【论文分享】使用多源数据识别建筑功能:以中国三大城市群为例
建筑功能对城市规划至关重要,而利用多源数据进行建筑功能分类有助于支持城市规划政策。本研究通过分析建筑特征和POI密度,识别了中国三个城市群的建筑功能,并使用XGBoost模型验证了其在大规模映射中的高准确性和有效性。研究强调了建筑环境对分类准确性的影响,并发现长三角和珠三角城市群的开发策略较为协调,而京津冀城市群则不然。
【论文题目】
Identifying building function using multisource data: A case study of China's three major urban agglomerations
【题目翻译】
使用多源数据识别建筑功能:以中国三大城市群为例
【期刊信息】
Sustainable Cities and Society,Volume 108, August 2024, 105498
【作者信息】
Yue Zheng, 广东省城市化与地理仿真重点实验室,地理与规划学院,中山大学,广州 510275,中国
Xucai Zhang, 地理系,根特大学,比利时根特9000;跨学科空间分析实验室(LISA),土地经济系,剑桥大学,英国
Jinpei Ou, 广东省城市化与地理仿真重点实验室,地理与规划学院,中山大学,广州 510275,中国
Xiaoping Liu,广东省城市化与地理仿真重点实验室,地理与规划学院,中山大学,广州 510275,中国;南方海洋科学与工程广东省实验室(珠海),珠海 519000,中国,liuxp3@mail.sysu.edu.cn
【论文链接】
https://doi.org/10.1016/j.scs.2024.105498
【关键词】
建筑功能映射、XGBoost、兴趣点、建成环境、建筑几何特征
【本文亮点】
-
一种在大规模下快速识别单个建筑功能的方法。
-
通过迁移实验验证建筑环境的有效性。
-
成功识别了中国3900万座建筑的功能。
【摘要】
作为塑造城市景观的关键地理成分,定义建筑功能在规划城市发展和促进社会经济活动中发挥着重要作用。现有的大规模映射研究主要忽视了建筑周围环境,导致在某些学科中对大规模建筑级别映射的需求不能得到充分满足。为了弥补这一差距,本文计算了建筑轮廓的几何特征、建筑与邻近物体的距离以及兴趣点(POI)的核密度,以识别中国三个城市群(京津冀城市群、长三角城市群和珠三角城市群)中的建筑主要功能。通过利用XGBoost,我们的模型在三个城市群中分别达到了0.936、0.934和0.940的准确率,以及0.883、0.868和0.891的kappa系数,表明其在大规模映射中识别建筑功能的能力。此外,对不同特征组合和迁移能力的实验强调了建筑环境在提高分类准确性方面的重要性。此外,对三个城市群建筑分类结果的分析显示,长三角城市群和珠三角城市群的开发策略协调一致,而京津冀城市群的城市则没有表现出相同的发展策略。所有结果表明,利用多源可获得数据来高效地对大区域内的建筑功能进行分类是可行的,并且具有成本效益。这一方法可以在中国甚至更大范围内复制,为复杂的城市空间提供洞察,并帮助城市规划者提供政策支持,如旧城改造和新城规划。
【引言】
城市和城市群作为经济和社会发展的主要引擎,是中国现代化的主战场(Fang et al., 2013; Fang & Yu, 2017; Guan et al., 2018)。自改革开放政策以来,中国大力推动城市化,根据中国国家统计局发布的《政府工作报告》,城市化率从1978年的17.9%激增至2022年的65.2%(Keqiang, 2023; Xiaobo et al., 2018)。建筑物构成了城市的物质基础,是城市生活的核心,第一项国家自然灾害风险调查显示,中国城市和农村地区的建筑总数高达6亿。快速的城市化进程带来了中国建筑数量和功能的重大变化(Wang et al., 2015)。建筑功能作为建筑的核心元素,提供了人类的基本需求,并揭示了人类活动的社会经济形式(Niu & Silva, 2021; Zhang & Zhang, 2009)。在这种背景下,对国家建筑功能分类的全面和细致理解有助于未来的城市规划、环境保护、热岛效应响应、建筑部门的碳中和以及其他各种倡议(Choi & Yoon, 2023; Shen et al., 2021)。然而,传统的手工建筑功能调查费时且覆盖面有限。商业地图服务如Google Maps通常无法直接提供单个建筑的功能,只提供兴趣点(POI)的功能。因此,急需提出一种快速且自动化的大规模建筑功能识别方法。
