【操作系统】实验七:显示进程列表
实验7 显示进程列表
练习目的:编写一个模块,将它作为Linux内核空间的扩展来执行,并报告模块加载时内核的当前进程信息,进一步了解用户空间和内核空间的概念。
7.1 进程
进程是任何多道程序设计的操作系统中的基本概念。为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。例如,内核必须知道进程的优先级,它是正在CPU上运行还是因某些事件被阻塞,给它分配什么样的地址空间,允许它访问哪个文件等等。这正是进程描述符(process descriptor)的作用进程描述符都是task_struct 类型结构,它的域包含了与一个进程相关的所有信息。因为进程描述符中存放了那么多信息,所以它是相当复杂的。它本身不仅包含了很多域,而且一些域还包括了指向其他数据结构的指针,依此类推。
为了对给定类型的进程(例如,在可运行状态的所有进程)进行有效的搜索,内核建立了几个进程链表。有一个双向循环链表(参见图7.1)把所有现有的进程联系起来,我们叫它为进程链表(process list)。每个进程的prev_task和next_task域用来实现链表。init_task指向描述符链表的头。另外,宏current总是指向CPU的当前进程。
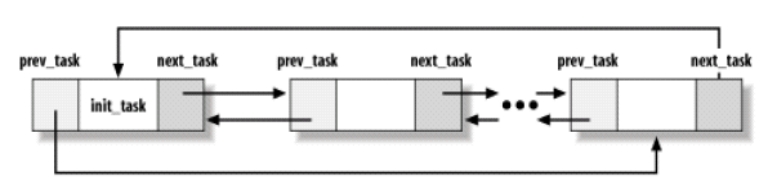
图7.1 进程链表
7.2 用户空间和内核空间
模块运行在所谓的内核空间(Kernel space)里,而应用程序运行在所谓的用户空间里(User space)中,这个概念是操作系统理论的基础之一。
我们通常将执行模式称作内核空间和用户空间。这两个术语不仅说明两种模式具有不同的优先权等级,而且还说明每个模式都有自己的内存映射,即自己的地址空间。
每当应用程序执行系统系统调用和被中断挂起时,Unix将执行模式从用户空间切换到内核空间,执行系统调用的内核代码运行在进程上下文中,它代表调用进程执行操作,因此能够访问进程地址空间的所有数据;而处理硬件中断的内核代码则和进程是异步的,因而与任何一个特定进程都无关。
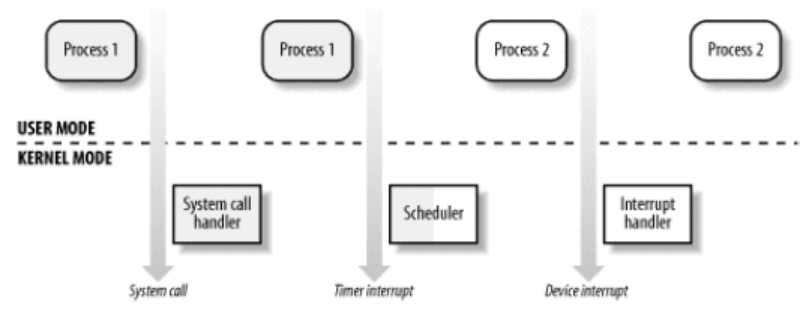
图7.2 用户空间和内核空间切换的示例
7.3 问题陈述
设计并实现一个模块,遍历进程描述符链表,打印出系统的进程数目、当前进程,并尽量多地打印每个进程的信息。
7.3.1部分A
查看系统已加载模块。写一个小的模块打印“hello world”。
7.3.2部分B
设计模块遍历进程描述符链表,打印出系统的进程数目、当前进程,并尽量多地打印每个进程的信息。例如:进程PID,进程状态等。
7.3.3部分C(可选)
使用模块实现一个系统调用(也实现遍历进程链表的功能),并编写一个用户程序测试,体会利用模块从而带来的不用重新编译内核,测试方便等好处。
7.4 解决问题
7.4.1部分A
查看系统已加载模块。写一个小的模块打印“hello world”
使用命令lsmod查看已加载模块,如图7.3所示
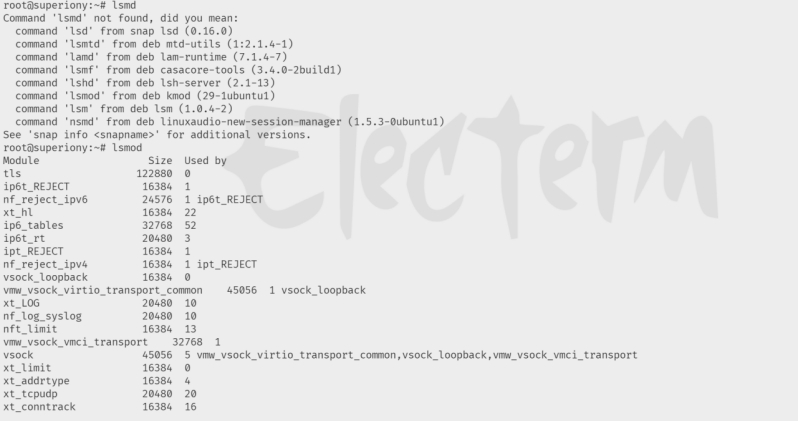
图7.3 查看系统当前已加载模块
写一个小的模块打印“hello world!”,创建一个course_devise文件夹,并进入该文件夹,如图7.4所示

