pandas一行拆成多行
import pandas as pd
df = pd.DataFrame({'Country':['China','US','Japan','EU','UK/Australia', 'UK/Netherland'],'Number':[100, 150, 120, 90, 30, 2],'Value': [1, 2, 3, 4, 5, 6],'label': list('abcdef')})# 法一 推荐
df2=df.drop('Country', axis=1).join(df['Country'].str.split('/', expand=True).stack().reset_index(level=1, drop=True).rename('Country'))
df.drop('Country', axis=1).join(df['Country'].str.split('/', expand=True).stack().reset_index(level=1, drop=True).rename('Country'))
print(df2)
#法二
tmp =df.set_index(["Number", "Value", "label"])["Country"].str.split("/", expand=True).stack()
result = tmp.reset_index(drop=True, level=-1).reset_index()
result = result.rename(columns={0: 'Country222222'})print(df)
print(result)

说明
- df.drop()通过指定标签名称和相应的轴,或直接给定索引或列名称来删除行或列,axis:轴的方向,0为行,1为列,默认为0
- stack()函数:“逆透视”就是将索引,特别是将列名转换为普通的列,方便后期计算,这个在excel里面叫做二维表转换为一维表。




3.pivot_table()透视
# 1. 单层统计 -- 根据名称分组统计不同颜色的数量总和
table = pd.pivot_table(df, values="数量", index="名称", columns="颜色", aggfunc=np.sum)
table2. fill_value参数:设定fill_value=0: 缺失值充填为0;marigins 参数:设定margins=True: 对行和列的数据进行统计输出
# 2. 单层统计 -- 根据名称分组统计不同颜色的数量平均值
table = pd.pivot_table(df, values="数量", index="名称", columns="颜色", aggfunc="mean", fill_value=0, margins=True)
table3. columns参数:传入列表,相当于同时对多个特征进行分类统计
# 3. 复合统计1 - 根据名称分组统计不同颜色和尺寸的数量总和
table = pd.pivot_table(df, values="数量", index="名称", columns=["颜色", "尺寸"], aggfunc="sum", fill_value=0,margins=True)
table4. index参数:传入一个列表,**就是相当于进行多层级的分组**
# 4. 复合统计2 - 根据名称和大小分组统计不同颜色的数量总和
table = pd.pivot_table(df, values="数量", index=["名称", "尺寸"], columns=["颜色"], aggfunc="sum", fill_value=0, margins=True)
table5. aggfunc参数: 聚合函数可以是函数,函数列表,字典。如果传递的是字典,则健为要聚合的列,值是函数或函数列表。聚合函数可包括:mean(平均值), sum(求和), max(最大值), min(最小值), size(计数), var(方差),std(标准差), median(中位数) 等。
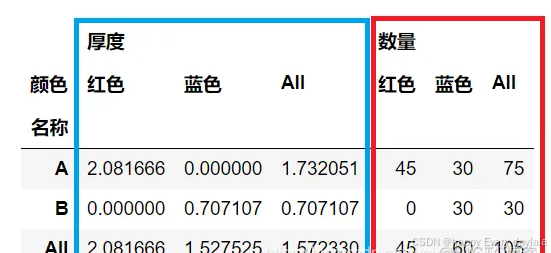
# 5.复合统计3 - 根据名称统计不同颜色的数量总和,以及厚度的标准差
# 为方便演示,加入1新特征厚度值
df["厚度"] = [2, 5, 1, 2, 4, 5]
table = pd.pivot_table(df, values=["数量", "厚度"], index="名称", columns=["颜色"], aggfunc={"数量": np.sum, "厚度": np.std}, fill_value=0, margins=True)
table