PAT甲级 1076 Forwards on Weibo(30)
文章目录
- 题目
- 题目翻译
- 深度优先搜索(dfs)
- 宽度优先搜索(bfs)
- 总结
原题链接
题目

题目翻译
微博被称为中国的推特。在微博上,一个用户可能有很多粉丝,也可能关注许多其他用户。因此,通过粉丝关系形成了一个社交网络。当一个用户在微博上发表帖子时,他/她所有的粉丝都可以查看和转发他/她的帖子,然后这些帖子可以被他们的粉丝再次转发。现在,假设只计算L级的间接粉丝,需要计算任何一个特定用户的最大潜在转发量。
输入格式
每个输入文件包含一个测试用例。对于每个案例,第一行包含两个正整数:N(≤1000),用户的数量;L(≤6),被计算的间接粉丝的级别数。因此,所有用户都被假设编号从1到N。然后是N行,每行的格式如下:
M[i] user_list[i]
其中 M[i](≤100)是用户[i]关注的总人数;user_list[i] 是用户[i]关注的 M[i] 个用户的列表。保证没有人会关注自己。所有数字之间用空格分隔。
然后最后给出一个正整数 K,后面跟着 K 个用户ID用于查询。
输出格式
对于每个用户ID,你需要在一行中打印出这个用户可以触发的最大潜在转发量,假设每个可以看到初始帖子的人都会转发一次,并且只计算L级的间接粉丝。
基本思路
求一个用户的最大潜在转发量,就是一层一层地去找粉丝数,不超过L层。每次一层一层去找粉丝数时我们需要知道当前用户是在第几层?是否转发过?到这里,我一开始想到的是用dfs(深度优先搜索),但是最后一个用例超时了,应该是递归调用太多了,爆栈了。所以得用bfs(宽度优先搜索),将该层的用户编号和该用户的层数用一个队列存储起来,然后遍历每个用户的粉丝编号,如果没有转发过答案就+1,如果当前层数<最大层数L,就将它的粉丝编号和它的层数入队
