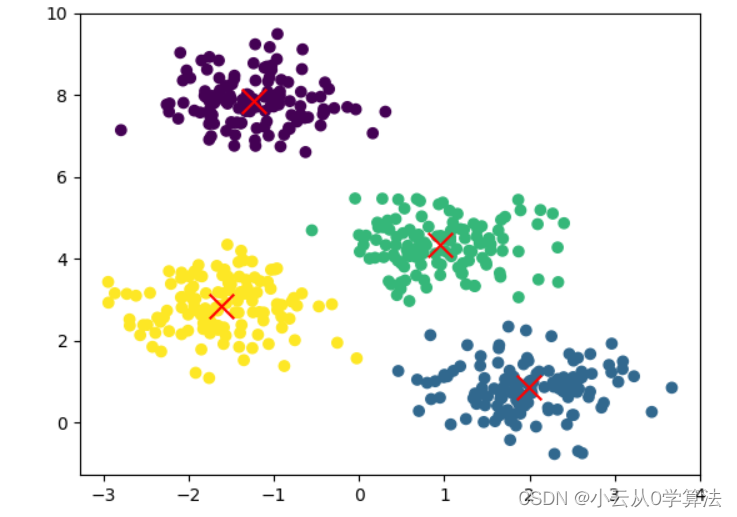
聚类 kmeans | 机器学习
聚类 刘建平
1、算法原理:
是一种无监督学习算法,其主要目的是将数据点分为k个簇,距离近的样本具有更高的相似度,距离近的划分为一个簇,一共划分k个簇,**让簇内距离小,簇间距离大。**距离是样本点到之心的距离。所有样本点到质心距离之和最小,就认为样本越相似。
- 聚类和分类区别
簇内平方和:
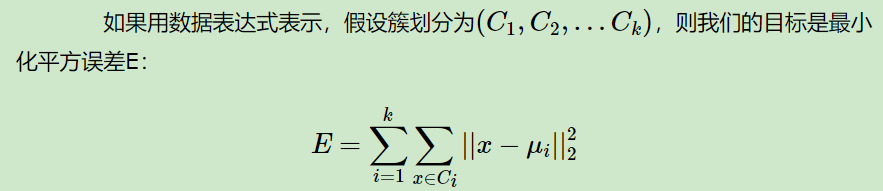

质心 :簇中所有data的均值为质心
k:簇的个数
2、聚类流程
随机选取k个质心点,形成初始簇,定义代价函数(簇内平方和)开始计算每个样本点到初始质心的距离,定义迭代轮数或者(函数收敛,簇新不发生变化)再次形成新的簇,又会形成新的质心点,反复迭代。
质心:样本集所有data的均值
K:簇的个数
1、初始化聚类中心:随机选取k个样本点作为初始质心位置,计算每个质心点周边点到该点的距离,
2、根据距离分组:计算每个数据点与聚类中心之间的距离,把每个样本点分配到距离最近的初始质心上,形成最初的簇。
3、重新计算聚类中心:对每个组重新计算聚类中心,求解簇中所有样本点的均值点,作为新的质心
4、判断是否结束:把每个样本点重新分配到距离最近的质心上,再形成新的簇。(类中心的位置不断地被更新,直到聚类中心的位置不再发生变化或达到最大迭代次数。当两次迭代的聚类中心位置趋于相同时,其欧氏距离之和会逐渐减小。因此,如果两次迭代的聚类中心位置趋于稳定时,其欧氏距离之和会小于预设的阈值(如0.0001),可以认为本次迭代已经趋近于收敛,算法可以终止。)
5、输出:输出聚类结果,即每个数据点所属的组别。

3、模型评估指标
轮廓系数
簇内差异小,簇外差异大,样本与自身所在簇内其他点的平均距离要永远小于,与簇外所有样本点的平均距离。


4、Kmeans 与knn区别
kmeans是无监督,没有样本输出,knn不需要训练,对测试集的点,只需要找到在训练集中最近的k个点,用最近的k个点来决定测试点的类别。
相似之处都是最近邻思想,找出和某一个点最近的点。
5、K-means算法有哪些优缺点?有哪些改进的模型?
1、优点:
计算简单,聚类效果好
算法可解释性较强,调参容易,仅仅是k
2、缺点:
1、初始聚类中心的选择标准
k值不好把握,人工预先确定初始K值
改进方法:
对初始聚类中心的选择的优化。一句话概括为:选择批次距离尽可能远的K个点。具体选择步骤如下。
首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
2、无法对噪音和异常点有效区分
如果噪声点在空间上离各个聚簇中心都比较远,那么将其单独分为一个簇可能是合理的。但是,通常情况下,噪声点是不相关的或者异常的,如果将其单独分配到某个簇中,可能会影响其他簇的正确性和一致性,从而导致聚类结果不准确。
不是凸的数据集比较难收敛,
计算量大
6、常见的聚类算法
1 DBSCN 基于密度的聚类算法,按密度聚类,低密度为噪声,簇的个数由k确定。
7、python实现
import numpy as np
import matplotlib.pyplot as pltclass KMeans:def __init__(self, n_clusters, max_iters=100, random_state=42):self.n_clusters = n_clustersself.max_iters = max_iters #迭代次数self.random_state = random_statedef fit(self, X):# 随机初始化中心点random_state = np.random.RandomState(self.random_state)self.centers = X[random_state.choice(range(X.shape[0]), self.n_clusters, replace=False)]it = 0while it < self.max_iters:# 计算每个样本到各个聚类中心的欧氏距离dists = np.sqrt(((X[:, np.newaxis, :] - self.centers) ** 2).sum(axis=-1))# 找到距离最近的聚类中心labels = dists.argmin(axis=-1)new_centers = np.empty_like(self.centers)# 更新聚类中心for i in range(self.n_clusters):new_centers[i] = X[labels == i].mean(axis=0)# 判断聚类中心是否发生变化if np.allclose(new_centers, self.centers, rtol=1e-4, atol=1e-4):breakself.centers = new_centersit += 1def predict(self, X):dists = np.sqrt(((X[:, np.newaxis, :] - self.centers) ** 2).sum(axis=-1))return dists.argmin(axis=-1)
# ```# 使用示例:# ```python
from sklearn.datasets import make_blobsX, _ = make_blobs(n_samples=500, centers=4, cluster_std=0.60, random_state=0)km = KMeans(n_clusters=4)
km.fit(X)plt.scatter(X[:, 0], X[:, 1], c=km.predict(X))
plt.scatter(km.centers[:, 0], km.centers[:, 1], s=200, marker='x', c='red')
plt.show()
# ```
输出结果: