什么是聚簇索引、非聚簇索引、回表查询
其实聚集索引也叫聚簇索引,二级索引也叫非聚簇索引,大家不要认为这是不同的两个知识点。
定义
先看一下数据库的索引介绍。

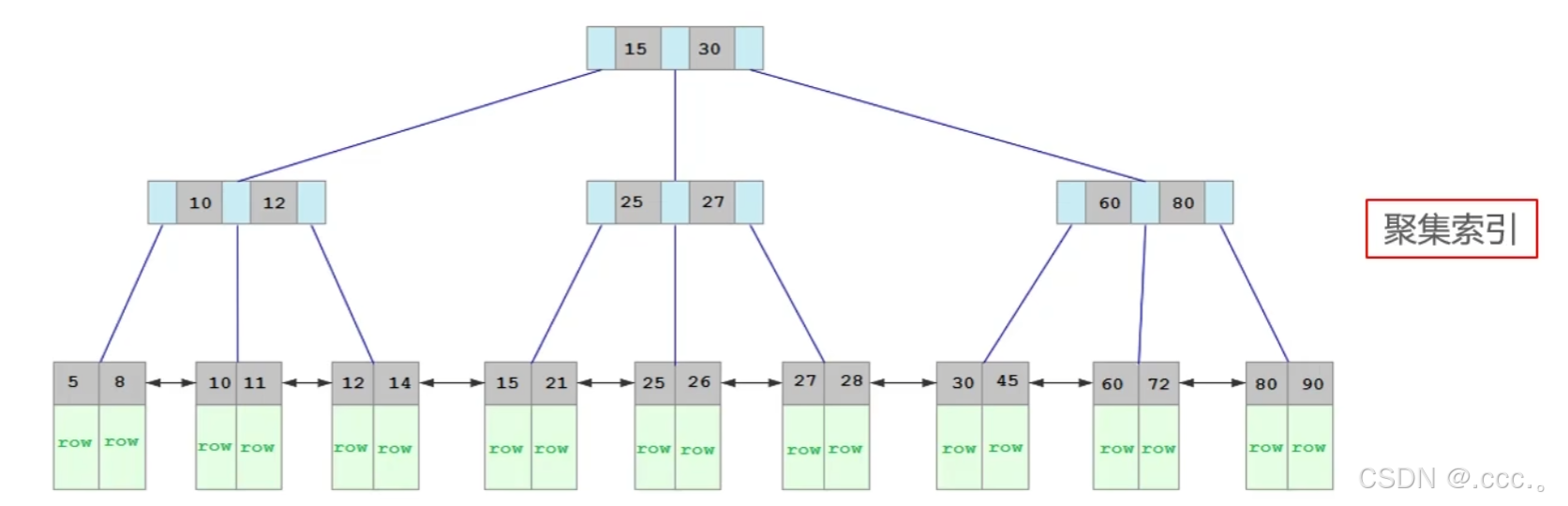
聚簇索引
1. 如果存在主键(一般都存在),主键索引就是聚簇索引。
2. 如果不存在,就用唯一索引(UNIQUE)做聚簇索引。
3. 如果表没有主键,也没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚簇索引。
总而言之,一张表肯定是存在一个聚簇索引的 ,并且只能有一个,非叶子节点存储索引,叶子节点存储行数据。
假设一张表叫user,有如下三个字段

下面就是聚簇索引的结构图。
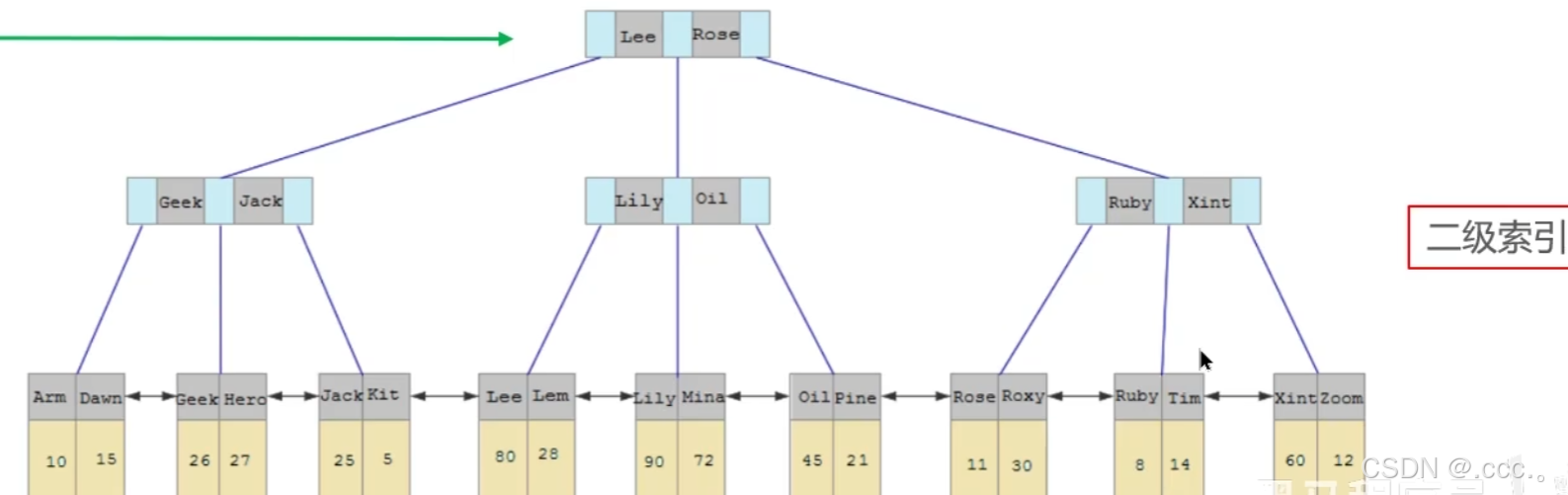
非聚簇索引
非聚簇索引存储的内容是主键,所以,我们根据非聚簇索引查询数据的时候,底层是可能会查两次的,这里我们给name字段加上非聚簇索引。
查两次情况: 执行select * from user where name = ’kit‘。
第一次: 根据非聚簇索引‘kit’查到对应数据的主键
第二次: 根据主键,也就是聚簇索引查询对应的行数据返回
查一次情况: 执行select id from user where name = 'kit'
第一次: 根据非聚簇索引‘kit’查到对应数据的主键,直接返回。
可能文字有些难以理解,现在根据上面两张图片和下面一张图片来看个例子,表名为‘user’,这里id是主键,自然对应聚簇索引,如果我们根据id 查询数据,例如select * from user where id = 5; 此时就会在聚簇索引中查询这一行数据直接返回。 现在我们给name加个非聚簇索引,现在根据name查询数据,select * from user where name = ”kit“,此时会根据非聚簇索引name查到对应的id为5,再根据id聚簇索引查询行数据返回。
回表查询
其实你已经见过回表查询了,你先看看概念,
回表查询是数据库中常见的一个概念,指的是当数据库引擎无法直接从索引中获取所需数据,而需要回到原始数据表中进行额外的查找操作。这种情况通常发生在查询语句中包含了索引无法覆盖的字段或者涉及到了复杂的查询条件时。回表查询会对数据库的性能产生不利影响,因为它需要更多的IO操作和数据扫描,导致查询速度变慢。
再看看非聚集索引的需要查两次的情况,这就是回表查询,回表查询查一次是不够的,要查多张表。