深度优先搜索(dfs)
思路比较简单,先定义一个用户结构体userID,结构体里面存储vector容器,vector存储关注该用户的粉丝编号。再定义结构体数组user[M],将全部用户编号以及该用户的粉丝编号存储起来。
struct userID {vector<int> m;
}user[M];
再来看递归函数dfs的写法,将当前用户的粉丝编号遍历一遍,vis数组用来标记当前用户是否转发过,如果为false,最大转发量就+1,然后标记当前用户为true。然后再判断该层是否小于最大层数L,如果小于就继续递归该粉丝和下一层层数。
void dfs(int id,int l)
{for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if(l<L){dfs(user[id].m[i],l+1);}}
}
完整代码
#include<iostream>
#include<vector>
#include<cstring>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void dfs(int id,int l)
{for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if(l<L){dfs(user[id].m[i],l+1);}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;dfs(k[i], 1);cout << ans << endl;}return 0;
}
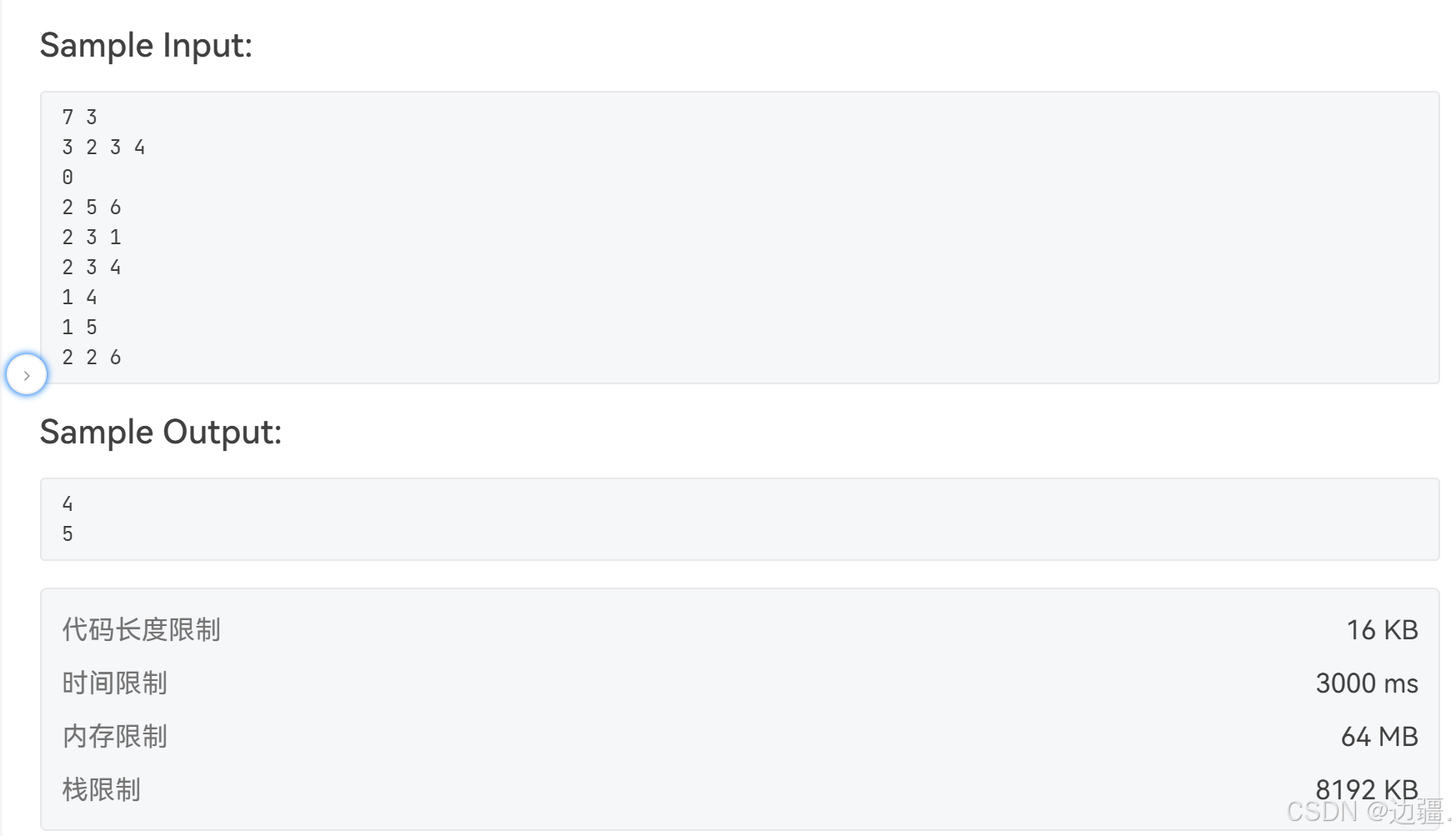
通过评测结果发现只过了90%的样例,最后一个运行超时。可能原因就是递归调用太多,导致栈溢出。
递归搜索dfs不行,可以尝试使用非递归搜索bfs
宽度优先搜索(bfs)
延续上述思路,先创建一个队列,该队列存储的是对组pair<int,int>,对组第一个数是用户编号id,第二个数是当前用户所在的层数
queue<pair<int, int>> q;
q.push({用户编号id,用户所在的层数});
步骤
(1)判断当前队列是否为空,如果不为空,获取队头,
(2)遍历该用户的所有关注者——>如果没有转发过则最大转发量+1(再将该关注者标志为转发过),判断该用户的当前层数是否小于最大层数L,如果小于则将该关注者的编号和所在层数入队,注意:关注者的所在层数要加一
q.push({ user[id].m[i],level + 1 });
将发表帖子的用户编号以及层数(层数为1)入队,再重复步骤(1)(2) 直到队列为空
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}}}
}
完整代码
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
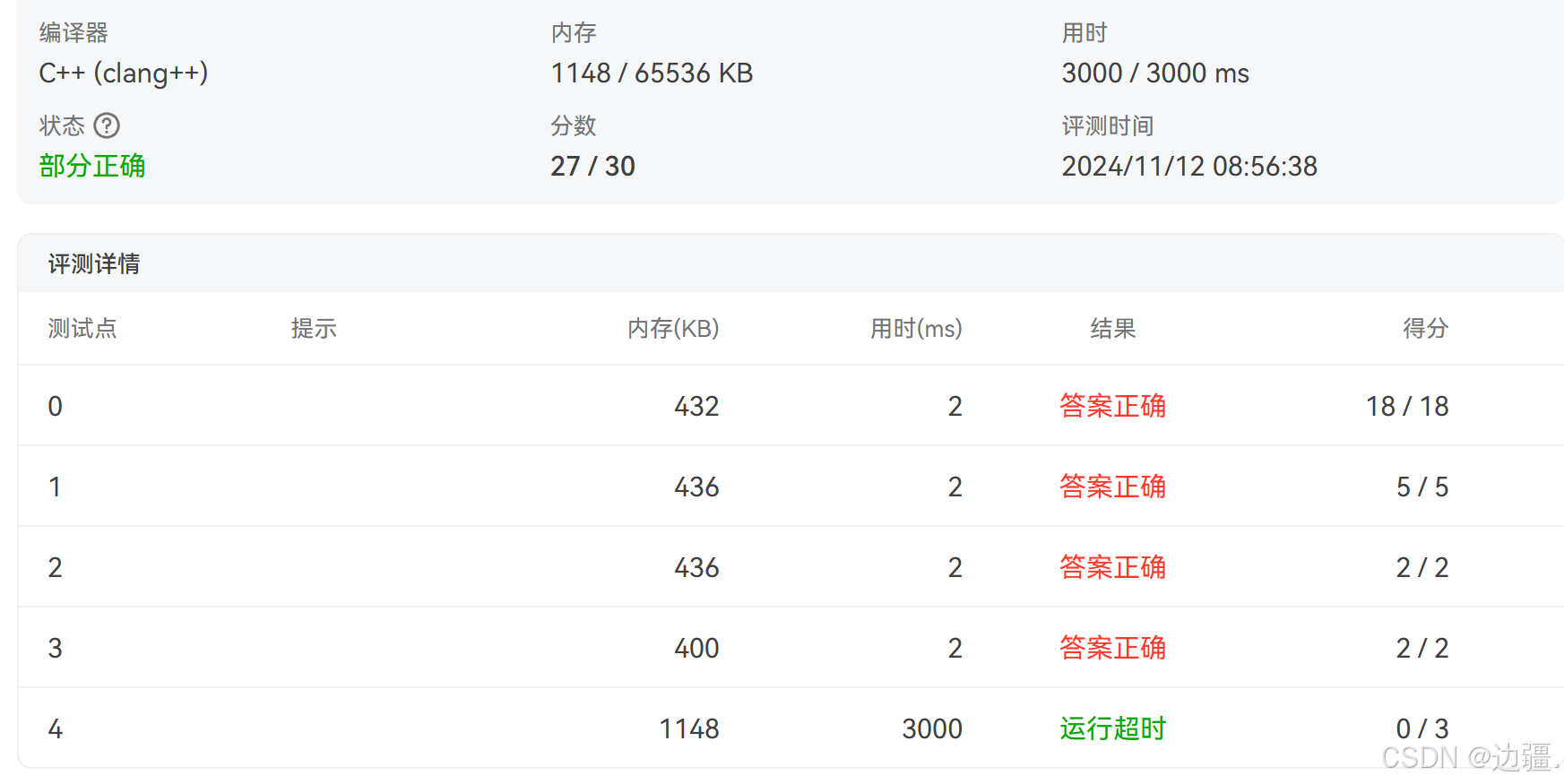
通过评测结果发现还是只过了90%的样例,报错结果是内存超限,那么可能的原因就是堆内存溢出。
我们仔细看下面的代码可以发现:不管当前用户的关注者是否转发过帖子,只要当前用户的层数小于最大层数L,那么该用户的所有关注者都会入队。实际上是没有必要的,如果该用户的某个关注者已经转发过,再将其入队会造成重复查询(到下一层再查询该关注者的所有关注者时,发现已经全部转发过),使内存消耗更大,从而导致堆内存溢出。
for (int i = 0; i < user[id].m.size(); i++)
{if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;}if (level < L){q.push({ user[id].m[i],level + 1 });}
}
那么应该怎么改?——>只有当前用户的关注者没有转发过且当前层数小于最大层数L,才能将关注者编号和下一层层数入队。
for (int i = 0; i < user[id].m.size(); i++)
{if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}
}
这种写法相当于剪枝,就是将没有必要搜索而且不影响结果的分支去除掉,这样既提高了搜索效率,也节省了计算资源。
剪枝是一种在算法中减少搜索空间的技术,特别是在解决优化问题和决策问题时使用。它的核心思想是在搜索过程中提前排除那些不可能产生最优解或者不符合特定条件的分支,从而减少不必要的计算和资源消耗。
还有一种剪枝的写法(个人不建议)
