昇思MindSpore第七课---文本解码原理
1. 文本解码原理
文本解码是将模型的输出(通常是概率分布或词汇索引)转换为可读的自然语言文本的过程。在生成文本时,常见的解码方法包括贪心解码、束搜索(BeamSearch)、随机采样等。
2 实践
2.1 配置环境
安装mindnlp 套件

如果要安装NLP,可以访问下面的网站进行下载:
https://pypi.org/project/mindnlp/
2.2 模型训练
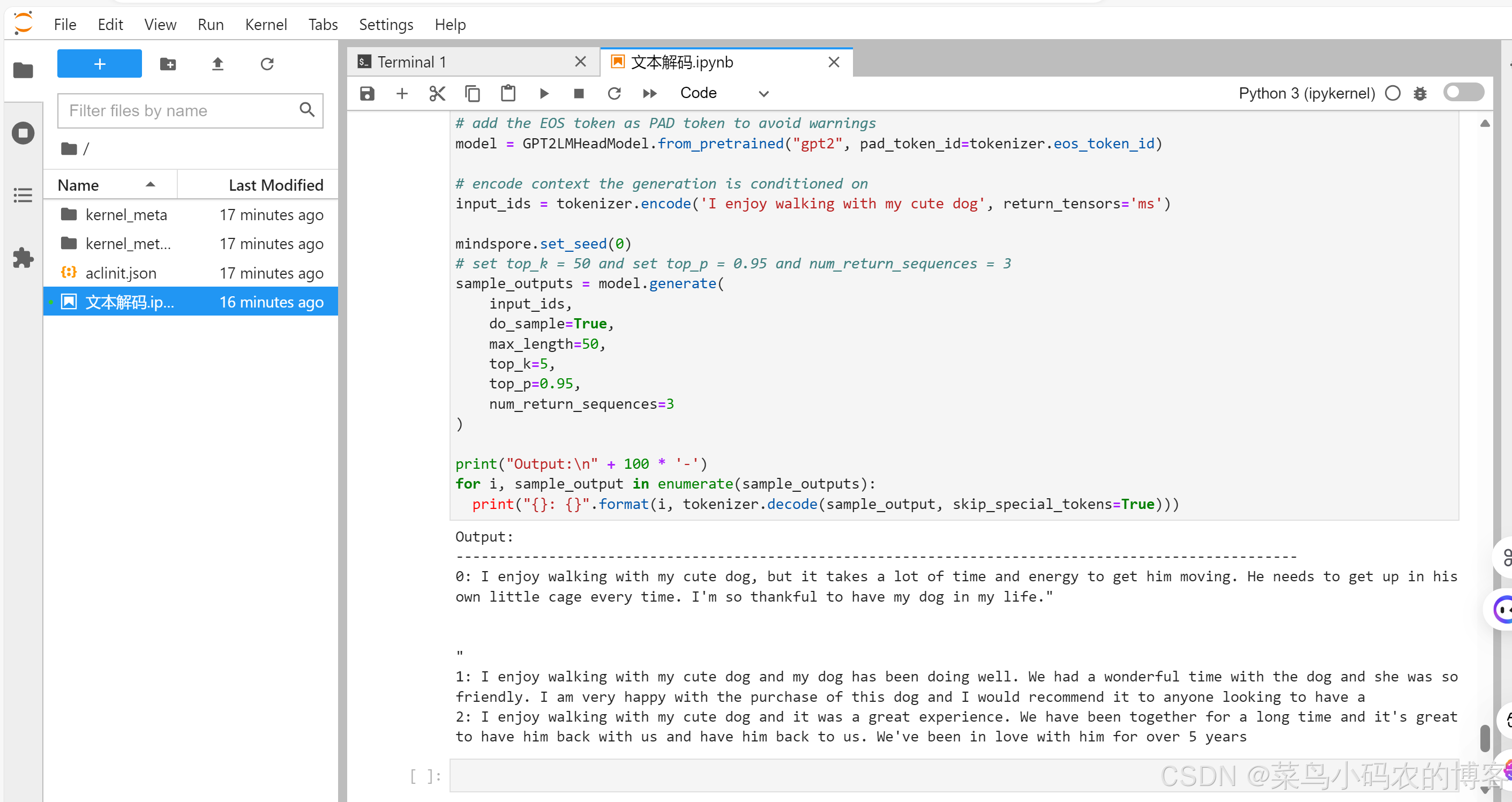
2.3 训练结果
3. 感悟
最后一节课讲解了大模型文本生成的多种解码策略(包含greedy search、beam search、top-k sampling、top-p sampling、temperature sampling等)以及各策略之间的对比,讲解的内容非常的全面,对上几节课的内容也进行了一定的串联。但是很多概念还需要细细打磨,认真理解一下。经过本次的学习,对于大模型理解的更加深刻,对于文字处理,提示词,以及模型的训练与微调,有了一个更加清楚的认识。