几十年来,许多研究人员专注于智能功能映射方法的深入研究,这些方法适用于大规模映射。传统方法主要关注地块级别的土地利用分类,主要依赖遥感数据和地理特征或纹理,忽视了人类活动的社会经济特征(Hu & Wang, 2013; Pacifici et al., 2009)。近年来,许多新兴的城市数据,如手机信号数据(Wei Tu & Li, 2017)、社交网络签到数据(Cai et al., 2022)和兴趣点数据(POI)(Andrade et al., 2020),被用于更细粒度的城市土地利用映射。同时,机器学习算法的广泛应用促进了这些不同数据集与遥感信息的更有效集成,为城市土地利用研究开辟了新的途径。例如,GongPeng et al.(2020)应用随机森林算法,利用高德POI、腾讯MPL、夜间灯光影像及其他遥感数据对中国440,000个城市地块进行了分类。类似地,Zhang et al.(2020)利用微博签到数据来细化广州的土地利用类型,并比较了随机森林、支持向量机和朴素贝叶斯模型的性能。尽管这些研究在一定程度上提高了准确性,但其对地块级别分类(Zhang et al., 2020)的关注仍不足以探索具有高度混合和快速变化土地利用的现代城市。迫切需要开发新技术以实现细粒度的建筑功能映射,尤其是在大规模下,以描述单个建筑功能的分布。
在城市土地利用分类的基础上,关于单个建筑功能分类的研究已经展开。高分辨率遥感影像包含丰富的地面细节信息,学者们从中提取光谱特征以分类屋顶类型或连续建筑类型(Taubenböck et al., 2009)。然而,从这些地球观测遥感影像中推断建筑类型仍然具有挑战性。此外,像素级别的遥感影像可能导致建筑边缘或角落几何信息的丢失。此外,地面图像数据被引入用于识别单个建筑的功能,常用来源包括通过在线地图服务如OpenStreetMap或Google Street View获取的街景图像(Shivangi Srivastava & Tuia, 2020; Srivastava et al., 2018),这些图像提供了建筑轮廓和建筑立面的详细特征(Atwal et al., 2022)。例如,Kang et al.(2018)使用街景数据推广了一种实例建筑分类方法,并在美国和加拿大的多个城市进行实验,将建筑分类为八个类别,并取得了更好的结果。然而,街景地图的明显缺点是覆盖范围有限(Cao et al., 2018)。街景地图只能提供主要城市的详细描述,并集中在道路沿线,这对处理远离道路的建筑物提出了挑战(Zhong et al., 2014)。随后,社交媒体数据被引入到单个建筑分类中,如微信用户密度和签到数据,以及出租车轨迹。Liu et al.(2018)整合了社交网络数据、出租车轨迹和遥感影像来描述广州天河区的建筑。Zhang et al.(2023)引入了腾讯位置数据集,以识别深圳南山区的建筑类别。Zhuo et al.(2019)结合了出租车轨迹数据和实时腾讯用户密度(TUD)数据,识别广州海珠区的建筑功能。类似地,出租车轨迹数据通常难以覆盖整个城市区域,对远离主要道路的建筑功能推断存在困难。此外,高分辨率TUD数据通常不公开且难以获取。在城市群或全国范围内的广阔区域进行建筑功能识别研究困难重重。总体而言,无论是基于街景地图还是社交媒体数据的方法,都仅适用于数据覆盖丰富的小区域内的建筑功能识别。因此,在大规模下识别单个建筑功能仍面临许多挑战。
