索引-介绍结构语法
一.概述:
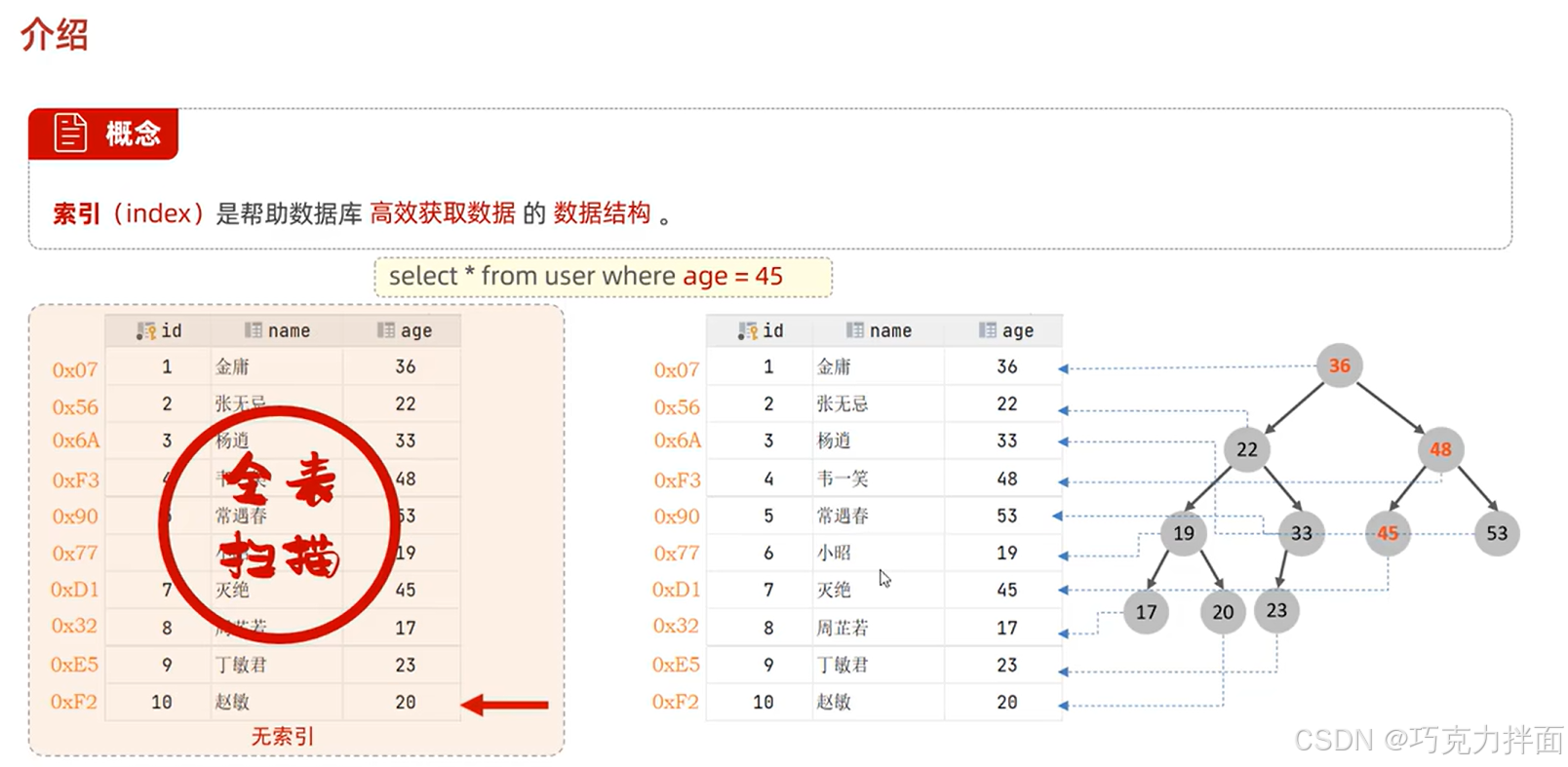
1.当给某个字段创建索引后,就会把字段生成二叉排序树进行查找,大大增加了查找效率,比不创建索引时用的全表扫描好得多。
2.二叉排序树:小的在左边,大的在右边(查找和存放都遵循这个原则)。
3.注:二叉排序树仅仅是一个示意图,并不是索引真正的底层结构。
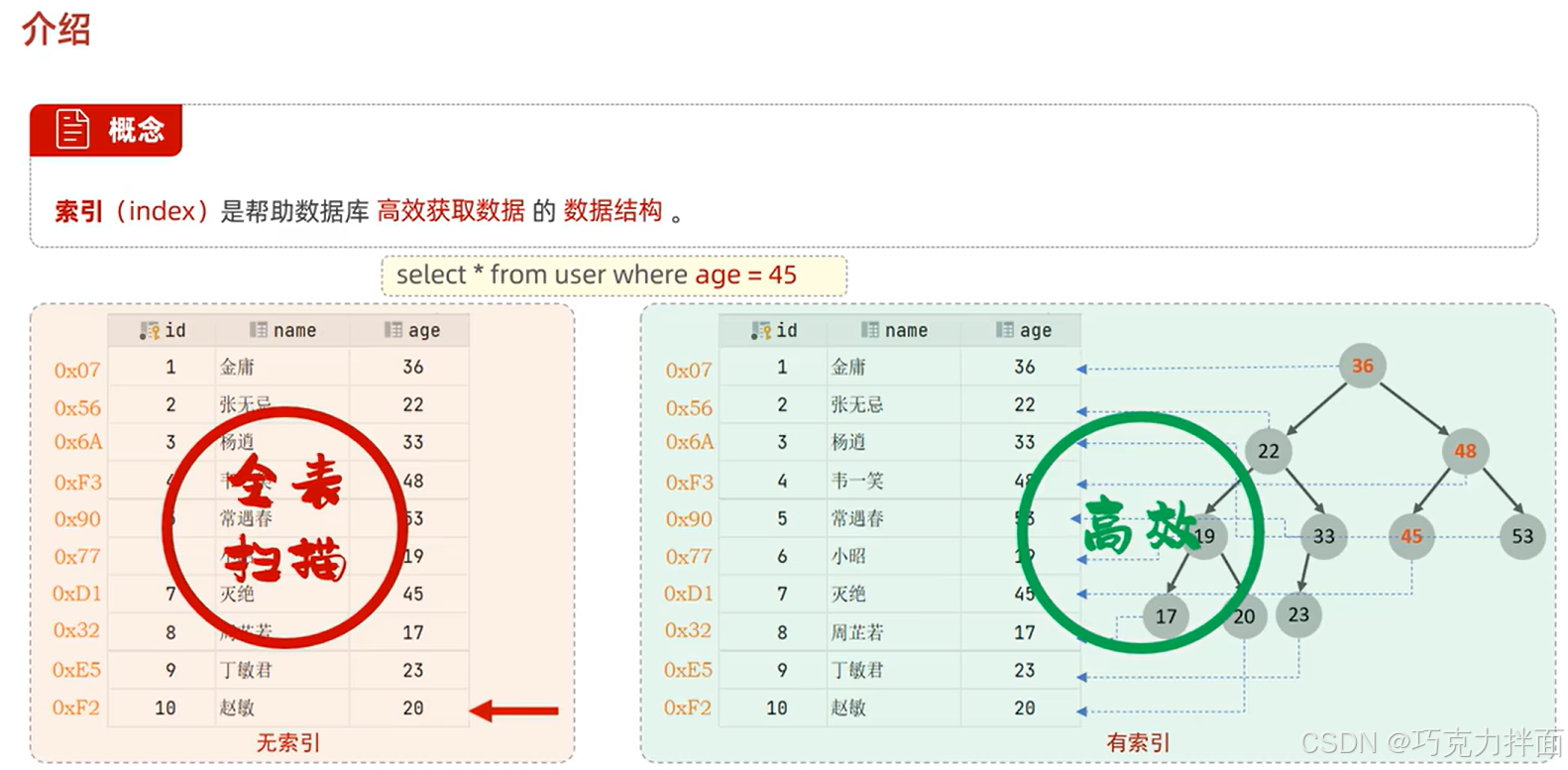
4.索引相当于一本书中的目录,有目录时很好找,没有目录时只能全书找。
二.数据库的优点和缺点:

1.优点:提升数据库查询的效率,提高数据库排序的效率。
2.缺点:索引会占用存储空间(但占的空间一般不大);索引大大提高了查询效率,但同时降低了增,删,改的效率,这是因为在进行增,删,改的操作时数据会发生变化,此时就需要重新维护索引创建的二叉排序树这个数据结构->在创建索引后,增,删,改就不益用了。
三.结构:
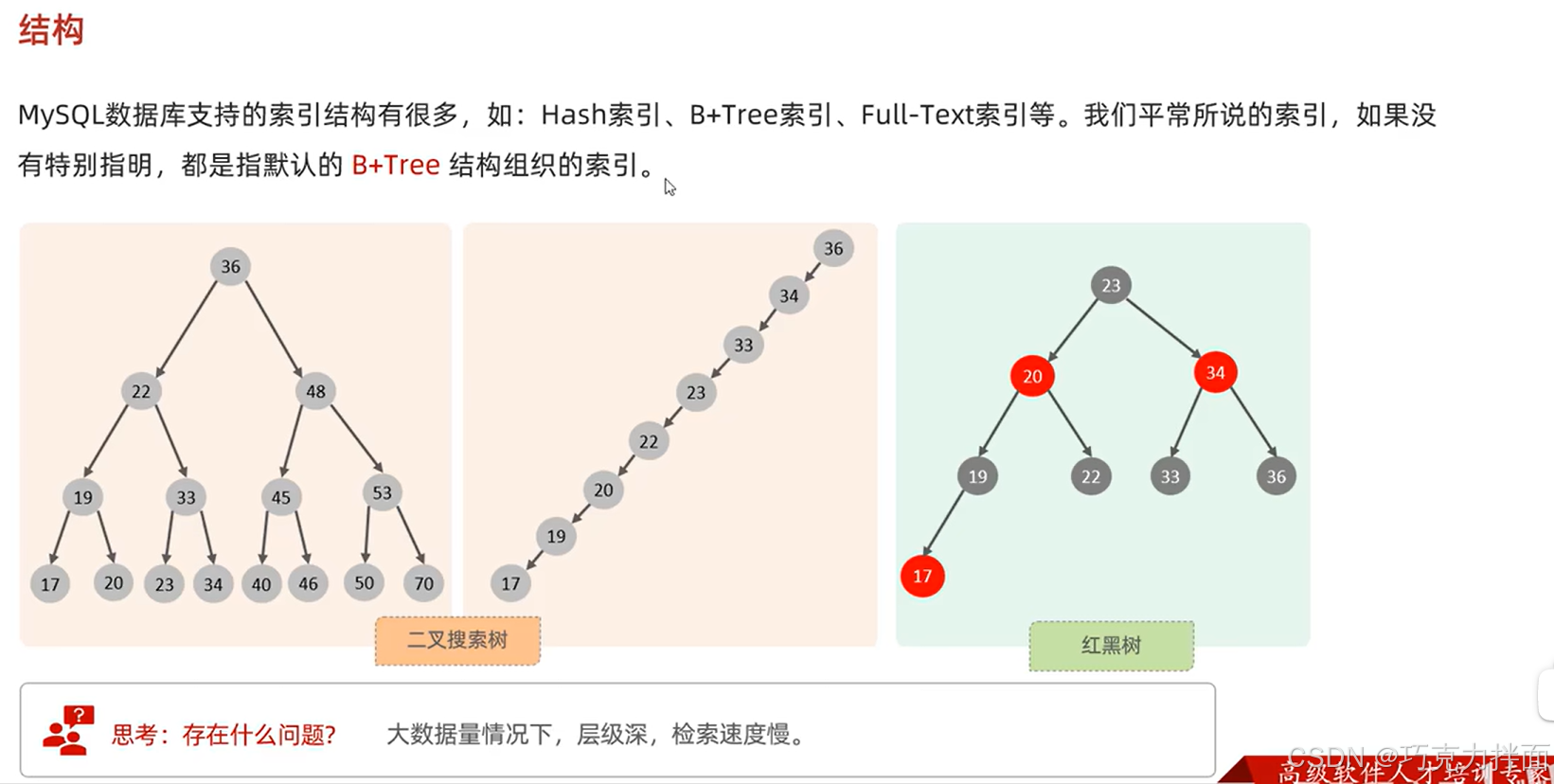
1.红黑树也是平衡二叉树;
2.索引结构为什么不采用二叉搜索树和红黑树呢?原因是在数据量较大的情况下,层级会很深,导致检索(查找)速度慢;
3.B+(B+Tree)树中一个结点可以存储多个键值(key),存储了几个键值,下面就会有几个指针,就会有几个子结点,这样相对于平衡二叉树和红黑树,相同数据量的情况下,B+树的高度就会低很多,查找效率也就高很多;
4.页是数据库进行磁盘管理的最小单位,一个页的大小为16KB;
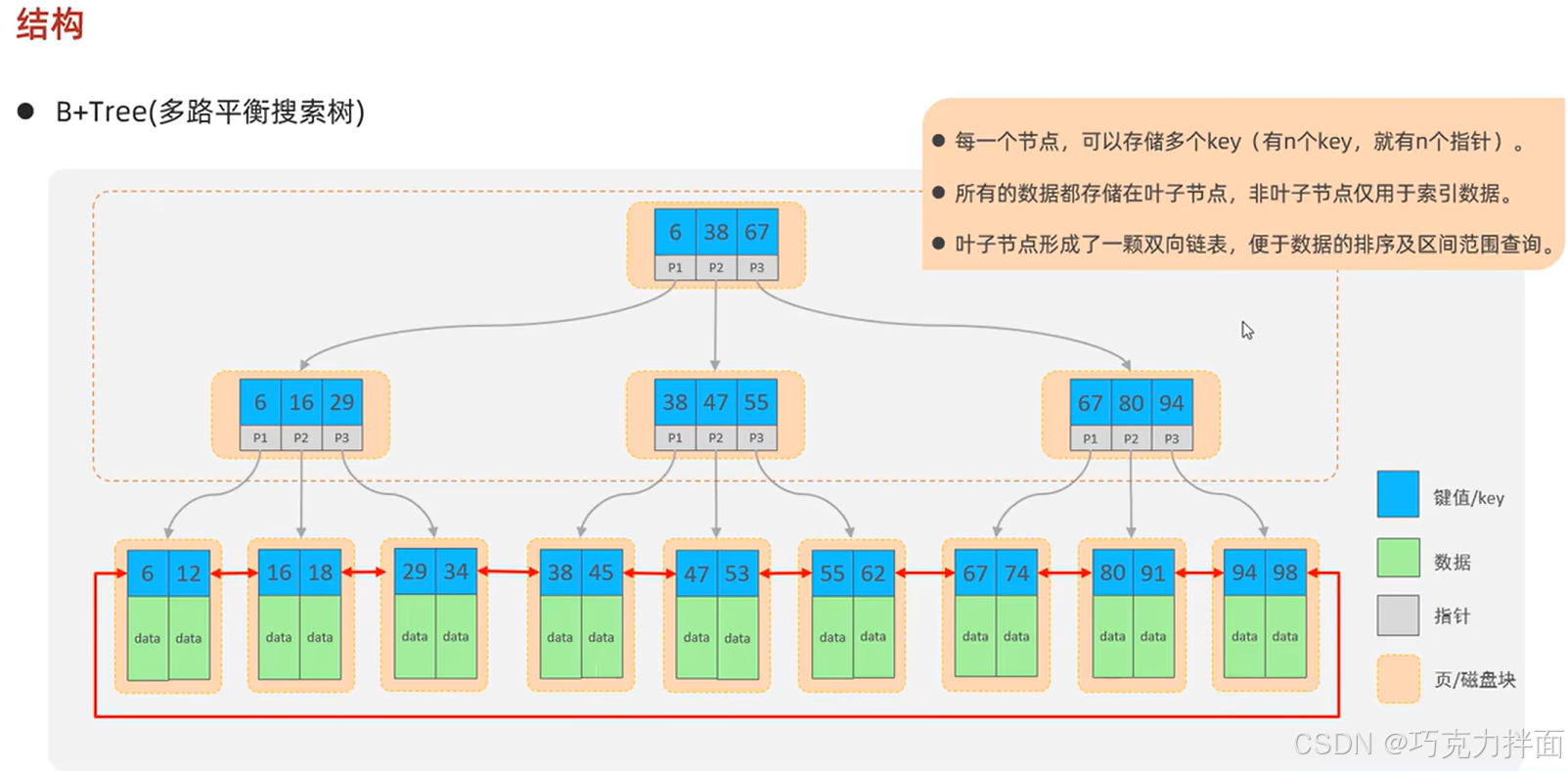
5.B+树的非叶子结点仅仅起到索引(查找)数据的作用,并不保存具体的数据,所有的数据都存储在叶子结点(最底下的结点)中,所有的key都会出现在叶子结点,这样能保证数据库服务器的查询性能稳定:
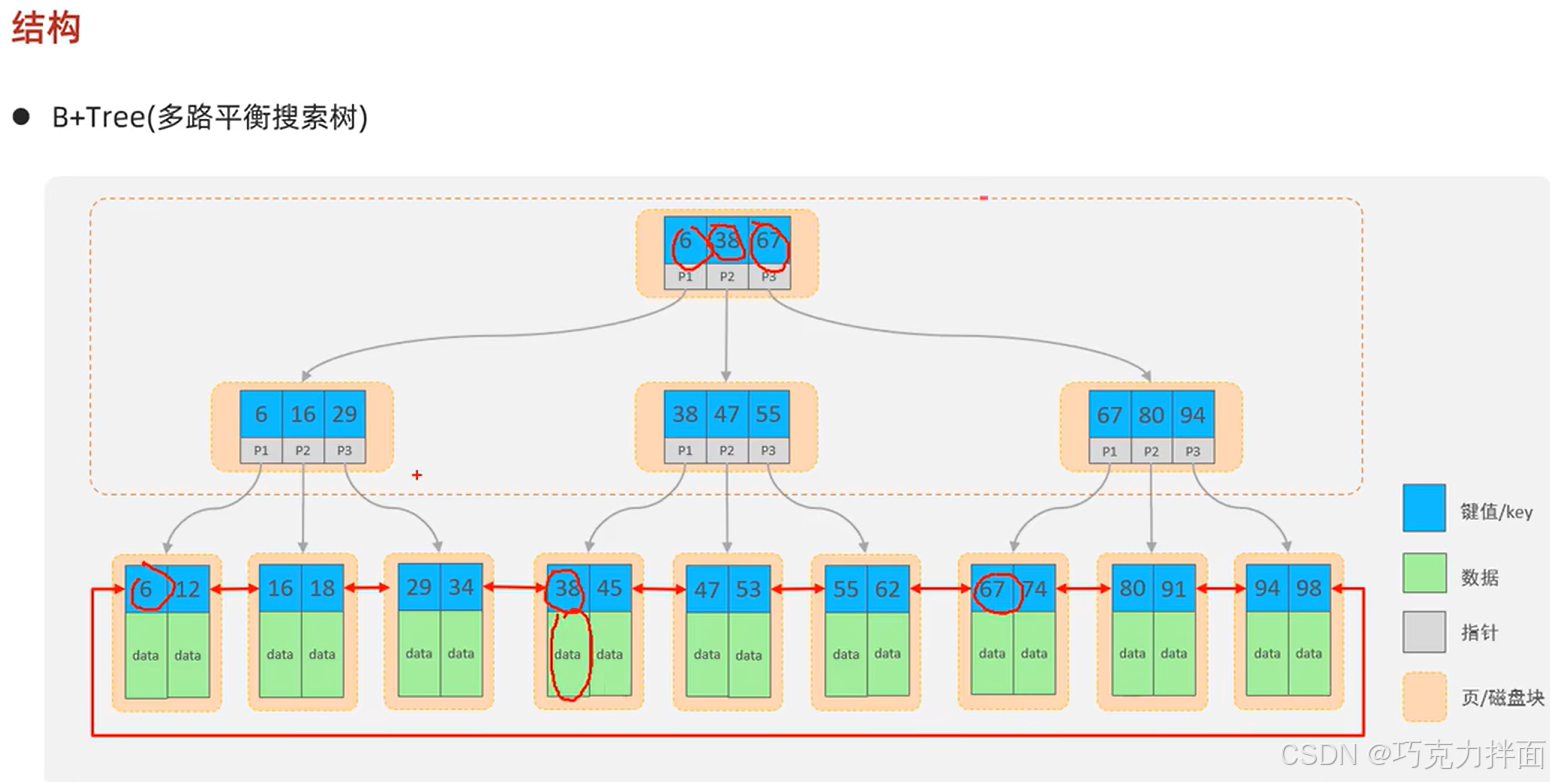
6.由于B+树是多路平衡搜索树,所以该树的叶子结点元素是按照元素从小到大的顺序排序的(从左向右),而且在叶子结点中的元素形成了一个双向链表(是有序的),由上一个元素可以找到下一个元素,也可以由下一个元素找到上一个元素;
7.比如查找元素53,首先查找根结点,每一个结点中查找是利用二分查找,发现53大于等于38,小于67的,所以走P2指针,到下一个磁盘块,发现53大于等于47,小于55的,所以走P2指针,继续到下一个磁盘块查找,最终找到了53并获取到对应的数据:
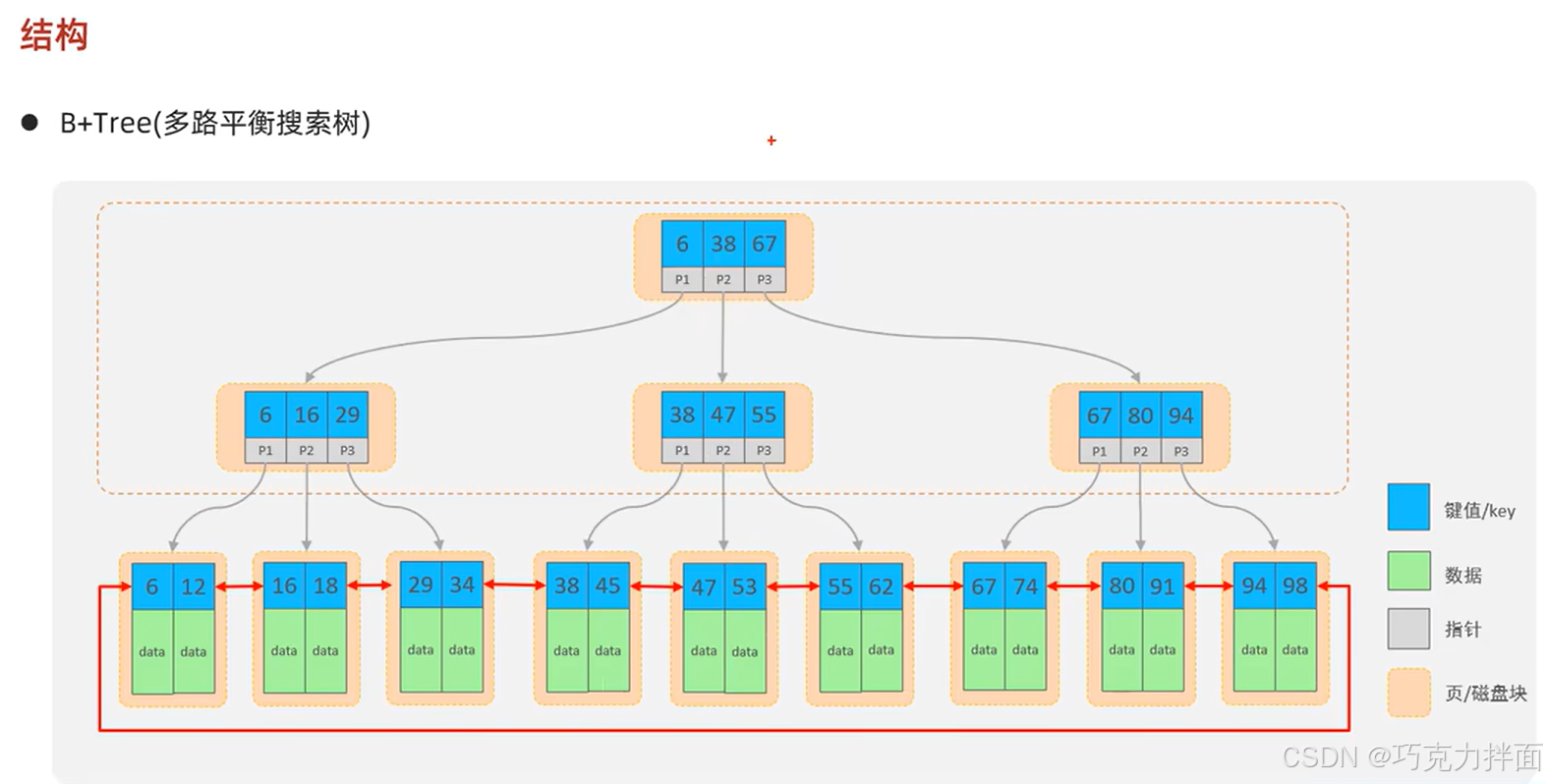
比如查找元素29,根结点中29大于等于6,小于38,所以走P1指针,到下一个磁盘块,发现了29,直接走P3指针,走向下一个磁盘块,最终找到了29并获取到对应的数据(只需要进行3次磁盘IO就找到了对应的数据);
四.语法:
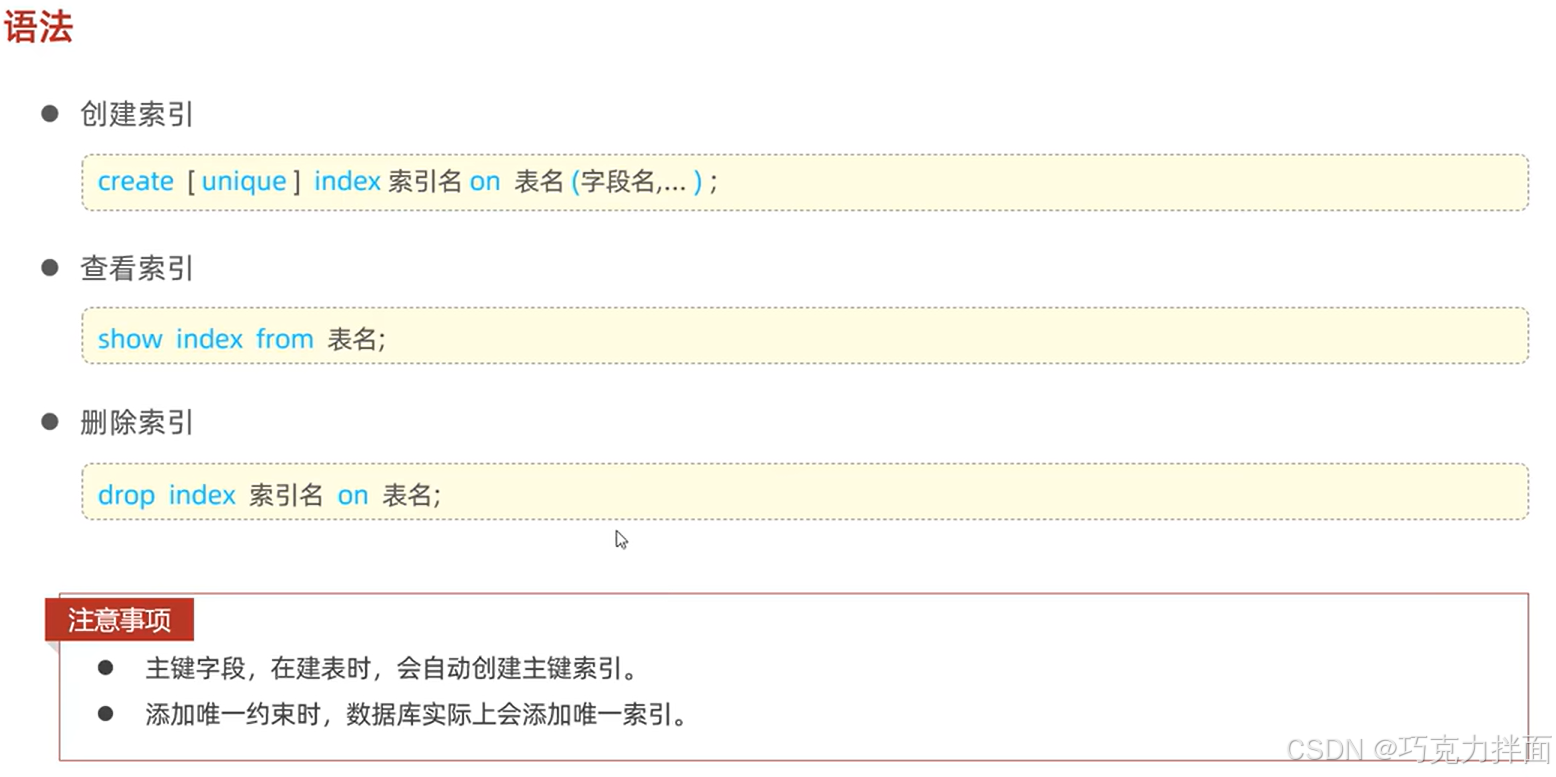
1.创建唯一索引加unique即字段被unique修饰(唯一索引不是一个字段的意思),后面的多个字段名之间用逗号分隔;
五.代码演示:
1.创建索引:
-- 创建:为tb_emp表的name字段创立一个索引