图2.4 创建文件夹并进入此文件夹
创建一个C语言文件,命名为hello.c文件,文件代码如下:
#include <linux/module.h>
#include <linux/kernel.h>MODULE_LICENSE("GPL");
MODULE_AUTHOR("20223626");
MODULE_DESCRIPTION("这是一个小的hello world!模块");
static int __init hello_init(void) {printk(KERN_INFO "Hello, World!\n");return 0;
}static void __exit hello_exit(void) {printk(KERN_INFO "Goodbye, World!\n");
}
module_init(hello_init);
module_exit(hello_exit);
创建好了之后,如图7.5所示
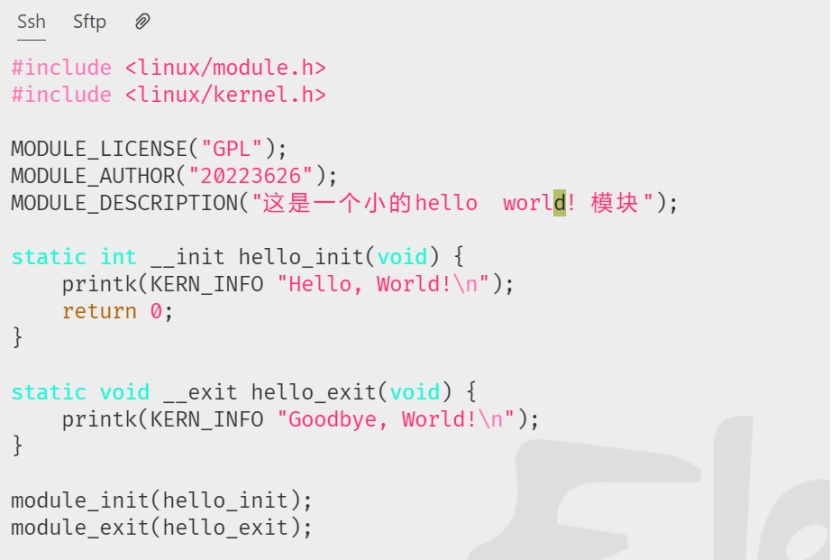
图7.5 创建hello.c文件
接下来就是创建Makefile文件,注意是使用TAB制表符,不是空格,文件代码如下:
obj-m += hello.oall:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modulesclean:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
创建好了如图7.6所示

图7.6 创建Makefile文件
使用make命令开始编译模块,编译完成之后,如图7.7所示
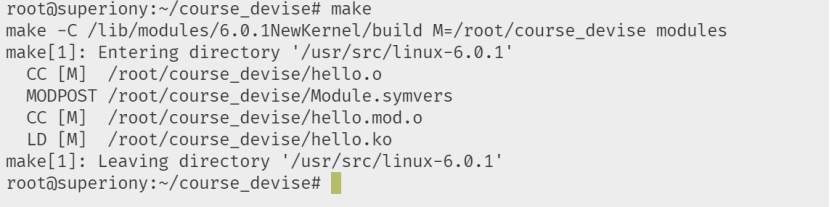
图7.7 编译模块成功
再使用sudo insmod hello.ko加载模块
加载完模块之后,使用dmesg | tail查看内核日志,如图7.8所示:

图7.8 加载模块成功
使用sudo rmmod hello卸载模块
卸载完模块之后,使用dmesg | tail查看内核日志,如图7.9所示:

图7.9 卸载模块成功
7.4.2部分B
设计模块遍历进程描述符链表,打印出系统的进程数目、当前进程,并尽量多地打印每个进程的信息。例如:进程PID,进程状态等。
- 编写一个C语言文件,命名为process_info.c,代码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <linux/init.h>MODULE_LICENSE("GPL");
MODULE_AUTHOR("20223626");
MODULE_DESCRIPTION("这是一个打印进程信息的模块");static int __init process_info_init(void) {struct task_struct *task;int process_count = 0;//初始化进程数量为0// 遍历进程链表for_each_process(task) {process_count++;printk(KERN_INFO "进程ID: %d, 状态: %ld, 名字: %s\n",task->pid, task->__state, task->comm);}// 打印当前进程信息printk(KERN_INFO "当前进程ID: %d, 状态: %ld, 名字: %s\n",current->pid, current->__state, current->comm);// 打印进程总数printk(KERN_INFO "进程总数: %d\n", process_count);return 0;
}static void __exit process_info_exit(void) {printk(KERN_INFO "退出进程信息模块!\n");
}module_init(process_info_init);
module_exit(process_info_exit);
- 编写完代码如图7.10所示:

图7.10 process_info.c的代码内容
- 在同一目录下创建一个名为 Makefile 的文件,内容如下:
obj-m += process_info.oall:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modulesclean:make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
- 编写完Makefile之后,如图7.11所示:

图7.11 Makefile的代码内容
- 使用make开始编译模块,编译完之后,如图7.12所示,使用sudo insmod process_info.ko加载模块

图7.12 模块编译成功
- 加载完模块之后,使用dmesg查看信息如图7.13所示:

图7.13 查看进程信息
- 卸载模块,使用命令rmmod process_info.ko,如图7.14所示:

图7.14 卸载process_info模块
- 输入dmesg | tail命令查看信息,如图7.15所示:
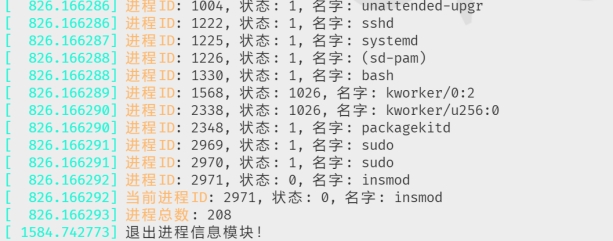
图7.15 Makefile的代码内容
7.4.3部分C(可选)
使用模块实现一个系统调用(也实现遍历进程链表的功能),并编写一个用户程序测试,体会利用模块从而带来的不用重新编译内核,调试方便等好处。
步骤如下:
- 写一个mymod.c,代码如下:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/sched.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>// 该宏用于声明内核模块的基本信息
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("A Simple Linux Kernel Module for Traversing Process List");// 函数声明
static int process_list_show(struct seq_file *m, void *v);
static int process_list_open(struct inode *inode, struct file *file);// 定义文件操作结构体
static const struct proc_ops process_list_fops = {.proc_open = process_list_open,.proc_read = seq_read,.proc_lseek = seq_lseek,.proc_release = single_release,
};// 在/proc目录下创建一个虚拟文件
static int __init process_list_init(void)
{proc_create("process_list", 0, NULL, &process_list_fops);pr_info("Process list module loaded\n");return 0;
}static void __exit process_list_exit(void)
{remove_proc_entry("process_list", NULL);pr_info("Process list module unloaded\n");
}// 打开文件时的回调函数
static int process_list_open(struct inode *inode, struct file *file)
{return single_open(file, process_list_show, NULL);
}// 遍历进程链表并显示信息
static int process_list_show(struct seq_file *m, void *v)
{struct task_struct *task;// 遍历所有进程for_each_process(task) {seq_printf(m, "PID: %d, Name: %s\n", task->pid, task->comm);}return 0;
}module_init(process_list_init);
module_exit(process_list_exit);
写好代码如图7.16所示:
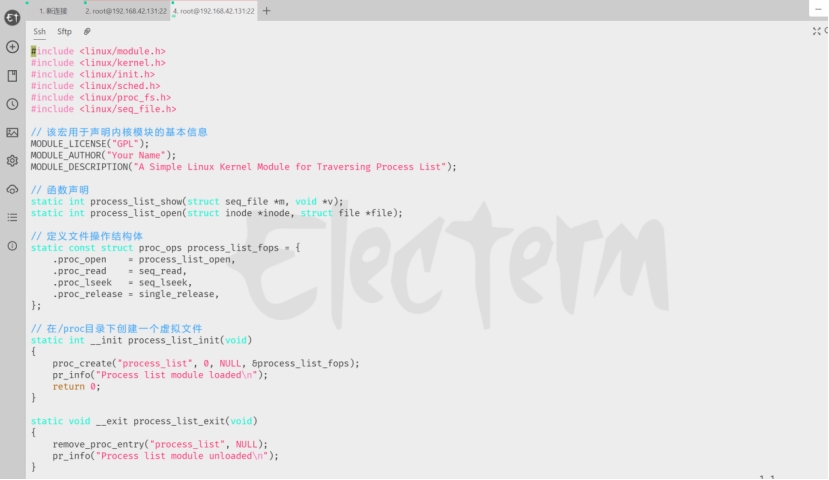
图7.16 mymod.c的内容
- 在同一目录下创建Makefile文件,注意,Makefile文件里的make前面的空一定要使用TAB,而不是空格,代码如下所示:
KVERS = $(shell uname -r)# Kernel modulesobj-m += mymod.obuild: kernel_moduleskernel_modules:make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modulesclean:make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
编写完Makefile文件如图7.17所示:
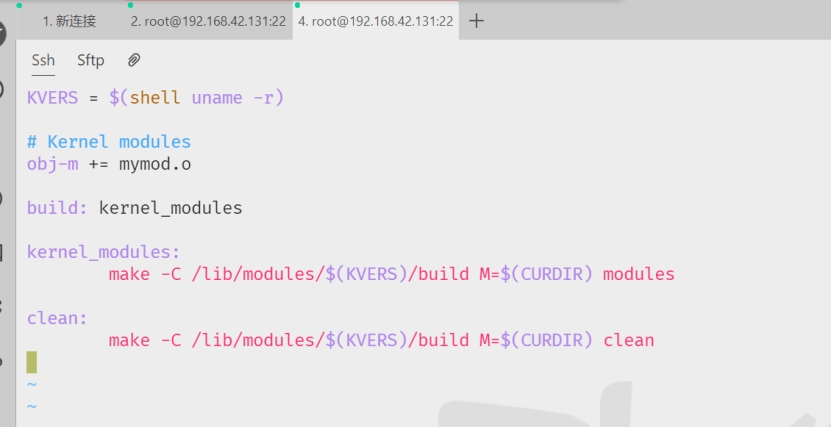
图7.17 Makefile的代码内容
- 使用make指令开始编译模块,编译完之后,如图7.18所示
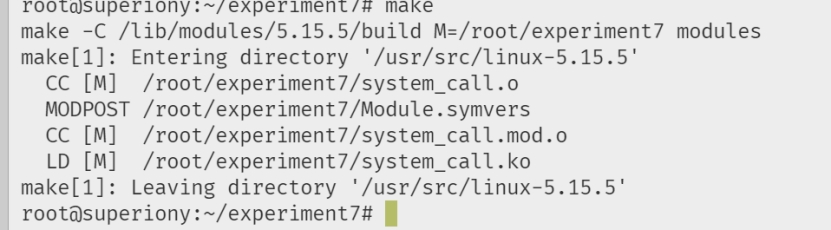
图7.18 编译完之后的结果
- 写一个用户程序test_proc_list.c测试,代码如下:
#include <stdio.h>
#include <stdlib.h>int main() {FILE *fp;char buffer[256];// 打开/proc/process_list文件fp = fopen("/proc/process_list", "r");if (fp == NULL) {perror("Failed to open /proc/process_list");return 1;}// 读取并输出每一行while (fgets(buffer, sizeof(buffer), fp) != NULL) {printf("%s", buffer);}fclose(fp);return 0;}
- 开始加载模块,使用命令insmod mymod.ko,加载好了之后,使用gcc -o test_proc_list test_proc_list.c开始编译用户文件,编译好了之后,使用./test_proc_list执行用户文件,执行完之后如7.19所示:
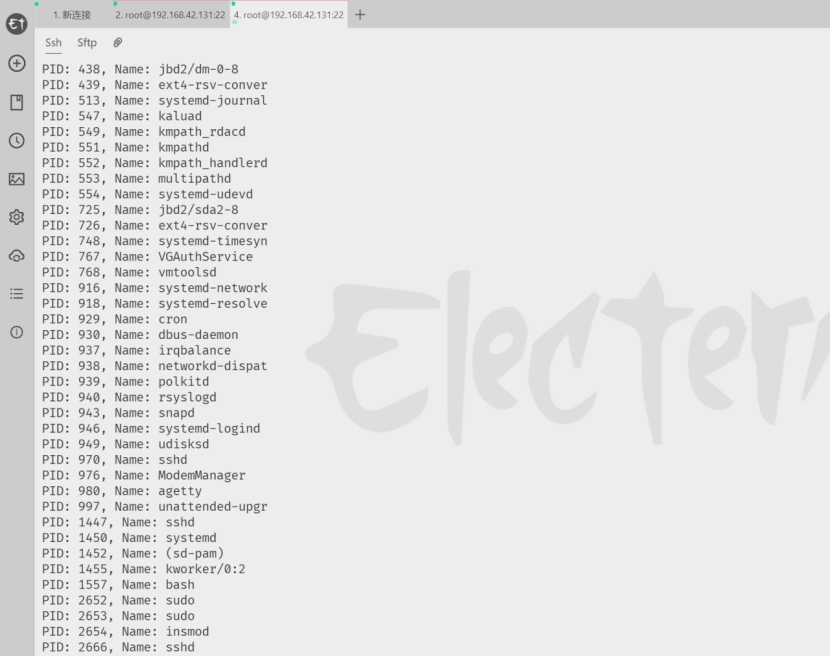
图7.19 执行完test_proc_list之后的结果
7.5 实验总结
1.模块加载与卸载: 本次实验首先学习了如何编写和加载一个简单的 Linux 内核模块,通过打印“hello world”来验证模块的基本功能。这一过程涉及到使用 module_init 和 module_exit 宏,确保模块能够正确加载和卸载。在加载模块后,通过 dmesg 命令查看内核日志,确认输出信息。
2.遍历进程描述符链表: 在实验的第二部分,设计了一个模块来遍历进程描述符链表。使用 for_each_process 宏,可以遍历系统中所有的进程,并打印出每个进程的详细信息,包括进程 ID、状态、名称等。通过这种方式,能够直观地了解系统中正在运行的进程及其状态。
3.进程信息的输出: 为了确保输出的信息尽量丰富,模块中实现了对每个进程的详细打印。除了基本的 PID 和状态,还可以扩展打印其他信息,如优先级、父进程 ID 等。这种信息的收集和展示有助于理解系统资源的使用情况和进程管理的机制。
4.实验收获与反思: 通过本次实验,深入理解了 Linux 内核模块的基本结构和功能,掌握了进程管理的基本概念。实践中发现,内核模块的开发需要对内核数据结构有一定的了解,同时也要注意内核与用户空间的区别。未来可以进一步探索更多的内核功能,如信号处理、内存管理等,以加深对 Linux 内核的理解。