近年来,一些学者也尝试在大规模下进行建筑功能识别。Chen et al.(2023)整合了POI、土地利用地块和建筑几何数据,使用OneClassSVM在美国50个城市识别建筑功能。然而,他们仅简单地将POI类别分配给建筑,未能充分展示POI数据与建筑之间的空间关系。然而,在大区域尺度上识别单个建筑功能仍有很大的改进空间。Zhang et al.(2023)在深圳的实验确认了考虑建筑环境对建筑功能识别的有效性,这在现有的大规模建筑功能识别中尚未被考虑。应考虑邻近建筑的影响,也应考虑其他邻里因素。例如,建筑与道路之间的距离很重要,因为商业和公共建筑通常位于道路附近,而住宅建筑通常与邻近建筑的距离较小。因此,需要进一步挖掘POI的使用,并考虑建筑环境,以实现大规模建筑功能映射。
为弥补这些研究空白,本文引入了包括建筑环境信息(到最近道路、河流和建筑物的距离)和POI数据在内的多源数据,以及建筑几何特征(通过形状指标量化的建筑轮廓几何属性)。通过利用机器学习算法,我们的实验展示了这一方法在广泛区域内快速识别建筑功能的适用性。本文的贡献总结如下:1. 本研究引入了建筑自身的几何特征,包括12个二维形状指标和一个三维特征建筑高度,这在识别建筑分类中非常有用。2. 我们计算了目标建筑的POI核密度,而不是量化POI数量,旨在更好地弥补POI分布不均的情况,并提供更细致的理解。3. 我们充分考虑了建筑环境,不仅包括最近的建筑,还包括到最近道路、水体和城市中心的距离。4. 通过对不同模型和特征组合的彻底比较,我们选择了XGBoost算法,该算法在三个城市群中分别达到了0.936、0.934和0.940的准确率,kappa系数分别为0.883、0.868和0.891。多个验证实验充分证明了所选多源数据和模型在大区域尺度上识别单个建筑功能的有效性。
【材料和方法】
2.1. 时间序列夜间光数据集的构建
本研究选择了中国的三个主要城市群作为研究区域:北京-天津-河北城市群(BTHUA)、长江三角洲城市群(YRDUA)和珠江三角洲城市群(PRDUA)。BTHUA位于中国北方,是中国的“首都经济圈”。该区域包括13个城市,涵盖了北京、天津以及河北省的保定、唐山、廊坊、石家庄、秦皇岛、张家口、承德、沧州、衡水、新泰和邯郸。YRDUA位于长江下游,包括直辖市上海,以及江苏省的南京、无锡、常州、苏州、南通、扬州、镇江、泰州,浙江省的杭州、宁波、嘉兴、湖州、绍兴、舟山和台州,共计16个城市和近1200万座建筑。PRDUA作为中国南部对外开放的门户,包括广东省的广州、佛山、肇庆、深圳、东莞、惠州、珠海、中山和江门,覆盖了700万座建筑。三个城市群代表了中国人口密度最高、创新能力最强、综合实力最优的地区。这些城市建筑的复杂性和多样性使得模型在挑战条件下识别建筑功能的能力得到了更全面的检验。因此,选择这38个城市作为研究区域具有战略意义,为大规模建筑功能分类提供了宝贵的洞见。城市位置如图1所示。
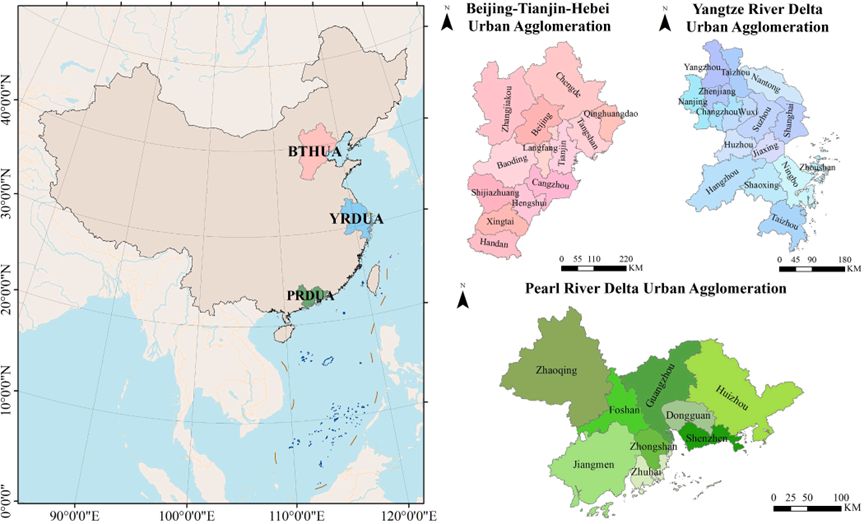
图1. 中国三个主要城市群及38个城市的位置和空间分布
2.2. 数据集准备与处理
表1总结了本研究中使用的数据及其来源,包括建筑数据、兴趣点(POIs)、道路网络、水路和县级中心。
表 1 数据集和来源的总结
表2 建筑主要功能类型

表3 建筑轮廓的形状指标
2.2.1. 建筑数据
本研究中使用的建筑数据可以分为两个主要部分:(1)建筑轮廓和高度;(2)建筑功能数据。建筑轮廓数据来源于Shi等人(2023)发布的公开数据,这些数据提供了包括中国在内的东亚地区的高质量和完整的建筑轮廓数据。建筑高度数据来自百度地图,这是中国的一家专业地图数据服务平台,提供大量的基础地理数据。建筑功能数据来自Open Street Map(OSM)和政府调查数据。OSM提供了部分建筑的功能信息。具体来说,在长三角城市群(YRDUA)中,该数据集包括22万栋建筑的信息;在京津冀城市群(BTHUA)中,有13万栋建筑的信息;在珠三角城市群(PRDUA)中,涵盖了4万栋建筑的功能信息。此外,还包含了政府调查数据,涵盖了深圳50万栋建筑和珠三角城市群120万栋建筑的功能信息。在整理和精炼这两个数据集后,我们通过谷歌地图和街景数据验证了数据的正确性。建筑功能的分类依据中国土地利用分类标准进行精细化,详细分类列在表2中。需要特别说明的是,本文中识别的建筑功能指的是建筑的主要功能,而非混合功能。例如,如果一栋住宅楼的底层包含零售店等商业店铺,而上层是住宅房屋,那么该建筑的主要功能仍然是住宅楼,而不是商业和住宅混合建筑。该数据集被视为“训练数据集”和“测试数据集”,以便于模型的训练和验证。