create index idx_emp_name on tb_emp(name);2.查看索引:
-- 创建:为tb_emp表的name字段创立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询:查询tb_emp表的索引信息
show index from tb_emp;运行结果:
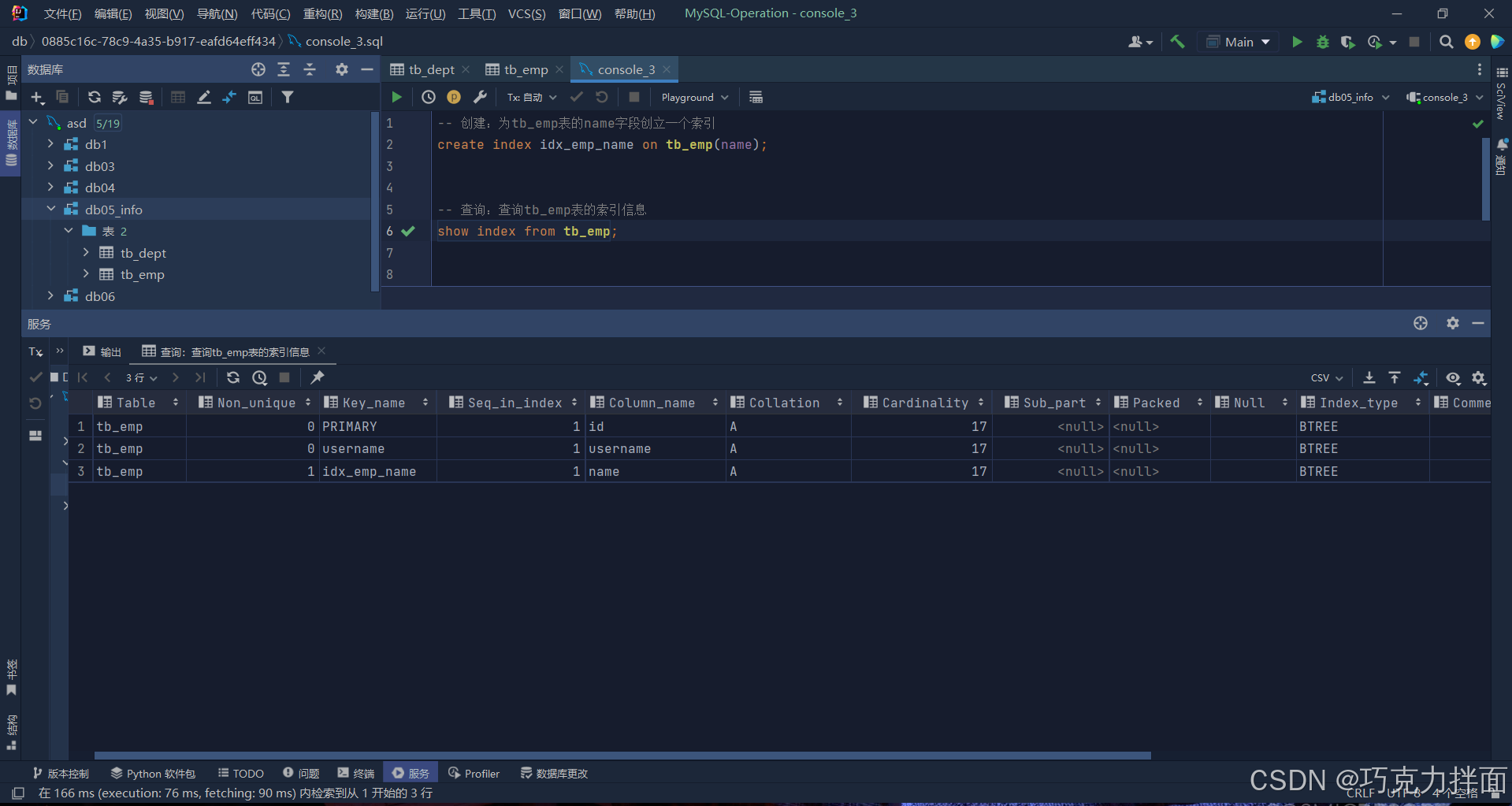
发现结果有3条记录,但创建索引时只创建了一个索引idx_emp_name ->