for (int i = 0; i < user[id].m.size(); i++)
{//不推荐这种写法,因为可能还要将最高层的用户编号入队列,但是已经判断过最高层的用户是否转发过了
// if (vis[user[id].m[i]] == false && level<=L)
// {
// ans += 1;
// vis[user[id].m[i]] = true;
// q.push({ user[id].m[i],level + 1 });
// }//推荐这种写法if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}
}
完整代码
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
struct userID {vector<int> m;
}user[M];
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id,1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < user[id].m.size(); i++){if (vis[user[id].m[i]] == false){ans += 1;vis[user[id].m[i]] = true;if (level < L){q.push({ user[id].m[i],level + 1 });}}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;user[x].m.push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
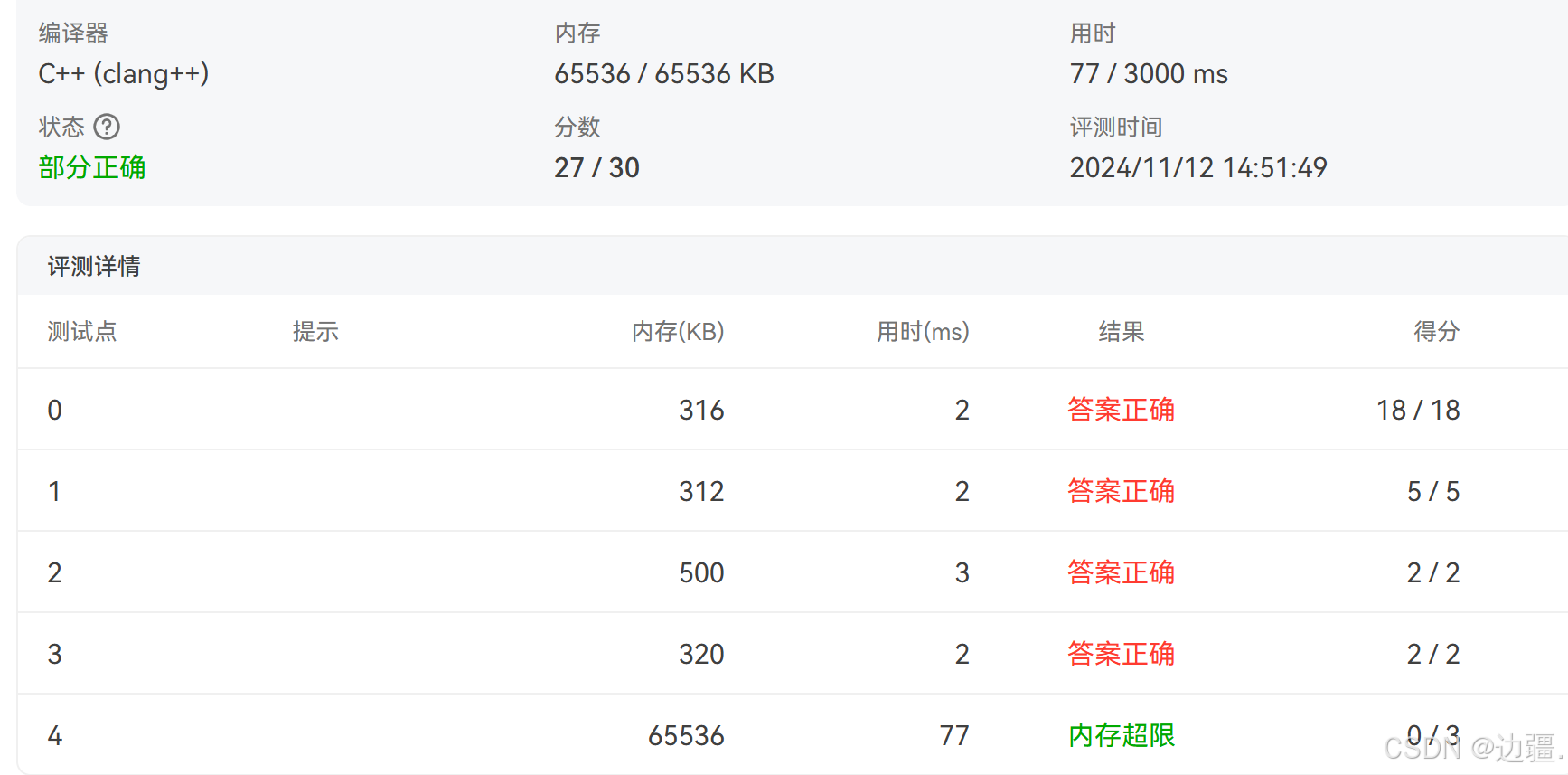
通过评测结果发现通过了全部样例
个人的另一种写法
此写法直接开辟了二维动态数组,省去了创建结构体和结构体数组,但实际上大同小异。
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int M = 1010;
typedef long long ll;
int N, L, K;
int k[M];
bool vis[M];
vector<vector<int>> vc(M);
ll ans = 0;
void bfs(int id)
{queue<pair<int, int>> q;q.push({id, 1});while (!q.empty()){auto node = q.front();q.pop();int id = node.first;int level = node.second;for (int i = 0; i < vc[id].size(); i++){if (vis[vc[id][i]] == false){ans += 1;vis[vc[id][i]] = true;if (level < L){q.push({vc[id][i], level + 1});}}}}
}
int main()
{cin >> N >> L;for(int i=1;i<=N;i++){int u;cin >> u;for (int j = 0; j < u; j++){int x;cin >> x;vc[x].push_back(i);}}cin >> K;for (int i = 0; i < K; i++){cin >> k[i];}for (int i = 0; i < K; i++){ans = 0;memset(vis, false, sizeof vis);vis[k[i]] = true;bfs(k[i]);cout << ans << endl;}return 0;
}
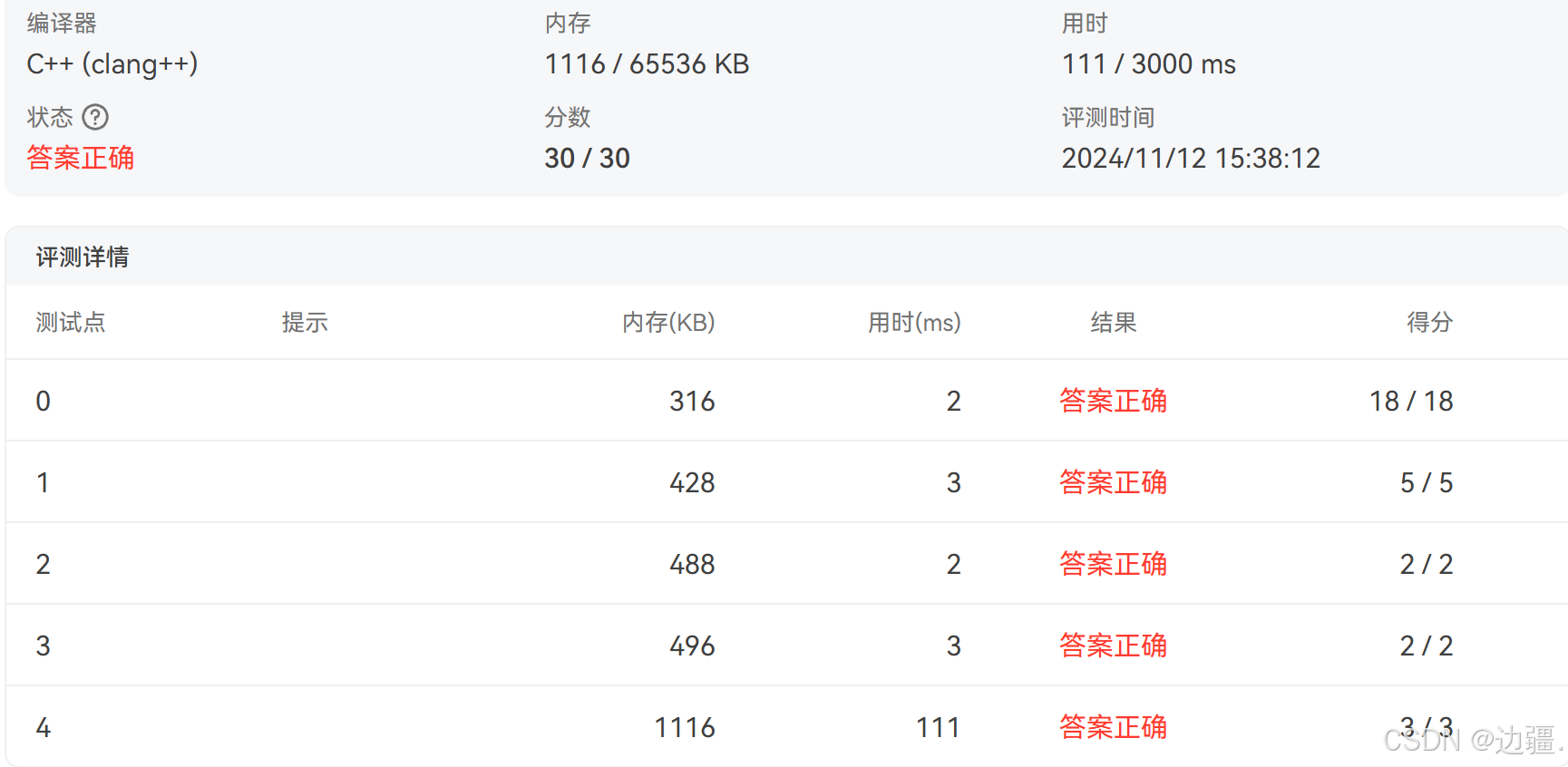
评测结果显示通过了全部样例
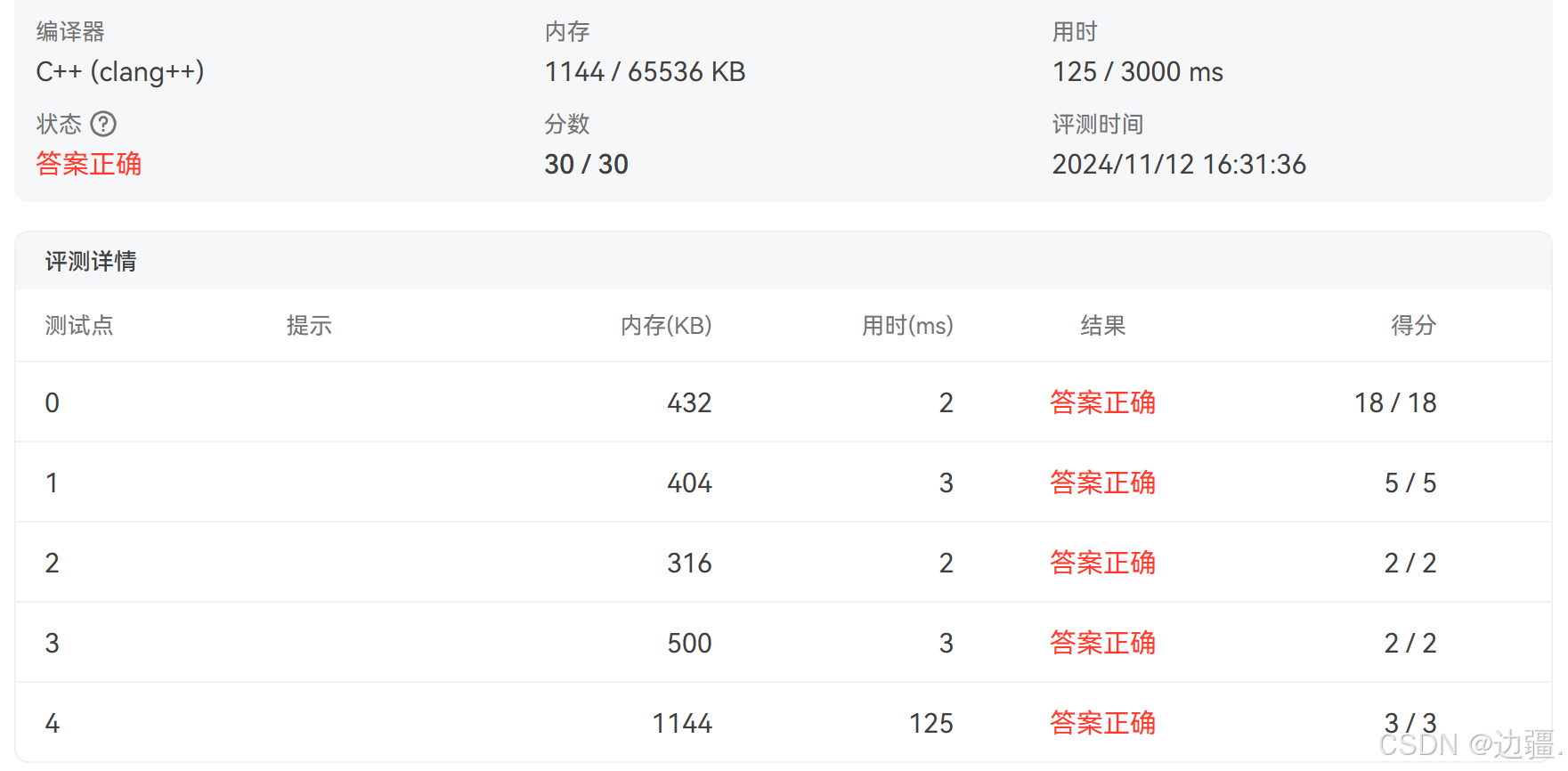
yxc的写法
此写法用邻接表来存储图,需要注意的是一共有1000个点,每个点最多存100条边,所以点数N可以开1e3+10,边数M最多为1e5+10。
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;//点数和边数
const int N=1e3+10,M=1e5+10;int n,l;
int h[N],e[M],ne[M],idx; //用邻接表来存储图
bool st[N]; //状态数组//头节点
void add(int a,int b){e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}int bfs(int start){queue<int> q;memset(st, 