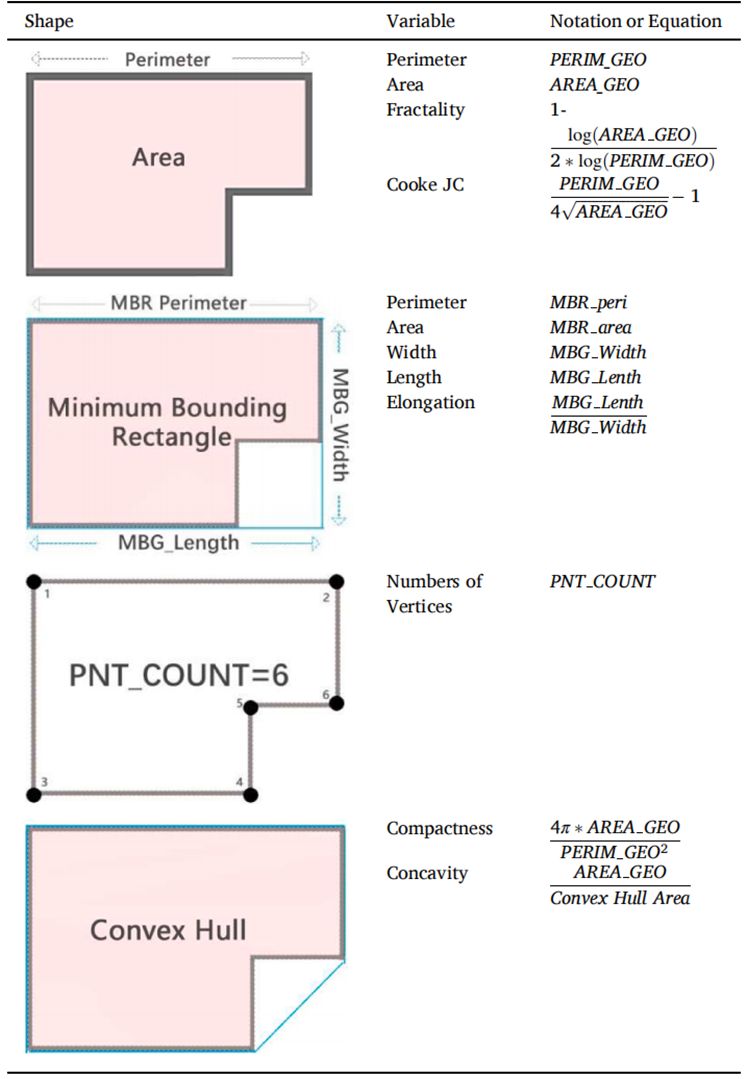
建筑轮廓包含了每个顶点的纬度和经度坐标,从中可以推导出大量其他指标。建筑轮廓的几何特征在一些建筑研究中得到了应用,并且被证明是有效的(Arehart等人,2021)。在本研究中,我们尝试探讨建筑轮廓几何特征对建筑功能识别的贡献。除了建筑高度外,我们计算了12个与建筑轮廓相关的形状指数,包括部分简单指标,如建筑轮廓的面积和周长、最小建筑包围矩形和最小凸包,以及复杂指标,如紧凑性和分形度。我们选择这12个指数不仅因为它们可以有效量化对象的整体几何配置,还因为它们在之前的研究中被广泛使用(Xu等人,2022)。这些指标的名称和计算公式详见表3。
2.2.2. 兴趣点和开放街图
POI 数据集记录了丰富的实际地理空间信息,能够很好地反映城市中的社会经济、功能结构、人口分布以及其他空间特征。利用其丰富的语义、短期获取周期、低成本和快速更新,POI 在城市社会经济空间分布、城市土地利用模拟和城市功能区域识别中得到了广泛应用。在本研究中,我们使用了高德地图(http://gaode.com)提供的 POI 数据,这些数据能够提供中国丰富的 POI 数据以进行建筑分类。在应用之前,POI 数据的预处理至关重要。首先,为了匹配建筑功能分类标准,我们将 POI 数据重新分类为 12 类:城市村庄/乡村、城市住宅、酒店、餐厅、购物、工厂、公共设施、交通、金融、政府、医疗服务和教育。其次,POI 的分布在城市中是不均匀的。商业中心和中央商务区等人口密集区域往往拥有集中的 POI,而不太繁忙的区域则表现出较稀疏的 POI 分布。这导致一个建筑物中可能会有多个不同类别的POI,而有些建筑物可能完全没有 POI。为了解决这个问题,我们引入了核密度分析,这是一种非参数统计方法,用于估计数据分布,广泛应用于地学研究,能够更好地揭示数据的空间分布模式和特征。对 12 种POI 的核密度分别在 500 米范围和1000 米范围内进行了计算,从而计算出每个建筑的 POI 核密度,而不仅仅是计数POI 的数量。通过考虑两个不同范围内的 POI 核密度,这种计算方式不仅考虑了POI 对所在建筑的影响,还考虑了它们对周围区域的影响。这种方法增强了对 POI 对特定建筑及其更广泛背景影响的理解。
开放街图(OpenStreetMap,简称OSM)是一个志愿地理信息(VGI)项目,提供了丰富的地理数据,包括交通路线、土地利用图、水道和建筑物。其中,路网和水道被选用于后续的建筑功能分类。此外,县中心的位置通过高德地图确定。至今,已经计算了每个建筑物到道路网络、水道和县中心的欧几里得距离,作为建成环境信息。
2.3. 整体框架
我们使用 XGBoost 算法来识别三个城市群中的建筑功能,基于描述建筑轮廓几何特征的形状指数、POI 数据和建筑环境信息。本研究的整体框架如图2 所示,分为四个部分:(1) 数据准备,包括收集和处理各种类型的数据集以生成模型变量,并收集带有类别信息的建筑用于训练和测试样本集;(2) 模型开发,在此过程中我们设计了五种不同的特征组合并引入了四种不同的算法。我们分别在每个城市群中构建了 XGBoost 分类模型,使用训练样本集对模型进行训练,并使用测试样本集对模型进行评估。然后,我们评估了模型在深圳的适用性;(3) 结果展示,包括选择三个城市的部分区域进行三维展示并验证其正确性;(4) 评估和分析,展示归一化混淆矩阵并分析各城市中不同建筑类型的数量和比例。

图 2. 建筑功能识别的整体框架
2.4. 模型说明和评估
决策树、随机森林和极端梯度提升(XGBoost)算法是目前广泛使用且成本效益高的监督学习分类方法。其中,XGBoost 算法是一种基于决策树梯度提升的集成机器学习算法(Chen et al., 2015)。在 XGBoost 中,每棵决策树是逐步构建的。在构建的每一步中,需要考虑前面决策树的结果,以获得更好的预测。此外,引入了正则化和梯度下降,使算法具有更好的鲁棒性和泛化能力。与随机森林相比,后者通过对每棵决策树的结果进行投票或平均来获得最终结果,XGBoost 算法的优化技术更适合解决大规模数据集和高维特征问题,并能提供更好的预测。XGBoost 在各种地质研究和城市问题中已被证明是可靠的(Abdullah et al., 2019;Abedi et al., 2022;Lu et al., 2021;Zhou et al., 2022)。
在本文中,我们应用 XGBoost 算法来识别中国三个主要城市群的建筑功能。使用每个建筑属性作为自变量,建筑功能作为因变量,XGBoost 模型在训练样本上进行了训练,并在测试样本上进行了测试。
我们引入了两个指标来评估模型性能:准确率和 Kappa 系数。准确率是检测模拟值准确性的基本评估指标。Kappa系数是基于混淆矩阵的一致性测试指标。对于分类问题,Kappa 系数用于测试模型模拟结果与实际分类之间的一致性。Kappa 系数可以分为五个组,表示不同的一致性水平:0.00.20为非常轻微的一致性,0.210.40 为一般一致性,0.410.60为中等一致性,0.610.80 为显著一致性,0.81~1为几乎完美的一致性。计算准确率和 Kappa 系数的公式(公式(1)–(4))如下:

Isodata方法在K-means聚类算法的基础上做了一些改进,其中最显著的优化是:虽然K-means和Isodata方法都需要预先指定聚类数,但Isodata更加灵活。如果类间距离小于用户指定的值或类内样本数过少,它可以自动“合并”聚类;如果聚类数少于指定值的一半,它可以自动“分裂”聚类,从而达到理想的聚类效果。在本研究中,K-means方法中的k值是根据Isodata自动“分裂”或“合并”所获得的最终聚类数来确定的。
【结果与讨论】
3.1. 模型性能比较
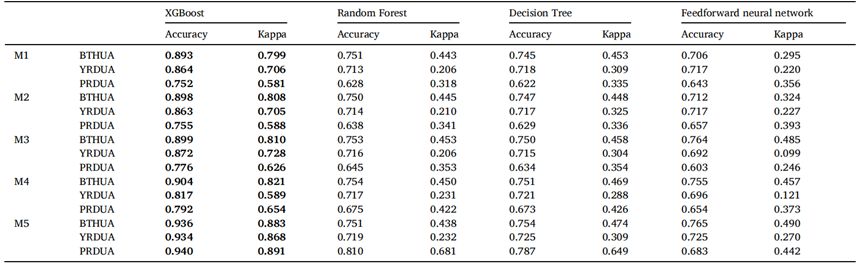
对于三个主要的城市群,我们在城市群内进行了随机抽样,将70%的样本用作训练样本,其余30%作为测试样本。同时,我们对随机森林、决策树、前馈神经网络算法和XGBoost算法进行了比较,如表4所示。在XGBoost算法中,北京-天津-河北城市群的准确率为0.936,Kappa系数为0.883;长江三角洲城市群的准确率为0.934,Kappa系数为0.868;珠江三角洲城市群的准确率为0.940,Kappa系数为0.891,这些都优于其他算法。在模型设置和调整方面,我们使用了“GridSearchCV”函数进行调整,并引入了早期停止机制,其中包括几个重要的超参数,如学习率0.05;n_estimators为400,max_depth为12。
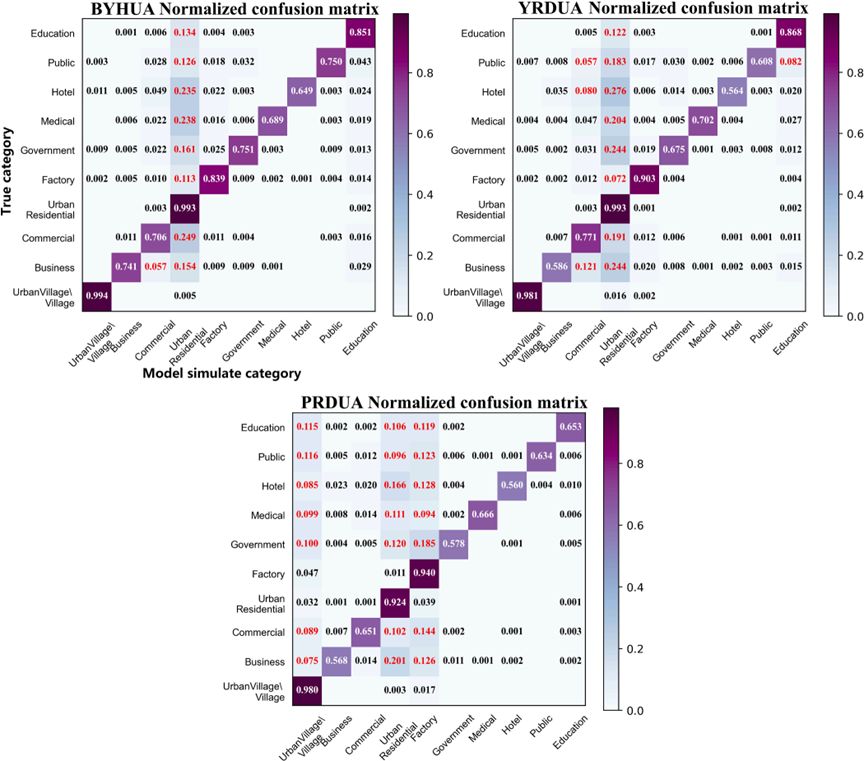
图3 京津冀城市群、长江三角洲城市群和珠江三角洲城市群的归一化混淆矩阵
表4 三个城市群中不同模型的结果

我们编制了三个地区模拟结果与真实结果之间的标准化混淆矩阵,如图3所示。纵轴为建筑物的真实类别,横轴为模型模拟的类别,沿对角线的值表示模型正确模拟的每个类别建筑物的比例。可以看到,城市村庄/乡村、住宅和工厂的准确性在所有三个区域均保持在较高水平。同时,北京-天津-河北城市群和长江三角洲城市群的学校建筑模拟结果也较好,准确率均超过0.85。此外,商业和酒店的精确度稍差,这可能与这些类别样本较少有关,导致可能的混淆。
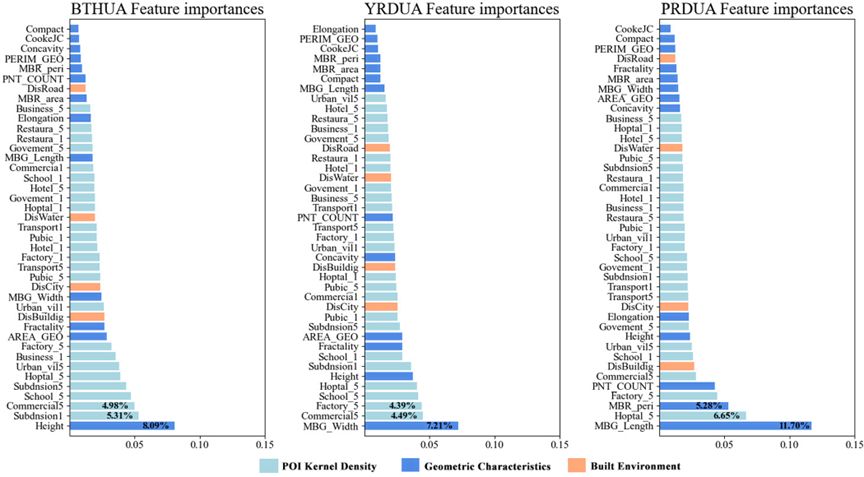
图4 三大城市群的特征重要性地图。形状指标的缩写已在表3中详细解释。以“_1”和“_5”结尾的特征表示不同类型POI的核密度值。以“Dis”开头的特征表示与其他地理实体的距离
图4展示了XGBoost模型的特征重要性,从左到右分别是BTHUA、YRDUA和PRDUA。每个城市群中每个特征的重要性值不同,排名差异显著。在BTHUA中,建筑高度的贡献最大,而在YRDUA和PRDUA中,最重要的特征分别是最小建筑包围矩形的宽度和长度。此外,一些特征在三个研究区域中始终保持较高的排名和重要性值,如建筑高度、商业、工厂和医院的POI核密度,这表明这些特征对于建筑功能识别在任何区域都是重要的。令人惊讶的是,几个建筑环境特征在三个研究区域中排名较高,表明这些特征的引入对推断建筑功能是有意义的。特征重要性图表明,不同特征集的选择对模型性能的影响不同。为了验证不同特征组合对建筑功能分类的影响并选择最佳特征组合,我们进行了五组实验(M1-M5),表5详细列出了每组实验的特征选择。表 5 不同特征组合下的实验模型
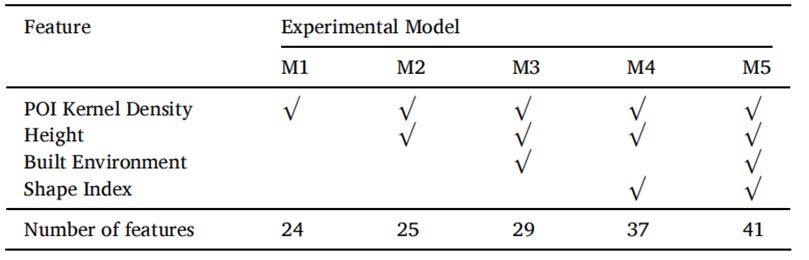
其中,POI核密度指的是12种POI类型的核密度值。建筑环境指的是每个建筑物到最近建筑物、道路网络、水道和县中心的欧几里得距离。形状指数是描述每个建筑物轮廓几何特征的指标。表 6 三大城市群中不同模型和不同特征组合的结果
从表6中的分析结果可以明显看出,三个城市群中的XGBoost模型表现出良好的准确性,特别是当结合了POI核密度、建筑高度、建筑环境信息和建筑几何特征的形状指数的特征组合5时,这些结果确认了三种特征在准确识别建筑功能中的重要性,特别是建筑环境信息的纳入显著提高了模型的准确性。特征组合5中的模型特征是在追求准确性和有效性过程中优化的顶峰。此外,从不同模型准确度的比较中也可以看出,XGBoost模型的准确度始终高于其他模型。这可能归因于XGBoost在其结构中引入了更多的正则化和优化技术,从而在处理大规模数据集和高维特征时表现最优。
3.2. 模型迁移能力
模型的迁移能力是至关重要的,因此我们在本节中评估了这一能力。我们选择在深圳进行此实验,因为其他城市和地区样本稀疏,难以准确反映迁移实验的效果。深圳为超过50万栋建筑提供了真实的建筑功能信息,使我们在类型和数量上获得了更完整的样本。位于深圳经济特区中部的福田区也是该市的行政、金融、文化、商业和国际交流中心,该区内的建筑类型广泛(见图5)。为了评估模型的性能和迁移能力,我们随机从福田区的18000栋建筑中选择了30%的样本作为验证样本。首先,我们选择用深圳市内福田区以外的建筑进行训练,同时作为对照,我们用福田区剩余70%的样本训练另一个模型,以预测相同的验证样本。同时,为了验证建筑环境在模型迁移能力中的重要性,我们分别训练了包含和不包含建筑环境信息的模型。我们实验的综合结果详见表7。
图 5 深圳及福田区的位置
表 7 模型迁移性结果

对结果的细致分析揭示了建筑环境对四种不同模型准确性的影响。特别是,在随机抽样时,建筑环境的整合在所有模型中都显现出明显但适度的准确性提升。相比之下,建筑环境在迁移实验中的准确性提升中发挥了关键作用。同样,在所有模型比较中,XGBoost模型在迁移和随机抽样中均表现最为有效。迁移能力方面观察到的显著效果突显了建筑环境在提高建筑功能识别中的重要性。
3.3. 建筑功能分类结果展示
由于研究范围广泛,我们无法展示所有建筑功能分类的结果。因此,我们选择展示三个城市群中一些关键区域的详细结果,包括5公里网格下的测试样本准确性以及不同功能区域的3D表现:北京市的故宫及其周边、上海市的陆家嘴区,以及广州市的高等教育 mega 中心。这些选定地点为展示我们的功能分类模型在不同城市环境中的有效性和应用提供了说明性例子。
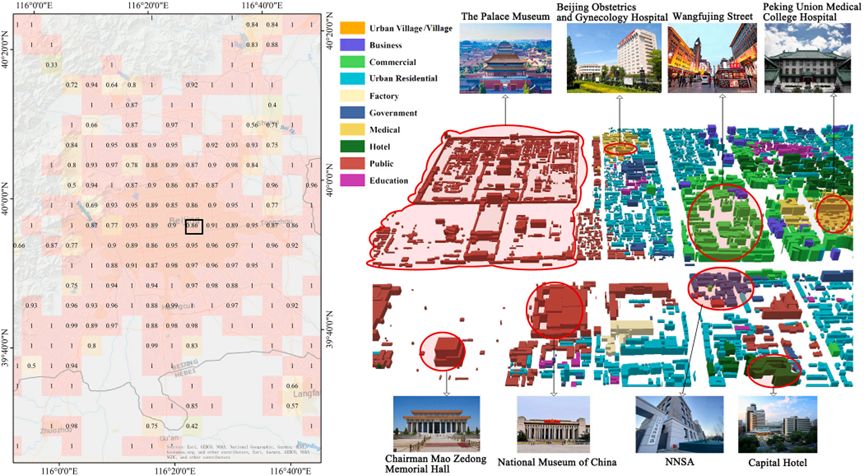
图 6 北京故宫周边建筑分类地图
3.3.1.故宫,北京
如图6所示,左侧为北京市5公里网格下的准确性地图,展示了整体满意的结果;右侧为故宫的3D展示。故宫(即紫禁城)是中国明清两代的皇宫,位于北京市中心轴线的中部,是世界上最大且保存最完好的古木结构群之一,也是世界遗产。故宫前的天安门广场上有中国国家博物馆和毛泽东纪念堂,这些作为对公众开放的博物馆在研究中被归类为红色公共建筑。故宫东侧分布着住宅建筑,大多数是胡同和四合院,典型的北方中国住宅。在天安门广场东侧,有中国生态环境部、首都酒店等。此外,大多数王府井步行街上的建筑被识别为商业建筑,少数为商务建筑。北京协和医院和北京妇产医院也被成功识别为医疗建筑。