第一个索引PRIMARY对应的字段名为id,id为什么会有索引呢?因为id为主键,一旦指定了某个字段为某一张表的主键,他就会自动创建一个索引(也是数据库默认创建的一个主键索引),该索引称为主键索引,而且主键索引的性能是最高的;
第二个索引username,是因为字段username是唯一(unique)的,一旦指定了某个字段是唯一的,数据库就会自动的给该字段创建一个唯一索引即unique index:所以唯一约束本质就是唯一索引
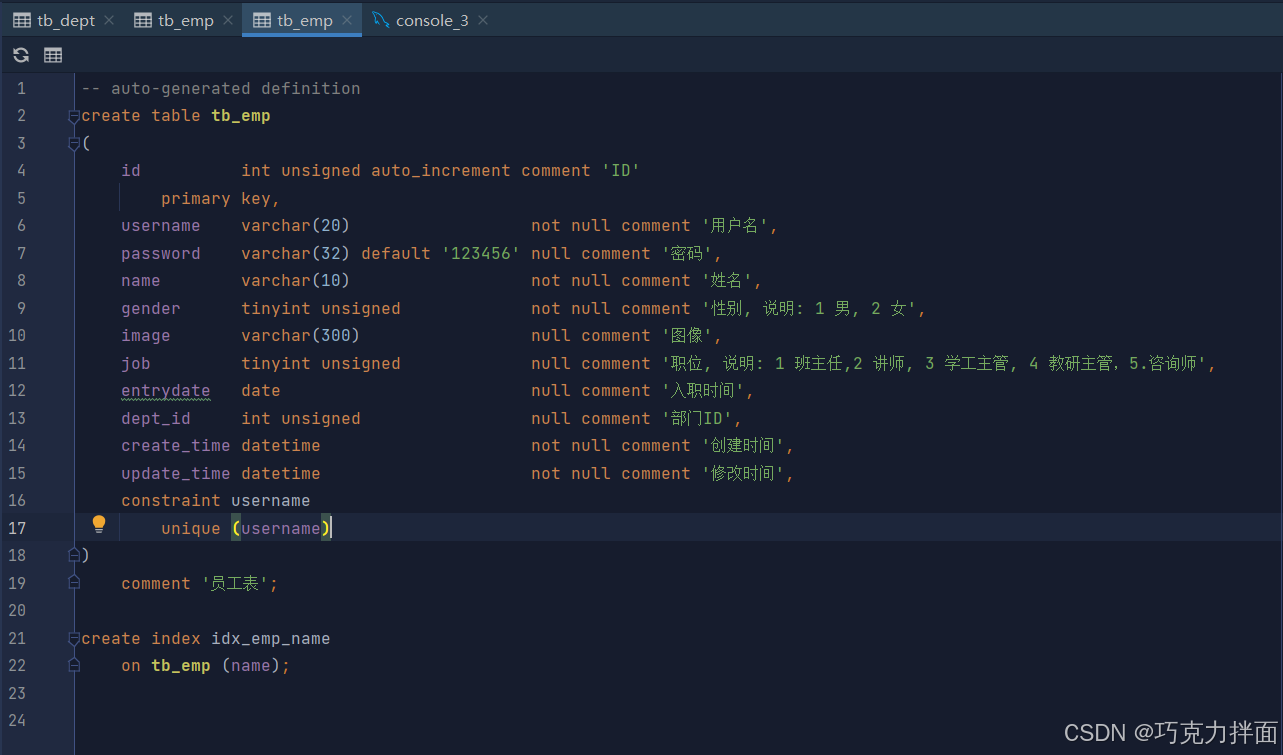
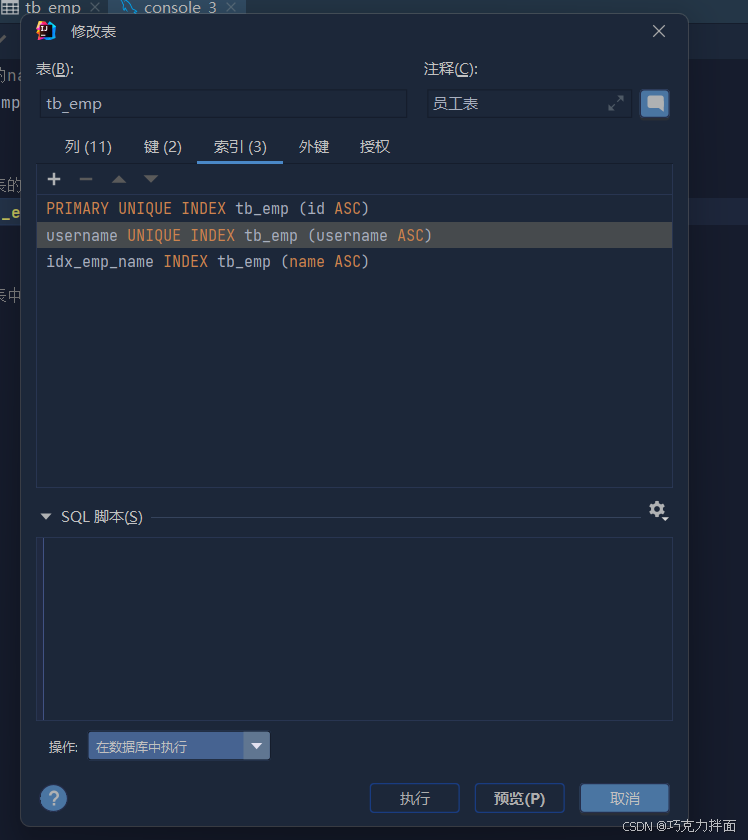
第三个索引idx_emp_name就是刚才创建的索引;
3.删除索引:
-- 创建:为tb_emp表的name字段创立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询:查询tb_emp表的索引信息
show index from tb_emp;
-- 删除:删除tb_emp表中name字段的索引
drop index idx_emp_name on tb_emp;运行结果:
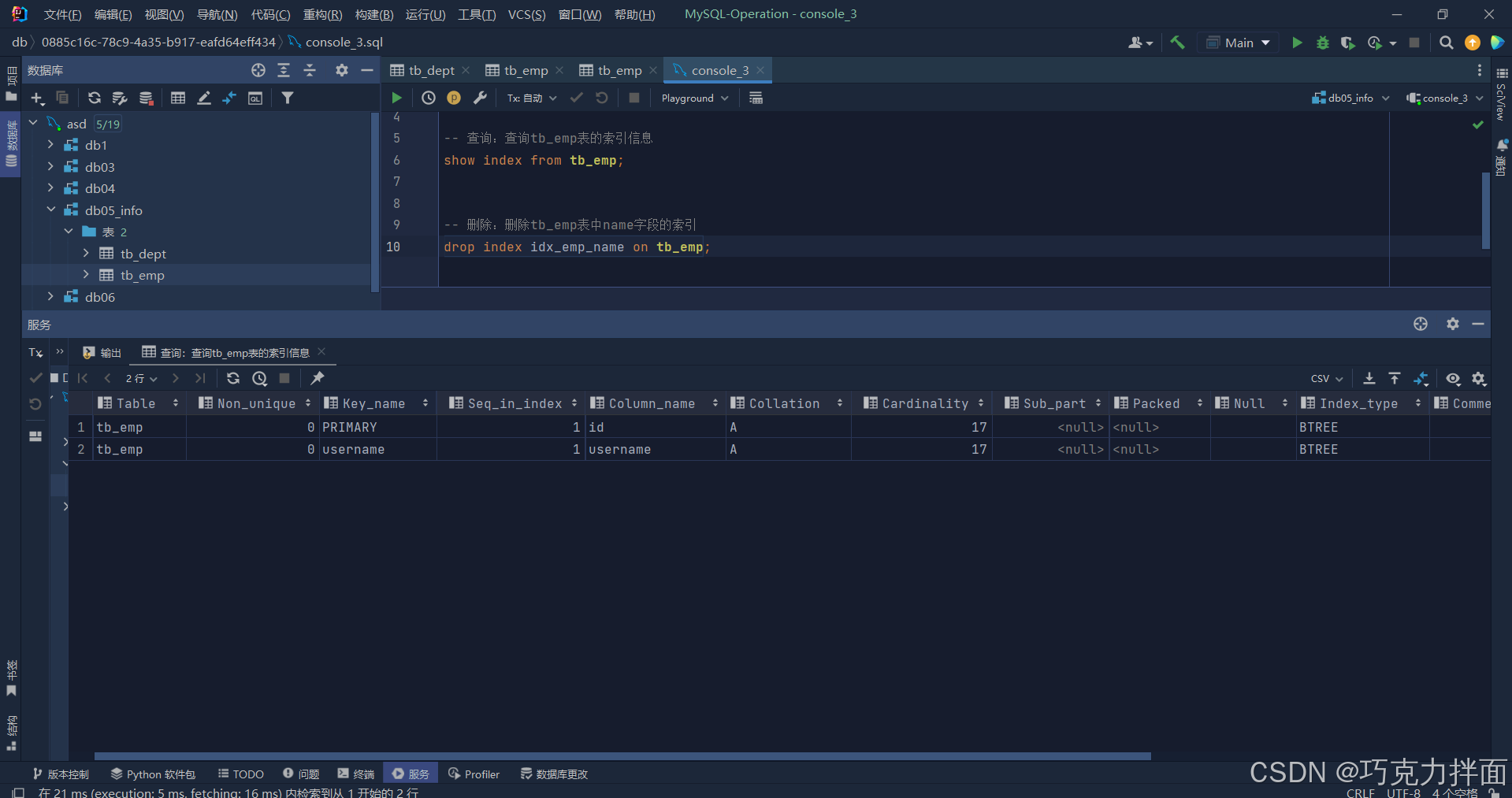
六.总结:
