link text属性定位,即链接文字,可跳转的文字。比如百度页面的“新闻”
driver.find_element(By.LINK_TEXT, '新闻').click()

但是要注意,这里不能直接这么用哦,虽然也是链接文字,但是它还有嵌套和兄弟元素,直接用这种方式定位会无法找到

PARTIAL_LINK_TEXT
通过partial link text属性定位,即部分链接文字,有时候文字部分过长,我们可只取其中一部分查找,上面查询失败的“澳门是伟大祖国的一方宝地”,也可以使用这种方式来查询。
driver.find_element(By.PARTIAL_LINK_TEXT, '澳门').click()
XPATH
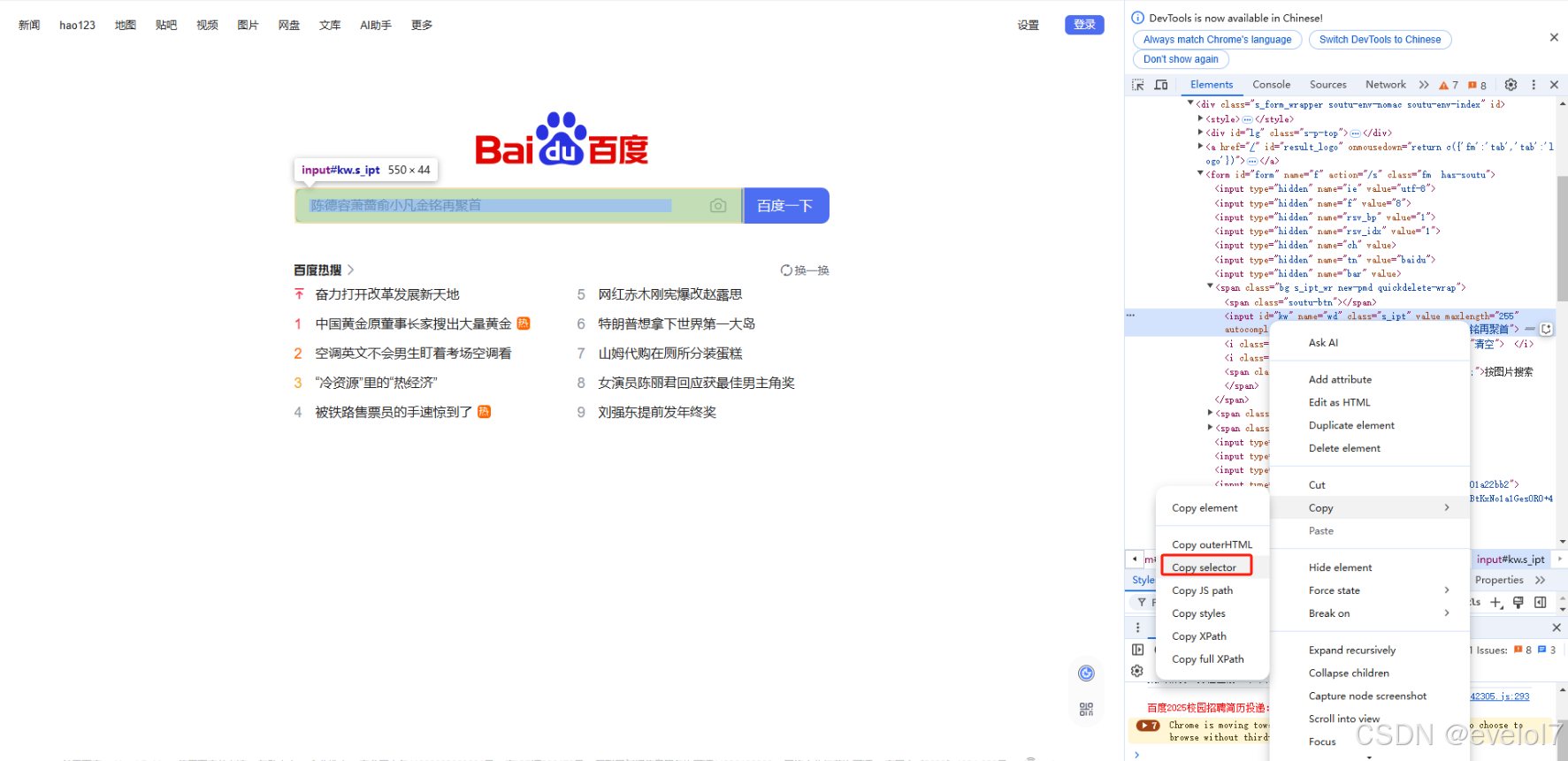
通过xpath来定位元素,我们可以直接在浏览器上复制元素的xpath,如图所示:

//*[@id="kw"] # Copy XPath
/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input # Copy full XPath
一般来说,元素难以定位时,我们会使用xpath,Copy XPath会生成一个相对简单的xpath(相对路径),Copy full XPath会复制绝对路径的xpath。相对路径时,需注意当前页面中有没有同样的相对路径,可能会重复。
当然我们也可以自己写xpath,这里先列一下xpath中各个表达式的意义
| 表达式 | 作用 |
|---|---|
| / | 绝对路径,从根节点选取 |
| // | 相对路径,根据表达式匹配页面中有还是没有符合表达式的元素,可能会匹配多个元素 |
| . | 当前节点 |
| … | 当前节点的父节点(这里是两个点,错误显示成三个点) |
| @ | 选取的属性 |
| [ ] | 进一步的筛选条件 |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| parent:: | 父节点,同…(这里是两个点,错误显示成三个点) |
| child:: | 子节点,同/ |
| ancestor:: | 选取当前节点的所有的直系先辈(父节点,祖父节点) |
| descendant:: | 选取当前节点的所有的直系后辈(子节点,孙子节点) |
| preceding:: | 选取当前节点的开始标签之前的所有节点,且要定位的元素结束标签一定要在当前节点开始标签之前。对于直系先辈的元素是无法定位的,因为直系先辈的结束标签必定在当前节点之后 |
| preceding-sibling:: | 选取当前节点的开始标签之前的所有的同级节点 |
| following:: | 选取当前节点的结束标签之后的所有节点 |
| following-sibling:: | 选取当前节点的结束标签之后的所有同级节点。(只能定位到同级节点) |
属性定位
xpath = "//标签名[@属性='属性值']" # xpath的定位表达式
例如百度的搜索框,可以使用如下以下xpath定位:
//input[@id='kw']
//input[@name='wd']

当然如果一个属性有重复,无法准确定位,我们可以多个属性同时定位
//input[@name='wd' and @class='s_ipt']

当然有时候为了方便,我们也可以不写前面的标签input,直接写成*,*代表匹配所有,只要我们后面的属性定位唯一,写不写前面的input都可以
//*[@name='wd' and @class='s_ipt']

text()定位
我们也可以使用文本进行定位,其和上面介绍的属性定位类似,只是把@属性替换成text()
xpath = "//标签名[text()='属性值']" # xpath的定位表达式
//a[text()='新闻'] # 定位新闻
//*[text()='新闻'] # 定位新闻

模糊定位
有些属性值如果全部输入进去可能太长,而且可能涉及到特殊字符等需要转义,使用时比较麻烦,这时候我们可以使用其中一部分的属性值来匹配,即使用contains()关键字进行模糊匹配:
//a[contains(text(),'新')]
//*[contains(text(),'闻')]

其他属性值也可以用模糊匹配,下面这几种方式都可以匹配“百度一下”这个按键
//*[contains(@value,'百度')]
//*[contains(@type,'sub')]
//input[contains(@id,'s')]

相对位置定位
有时直接定位元素较为困难,我们可以使用相对位置来编写,找到我们需要查找元素的父元素、子元素或兄弟元素等,再根据这些好找的元素定位我们需要的元素。
这里列举一些简单的例子,各个关键字的含义已在上面的列表中列出
parent::
//*[@id='form']/..
//*[@id='form']/parent::* # 注意使用parent::时后面要加*号,这个*号是指的标签属性,*就代表不特指具体标签
//*[@id='form']/parent::div

上面这几个表达式都是指的这个元素
child::
//*[@id='form']/span[1]
//*[@id='form']/child::span[1]
//*[@id='form']/child::span

上面几行都是定位的这个元素,要注意子节点有好几个span,如果我们不指定其index,那默认选择第一个(注意这里的index是从1开始,而非从0开始)
//*[@id='form']/child::* # 注意这里我们不指定标签,则默认定位在第一个子元素

ancestor::
选取当前节点的所有的直系先辈(父节点,祖父节点)
//*[@id='form']/ancestor::div # 默认定位到整个框架的最外面的一个div

//*[@id='form']/ancestor::div[1] # 加上index为1,则定位到外面一层的div上

//*[@id='form']/ancestor::div[2] # 加上index为2,则定位到外面两层的div上

descendant::
选取当前节点的所有的直系后辈(子节点,孙子节点)
//*[@id='form']/descendant::span[1] # 定位子元素中第一个span

//*[@id='form']/descendant::span[2] # 定位子元素中第二个span,但和第一个span不是同级的,而是第一个span的子节点

//*[@id='form']/descendant::span[4] # 定位子元素中第四个span,和第一个span是同级的

由此可见descendant::会将其子节点下所有的元素层级压成一级,然后按顺序排列,不再细分子层级
preceding::
选取当前节点的开始标签之前的所有节点,且要定位的元素结束标签一定要在当前节点开始标签之前。对于直系先辈的元素是无法定位的,因为直系先辈的结束标签必定在当前节点之后
//*[@id='form']/preceding::div[1]

//*[@id='form']/preceding::div[2]

form元素的父节点都未选中,由此可见,选中元素的节点结束标签一定要在当前节点开始标签之前
preceding-sibling::
选取当前节点的开始标签之前的所有的同级节点
//*[@id='form']/preceding-sibling::*

following::
选取当前节点的结束标签之后的所有节点
//*[@id='form']/following::*

//*[@id='form']/following::div[4]

由上图可以看出following::是选择后面的所有节点,而不是同层级的节点,这个得注意。
following-sibling::
选取当前节点的结束标签之后的所有同级节点。(只能定位到同级节点)
//*[@id='form']/following-sibling::div[2]

//*[@id='form']/following-sibling::div[4] # 则无法定位到元素,其只能定位同级元素

CSS_SELECTOR
css selector也是一种常用定位方式,也可以通过页面直接复制
driver.find_element(By.CSS_SELECTOR, "#kw")
当然我们也可以自己编写,先列一下各个表达式的含义
| 表达式 | 作用 |
|---|---|
| # | 后接id属性 |
| . | 后接class属性 |
| [] | 其他具体属性 |
| > | 后接子元素 |
| 空格 | 后接直系子孙元素 |
| + | 后接同级元素(紧挨着的) |
| ~ | 后接同级元素 |
| :first-child | 取父标签下第1个元素 |
| :last-child | 取父标签下最后一个元素 |
| :nth-child(n) | 取父标签下的第n个元素(n从1开始) |
| :nth-last-child(n) | 取父标签下倒数第n个元素 |
天色已晚,具体使用方法后面我们再补充。。。