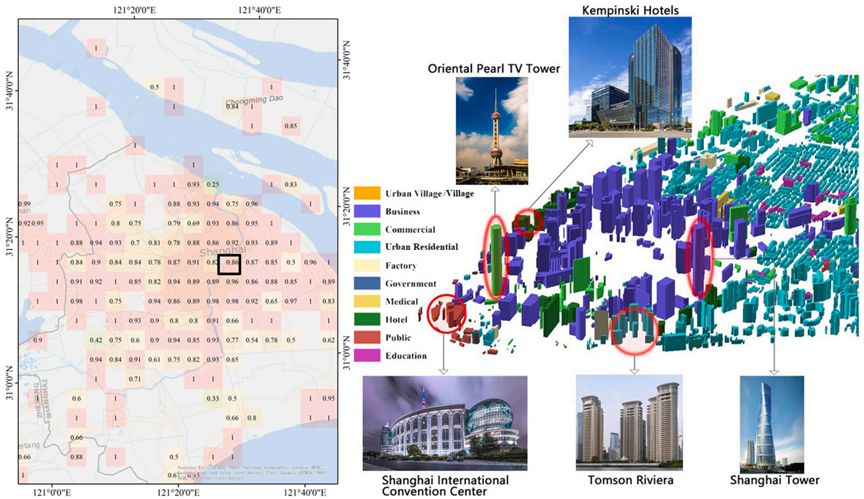
图 7 上海陆家嘴地区建筑分类地图
3.3.2.陆家嘴区,上海
图7左侧展示了上海5公里网格下的准确性地图,右侧为位于上海浦东新区黄浦江畔的陆家嘴区。作为上海国际金融中心的核心功能区,陆家嘴是许多跨国银行和公司的中国及东亚总部所在地。陆家嘴区包含大量高层或超高层商务建筑,如632米的上海中心大厦,它是上海的地标建筑,主要用于办公、商业和旅游。上海国际会议中心是现代化的会议场所,准确地被识别为公共建筑。此外,陆家嘴有许多豪华酒店,如凯宾斯基酒店、上海浦东文华东方酒店、香格里拉酒店等,这些在图中显示为深绿色。陆家嘴东部有更多如汤臣瑞士等住宅建筑,这些建筑排列整齐,高度较商务建筑低。东方明珠电视塔是集城市观光、时尚餐饮、购物娱乐、广播电视传输等多功能于一体的国家5A级旅游景区。在研究中,它被归类为商业建筑。

图 8 广州高等教育Mega 中心建筑分类地图
3.3.3.广州高等教育 mega 中心
图8中,测试样本的分布不如北京和上海广泛,但5公里网格也基本覆盖了广州市的主要城市区域。图8右侧展示了位于广州番禺区小谷围岛的广州高等教育 mega 中心(HEMC),占地17.9平方公里,是世界上为数不多的岛屿大学城之一,目前大学城内有十所大学,包括中山大学和华南理工大学。HEMC内大部分区域为大学,因此大量建筑为教学或宿舍楼,在图中被标为紫色教育建筑。大学城内有四个城中村,分别是北岗村、南亭村、北亭村和随石村,在地图上显示为橙色的小建筑群。城中村附近有许多小餐馆和其他商业店铺,在地图上显示为翡翠绿色。在HEMC的南北轴附近,有几个高层住宅区,图中显示为蓝色建筑。HEMC西北部的广东科学中心作为一个社会科学和技术活动场所,为公众提供科学教育,正确地被归类为公共建筑。大学城中心的大学城主体育场也被归类为公共建筑。高等教育 mega 中心南部的岭南印象园作为岭南民俗文化的旅游景点,也被归类为公共建筑。广东省中医院,作为HEMC唯一的三级综合医院,被正确地归类为医疗类别。此外,大学城内的商业中心 GOGO 新世界在图8的右上角显示为翡翠绿色。
3.4. 各类别建筑数量和比例统计
使用训练好的XGBoost模型对三个主要城市群的建筑进行功能分类,得到了详细的分类信息,共涵盖230万栋建筑。为了对这些建筑进行详细分析,我们首先统计了各类别建筑的数量和比例。如图9所示,每个城市的堆叠柱状图展示了每个类别建筑的数量,高度表示建筑数量。附带的饼图则展示了各城市中建筑数量占比大于1%的类别比例。
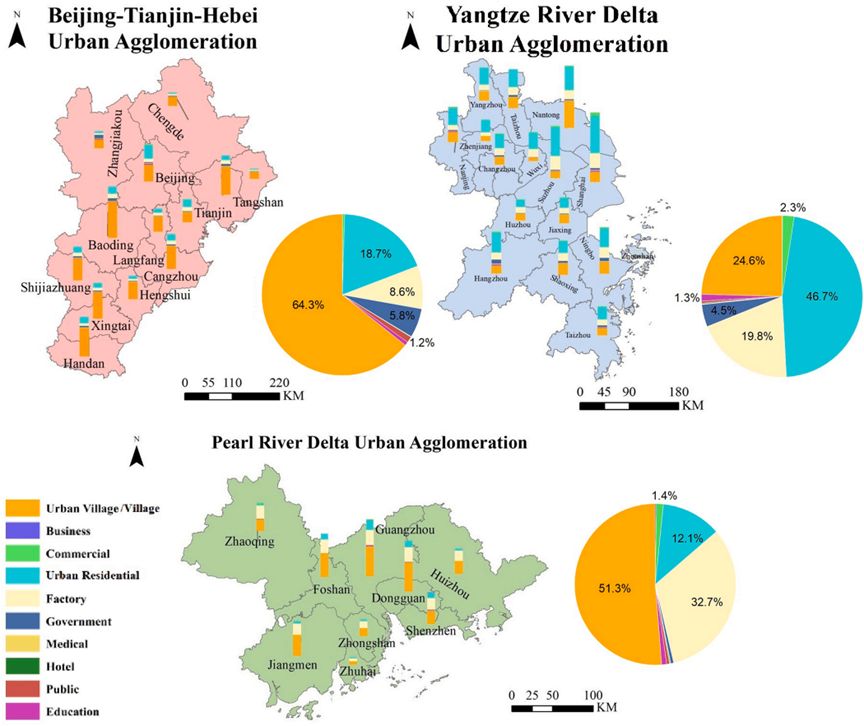
图 9 每个城市中不同类型建筑的数量和百分比
根据《广东省旧城区旧厂区旧村落休闲协会和国家发展战略学院,RUC,2023年年鉴与报告》及《住房和城乡建设部,2022年》,广州和深圳的城中村因其规模大、密度高在国家特大城市中显得尤为突出,而其他城市群中的城中村/村主要集中在外围区域。尽管广州、深圳和东莞与北京、上海和南京都属于一线或新一线城市,但PRDUA中的城中村数量和比例显著高于后者。此外,广东和江苏的城市化率分别排名第七和第八,超过河北省13%以上,河北省排名第22(中国国家统计局,未注明日期)。在BTHUA中,保定、邢台、邯郸等城市的城中村/村比例较高,可能与河北省大量农村地区有关。在YRDUA中,住宅建筑占据了最大类别,占比超过46%。在三个主要城市群中,YRDUA的商业建筑比例最高,达到了2.3%,这显示了其在商业上的繁荣程度。相反,PRDUA中的工厂建筑比例明显高于其他两个城市群,这与PRDUA作为改革开放的前沿和世界工厂的制造业发达密切相关(Li等,2022年)。总体而言,建筑功能比例的结果和分析表明,YRDUA在三个主要城市群中最适合商业开发,而PRDUA则在工业方面特别发达。
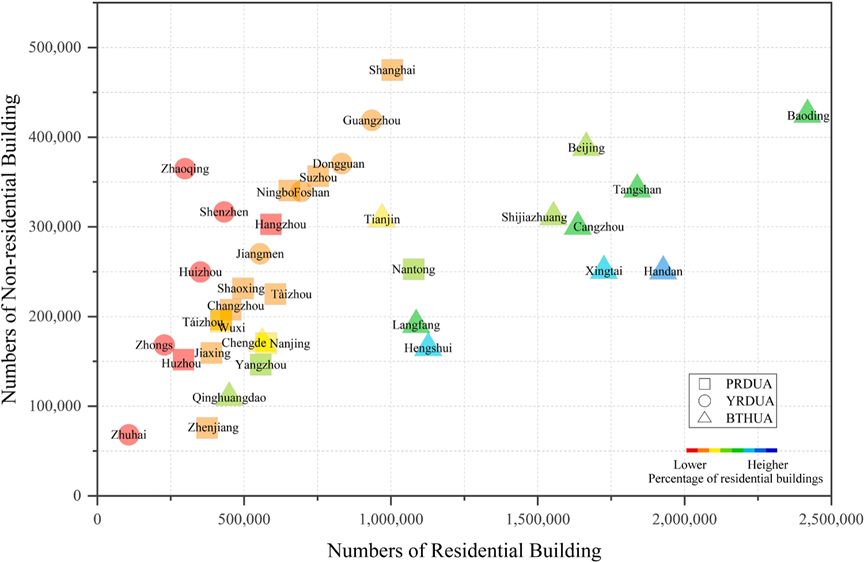
图 10 住宅建筑与非住宅建筑数量的散点图
