Vue.js 学习总结(13)—— Vue3 version 计数介绍
前言
Vue3.5 提出了两个重要概念:version计数和双向链表,作为在内存和计算方面性能提升的最大功臣。既然都重要,那就单挑 version 计数来介绍,它在依赖追踪过程中,起到快速判断依赖项有没有更新的作用,所以当通过computed(fn)读取值时,fn变的更聪明了,要是version没增加,那我就懒得执行。什么是懒更新(lazy update)?先看一个示例:
const a = ref(0)
const b = ref(0)
const check = ref(true)// step 1
const c = computed(() => {console.log('computed')if (check.value) {return a.value} else {return b.value}
}) // step 2
a.value++effect(() => {// step 3console.log('effect')c.valuec.value
})
// step 4
b.value++
// step 5
check.value= false
// step 6
b.value++
以上代码打印的结果是什么?
effect
computed
computed
effect
computed
effect
为什么是这样的结果?
step 1:在调用computed函数时,fn不会立即执行,仅读取
c时才会执行;step 2: 由于
c的fn未执行,a没有订阅者,没有日志打印;setp 3: effect会立即执行,先打印
effect,第一次读取c.value时打印computed,第二次读取c.value时其结果没变化,因此c的fn不执行;step 4: 虽然
b.value有更新,但此时c的依赖项仅a、check,因此c的fn不执行;step 5:
check.value有更新,c的fn执行,打印computed,此时c的依赖项变为check、b。c更新,则effect也重新执行,打印effect;step 6: 逻辑和
step 5一致,因此打印日志computed、effect;
什么是懒更新? 像computed(fn)、effect(fn)这类函数,仅但其计算结果被使用,或者fn中包含的响应式依赖项有更新时,才会触发fn的重新执行, 减少了不必要的计算。那么 vue3.5 提出的 version counting 在懒更新过程中起到什么作用,以及如何起作用的? vue 源码中一共有三个地方涉及到vesion计数:全局的globalVersion、Dep对象的version字段、双向链表包含的version字段,接下来我们就通过trigger和track过程将version串联起来讲解。
globalVersion
提出globalVersion的人真是个天才,我了解最早是在preact设计高效响应式框架@preact/signals-core时提出的想法,通过一个全局的version计数器快速判断是否有reactive发生变更,否则中断更新。globalVersion的定义如下,原则是只要reactive对象有任何更新,则其值自增
// file: dep.ts/**
* reactive有更新,则globalVersion++
* 为computed提供快速判断是否需要re-compute
*/
export let globalVersion = 0
vue有且仅有一个入口会触发globalVersion的自增,这个入口就是trigger函数,当任何Ref、Reactive等响应式对象值更新,都会触发trigger函数。所以trigger函数的作用就是根据target找到依赖项集合deps,并通知这些依赖项target值更新了。
export function trigger(target: object,type: TriggerOpTypes,key?: unknown,newValue?: unknown,...
): void {const depsMap = targetMap.get(target)...
}
上述代码为trigger函数签名,函数逻辑有些复杂,我们只需要聚焦到和globalVersion相关的逻辑。函数第一行通过targetMap获取target的依赖项集合,targgetMap的格式为{target -> key -> dep}, 因此depsMap的格式为key -> dep。
if (!depsMap) {// never been trackedglobalVersion++return
}
如果depsMap为空,表明当前taget没有依赖项,target值有更新,globalVesion需要自增,但由于没有依赖项,所以直接结束trigger流程。当depsMap不为空,则接着往下走。
let deps: Dep[] = []
...
接下来很长一段逻辑都是收集target.key对应的依赖项,并将其放到deps集合中, 当拿到deps集合后, 就可以为每个dep触发更新了。接下来的代码很重要:
startBatch()
for (const dep of deps) {dep.trigger()
}
endBatch()
vue3.5引入了批处理APIstartBatch、endBatch,其作用是使两者中间的所有依赖更新effect暂时不触发,并将所有effect使用链表关联起来,那什么时候触发依赖更新?答案是,在endBatch中遍历链表批量更新,这样处理有什么好处?我们稍后再回答
export function startBatch(): void {batchDepth++
}
在startBatch中执行batchDepth++,在startBatch和endBatch中间的依赖更新会判断其是否为0,不为0则跳过更新流程。接下来遍历deps,并调用dep.trigger函数通知更新。
// file: effect.tstrigger(): void {this.version++globalVersion++this.notify()
}
当触发dep.trigger函数,globalVersion自增,dep的version也会自增,后续sub(订阅者)获取值时,使用sub.version和dep.version判断就能快速确认是否要更新。最后一行调用notify执行通知。
notify(): void {startBatch()try {for (let link = this.subs; link; link = link.prevSub) {link.sub.notify()}} finally {endBatch()}}
startBatch和endBatch又成对出现了,作用一样,让其中间的更新流程暂不执行,先挂在全局的batchedEffect链表上,在合适的时机(batchDepth为0)再遍历链表统一处理。唉,还是绕不开链表,但结合代码更容易理解。结合下图分析,假如target对应的dep为Dep1,上述代码的try代码块会从链表head(this.subs)开始遍历subs链表节点,对应下图则就是从上往下的链式结构link1 -> link2 -> link3,而根据link节点又能找到对应的Sub(订阅者),是不是很方便?
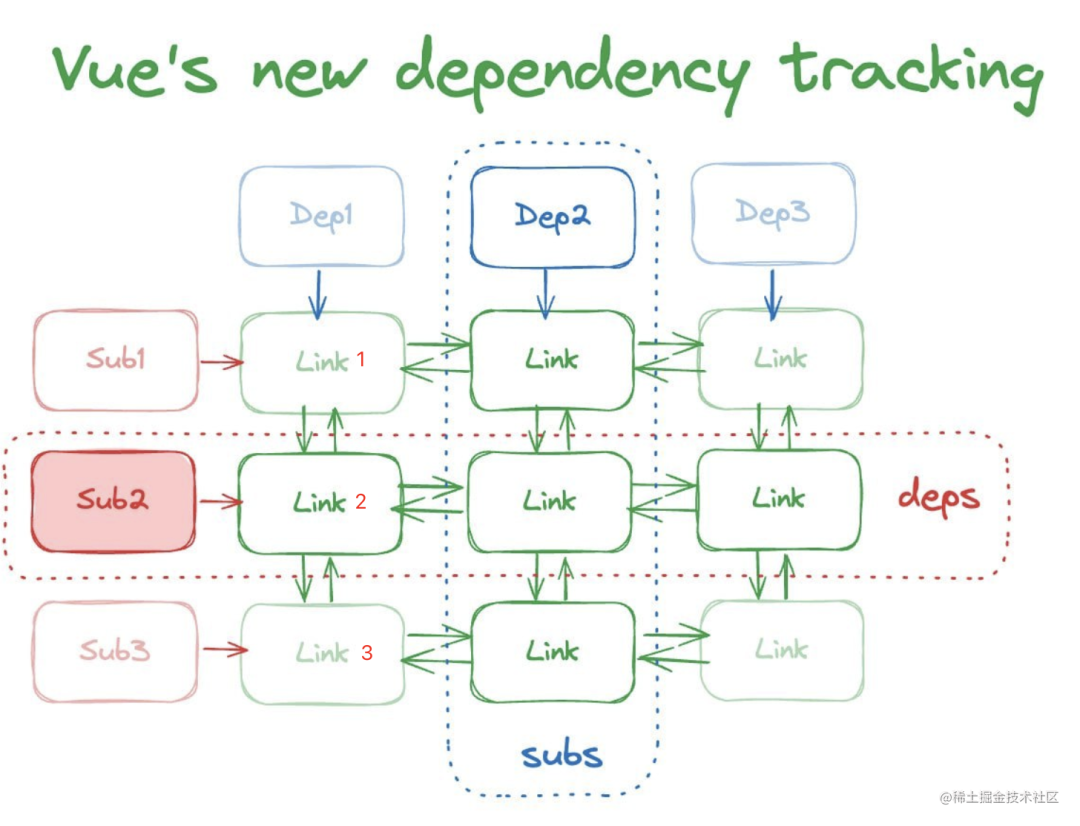
link.sub.notify()具体执行了什么?
// file:effect.tsnotify(): void {...this.nextEffect = batchedEffectbatchedEffect = this
}
subscriber的notify这么简单的吗?没错,它的作用就是将当前effect挂到上文提到的批更新处理的batchedEffect链表head上,那真正的更新在哪里处理?当然是endBatch了。还是以上述的链表图为例,此时batchedEffect指向了link3对应的Sub3, 而batchedEffect链表的顺序为Sub3、Sub2、Sub1。
export function endBatch(): void {if (--batchDepth > 0) {return}while (batchedEffect) {let e: ReactiveEffect | undefined = batchedEffectbatchedEffect = undefinedwhile (e) {const next: ReactiveEffect | undefined = e.nextEffecte.nextEffect = undefinede.trigger()e = next}}
}
上述代码为endBatch函数的简化版,首先判断batchDepth是否大于0,满足则结束,当且仅当batchedEffect包含完整link链路(batchDepth为0)时,才执行while逻辑。while代码块的逻辑大家应该熟悉,不就是遍历链表的节点吗?并且每遍历一个就执行sub的trigger函数,直到链表遍历结束。
// file: effect.ts// trigger函数简化版
trigger(): void {if (isDirty(this)) {this.run()}
}
trigger函数的逻辑是,先调用isDirty(this)看下我是否脏了,脏了就得重新run, 计算最新值。到目前,从target触发的更新,经过globalVersion、dep.version的自增标记了更新,并且经过一系列链路也通知到订阅者(Sub), 接下来就该看订阅者的表演。思考:trigger函数中isDirty用于判断是否需要重新计算,那isDirty是不是会用到globalVersion或dep.version?
version 计数的作用
趁热打铁,还是从上节的trigger函数说起,先调用isDirty判断是否有更新。
function isDirty(sub: Subscriber): boolean {for (let link = sub.deps; link; link = link.nextDep) {if (link.dep.version !== link.version ||(link.dep.computed && refreshComputed(link.dep.computed) === false)) {return true}}return false
}
唉,又是绕不开链表!但说曹操,曹操就到,这不就call back了上节最后提的思考,果真有使用version。假设isDirty(sub)中的sub是下图的Sub3,那么其deps节点,指向的是link3,而整个链表完整的节点顺序为link3->link6->link 9。
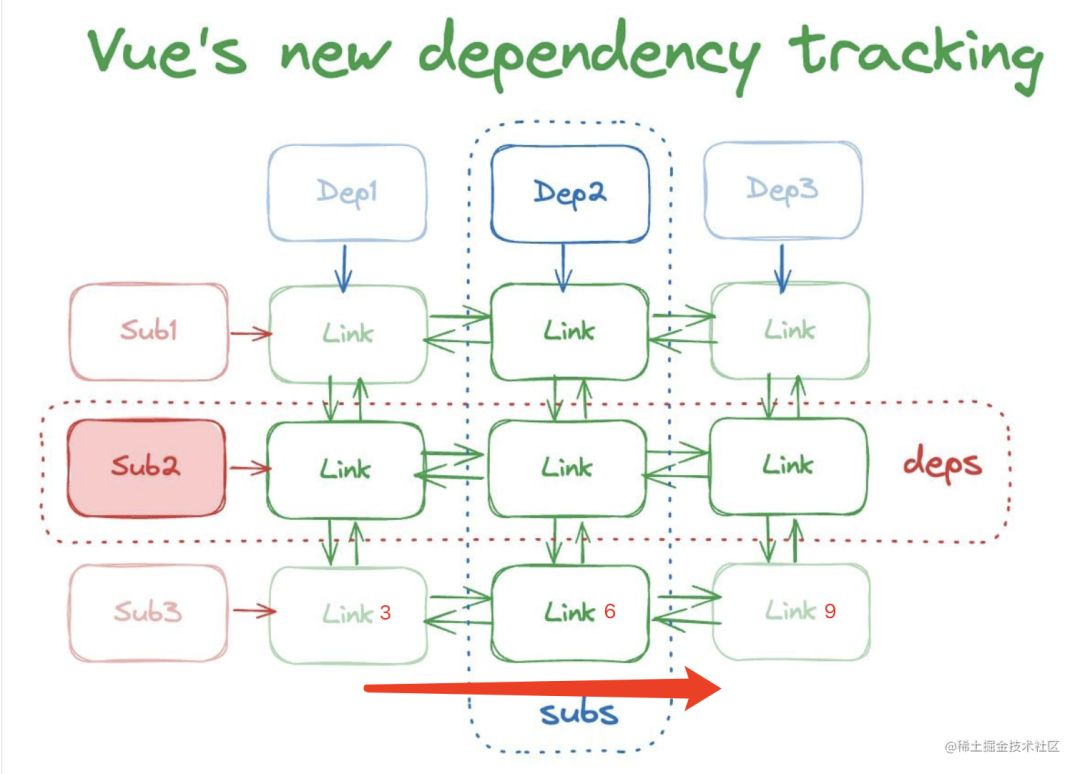
在遍历每个节点link时,需要做version比对,if语句由两部分组成,判断前先说明几个字段:
link.dep:dep为上文
target触发更新关联的deps集合中的一项,可以理解为和link是一一对应;link.dep.computed:如果订阅者Sub的依赖项是computed结构,那么
link.dep.computed即是类型为ComputedRefImpl的实体对象。refreshComputed:用于判断computed是否需要重新计算,需要则调用computed(fn)中的fn计算最新结果。
接下来继续分析if判断逻辑:
判断1:link.dep.version !== link.version 经过上一节target触发更新,dep.version已经自增,而link.version还为上一个版本,因此Sub需要重新计算。假设有如下代码:
const a = ref(0)
const b = ref(0)effect(() => {console.log('effect')a.valueb.value
})a.value++
b.value++