图10展示了每个城市中的住宅建筑(城市住宅和城中村/村)和非住宅建筑的数量,用红色表示非住宅建筑比例高的城市,用蓝色表示住宅建筑比例高的城市。观察发现,PRDUA中的大多数城市具有较高的非住宅建筑比例,而BTHUA中的大多数城市则具有较高的住宅建筑比例。此外,图中突出显示了如上海、广州、保定和北京等城市的非住宅建筑数量都超过了38万栋。此外,珠江三角洲和长江三角洲城市群中的城市在散点图中较为接近,暗示了这些城市发展战略的相似性。相比之下,BTHUA中的城市分布更为分散,表明城市之间的建筑数量和比例差异较大。这意味着BTHUA中的城市在发展战略上并不完全一致,违背了城市群城市一体化的理念。在制定政策时,决策者应更加关注城市群内城市发展战略的协调性。
【结论】
本研究提出了一种基于POI数据、建筑环境信息和建筑轮廓几何特征的方法,以快速识别大范围区域内单栋建筑的功能。我们在研究中详细考察了不同特征组合的影响,并采用了包括随机森林、决策树和前馈神经网络等多种算法,评估了它们对建筑功能准确识别的效果。通过一系列实验,我们的发现不仅确认了所选特征的有效性,还揭示了它们的最佳组合。这些实验扩展到了迁移场景,结果突显了建筑环境的重要性。虽然在随机抽样且样本分布均匀的情况下,建筑环境信息可能不会显著提高准确性,但在迁移实验中其效用变得明显。基于这些实验,我们成功识别了中国三个主要城市群中超过3900万栋建筑的功能分类。验证过程进一步确认了我们方法的可行性,三大城市的模型测试样本准确率均超过0.93,Kappa系数超过0.86。建筑分类的结果以三维方式进行了全面展示。此外,我们详细分析了38个城市中不同建筑类别的数量和比例。分析揭示了一个一致的模式:在每个城市和城市群中,住宅建筑(无论是城市住宅还是城中村/村)的比例和数量始终排名第一。由于城市化率较低,BTHUA的城中村/村比例较高,而YRDUA则表现出较高的商业建筑比例,而以工业著称的PRDUA则具有比其他两个城市群更多的工厂建筑。与其他两个主要城市群中的城市较为相似相比,BTHUA中的城市住宅比例更高,建筑比例差异更大,这表明在制定政策时应更加考虑城市之间的差异。BTHUA中建筑功能的独特动态和变化需要更有针对性和细致的政策制定,考虑到每个城市在城市群中的具体需求和挑战。
未来的研究应致力于解决本研究的局限性。首先,鉴于研究的广泛范围和大量建筑数据,应进行更全面的验证过程。本研究提到,仅选取了少数城市中的部分建筑进行验证,我们将扩大验证过程,涵盖来自不同城市的更多具有代表性的建筑样本。其次,本研究获取的建筑功能指的是建筑的主要功能。为了提供更细致的理解,未来的研究可以探讨识别单栋建筑的多重潜在功能,以反映其实际使用情况,例如混合住宅和商业功能。这可能涉及开发一个更精细的分类系统,包括数十个类别,并建立准确性验证机制。第三,在计算建筑与其他实体(如最近建筑、城市中心、道路和水道)的接近度时,我们使用了欧几里得距离,主要是为了降低计算成本。未来的实验可以考虑使用更现实的替代距离度量,如曼哈顿距离或网络距离。最后,尽管本研究涵盖了中国广泛的区域,但涉及的建筑都是中国风格的。模型所需的数据在美国和欧洲也可用。因此,当这些地区和国家的数据可用时,可以验证该方法在不同地理和文化背景下的适用性。例如,调整不同国家建筑环境的建筑分类。
总之,本研究获得的所有结果表明,我们的方法在大范围尺度内识别单栋建筑功能的效果显著,并成功填补了低成本、高效率、高准确性的大区域单栋建筑功能识别的空白。同时,本研究结果也为城市问题的探索提供了更多可能性。建筑分类数据作为分析城市生活各个方面的基础元素。例如,未来的城市研究可以将人口数据与建筑功能分类数据结合,以计算街道和城市尺度的人均住宅面积、适龄儿童的教育资源、人均公共设施以及不同区域居民的医疗设施可达性。通过识别资源的分布不均和不足,可以为城市更新、改善生活环境以及公共设施和基础设施规划选址提供建议和决策支持。此外,建筑功能识别的成就为城市能源供应、建筑碳排放以及城市的精细三维空间研究提供了重要的数据支持。总之,我们研究结果的综合性不仅为建筑功能识别领域做出了贡献,还扩展了此类数据在城市研究和规划的多种潜在应用。