代码对应的Sub为effect,effect其特点是只要fn中依赖项a、b有更新,则立即执行fn,因此会打印三次effect。所以像effect类型的Sub订阅者,走到判断1就可确定数据有更新了。
判断2: link.dep.computed && refreshComputed(link.dep.computed) === false) 一个Sub依赖的dep可能为computed结果,当dep为computed类型时,无法简单的通过判断1来确认是否需要更新, 因此得继续调用refreshComputed来特殊处理。refreshComputed首先和globalVesion比较:
// file: effect.tsexport function refreshComputed(computed: ComputedRefImpl): false | undefined {if (computed.globalVersion === globalVersion) {return}computed.globalVersion = globalVersion...
}
computed.globalVersion初始化会设置为globalVersion - 1, 其目的是让computed第一次执行时跳过判断,能够执行其回调fn函数。当if成立时,说明当前没有任何响应式value更新,直接return,表示没有更新。否则将computed的globalVersion更新并接着执行后续流程。
// function: refreshComputed
...
const dep = computed.dep
if (dep.version > 0 && !computed.isSSR && !isDirty(computed)) {return
}
...
computed本身也是一个订阅者(Sub),要判断其是否需要更新,那也得依赖于它自身的dep,也就是computed.dep。例如代码:
// Sub1
const c = computed(() => {a.value // dep1b.value // dep2return a.value + b.value
})
// Sub2
effect(() => {c.value
})
Sub2依赖于Sub1,而Sub1又依赖于a.value和b.value,所以也得根据isDirty(computed)来判断Sub1依赖的dep1、dep2是否有更新。如果有更新那接下来就得考虑执行其fn函数了。
try {prepareDeps(computed)const value = computed.fn()if (dep.version === 0 || hasChanged(value, computed._value)) {computed._value = valuedep.version++}} finally {cleanupDeps(computed)}
代码computed.fn()前后包含有prepareDeps、cleanupDeps两个函数,这两个函数在内存优化方面起到了大作用:
prepareDeps: 会将其依赖的dep链表上所有节点的version重置为-1
cleanupDeps:执行完
computed.fn()函数后,如果dep链表上有节点的version仍然为-1,表示没有被依赖了,得从链表上移出节点。
为什么在内存优化方面起到大作用? vue3.5之前,Sub依赖的dep是一个集合,每次fn前将集合清空,频繁的集合清空操作,GC也不能立即执行,所以内存释放慢。computed.fn()执行后,有一个if判断dep.version === 0,这里的逻辑是处理什么? 还得提到computed第一次执行,由于c = computed(fn)仅当其值c被使用是才执行,在执行之前,即使fn中的依赖项有更新,computed的dep.version依赖为0。所以这里的if逻辑就是为了处理fn第一次执行,并将其dep.version手动自增。至此,version计数器的作用,也就分析了个大概,当然上文仅仅是分析了version相关逻辑的冰山一角,实际上比这错综复杂很多。
总结
实际上对Vue3.5在性能方面起到大作用的是双向链表,version计数器属于是锦上添花。但通过分析globalVersion、dep.version如何自增,以及如何快速判断是否需要更新的逻辑,其实对双向链表也了解的八九不离十。双向链表上,横向是订阅者Sub依赖的Dep的链表节点,而纵向上是响应式value对应Dep关联的订阅者的链表节点。双向链表的优势是,通过一个链表结构表达了原来两个依赖集合,内存占用明显减少,另一方面,每次重新计算时,不需要清除集合操作,直接更新链表即可,减少了GC操作,内存释放更快捷。