0, sizeof st);q.push(start); //队列初始化st[start]=true;int res=0;//l为关注着的层数for(int i=0;i<l;i++){ //i为每层的关注者int sz=q.size();//注意:这个while中sz为每层关注着的人数,所以要暂存while(sz--){auto t=q.front();q.pop();//遍历start的第i层关注者for(int j=h[t];j!=-1;j=ne[j]){auto x=e[j]; //e[j]存放关注者的编号if(!st[x]){q.push(x);st[x]=true;res++;}}}}return res;
}int main(){cin>>n>>l;memset(h,-1,sizeof h);for(int i=1;i<=n;i++){int cnt; //第i名用户关注的总人数cin>>cnt;while(cnt--){int x;cin>>x;add(x,i); //i是x的粉丝,让x指向i}}int m;cin>>m;while(m--){int x;cin>>x;cout<<bfs(x)<<endl;}return 0;
}
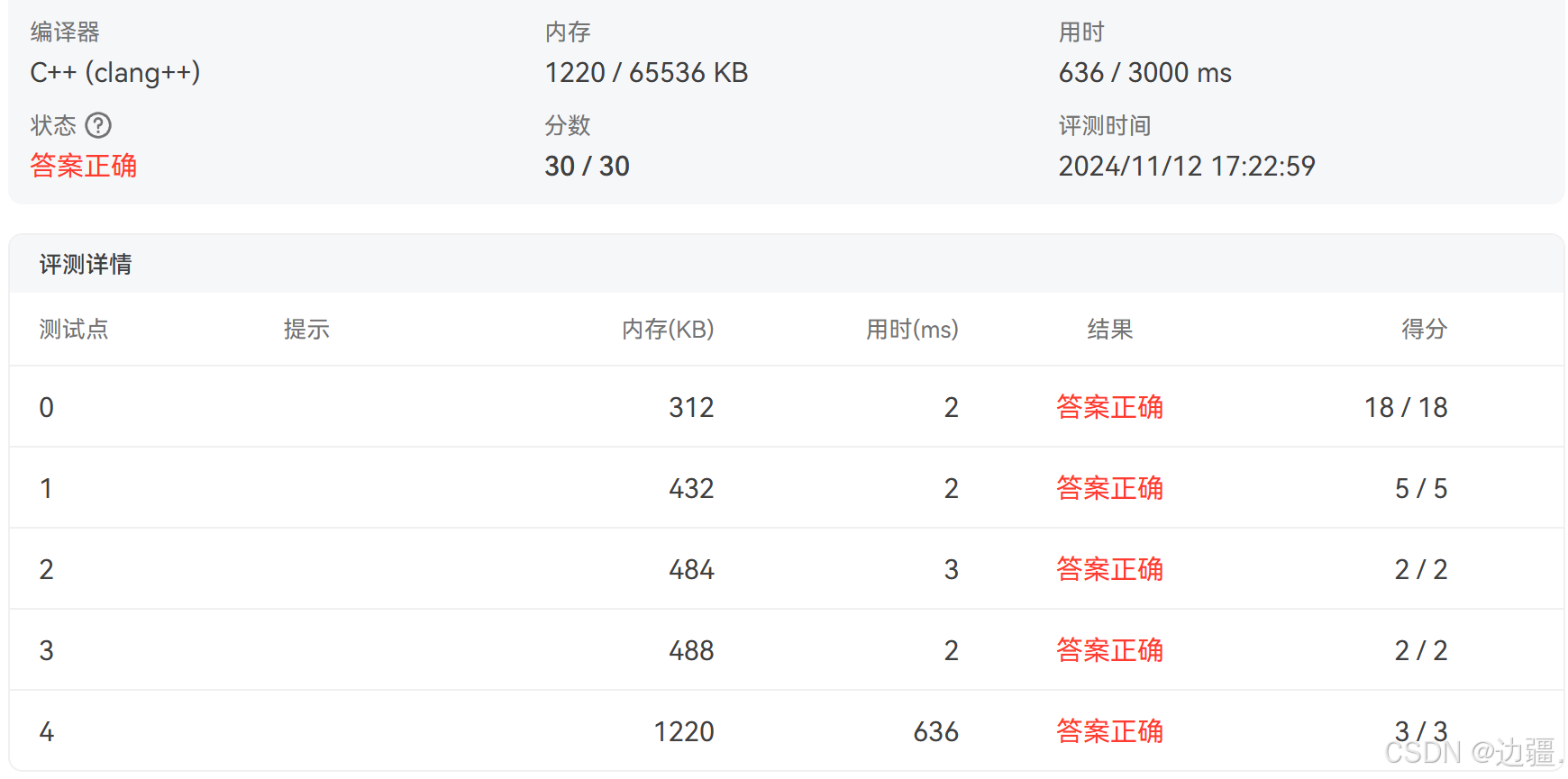
评测结果显示通过了全部样例
总结
这道题的英文单词有点难理解,比如:forward:转发,follower:粉丝,indirect:间接地
这些单词需要结合上下文才能慢慢读懂,比如forward很多人会翻译成向前的意思
对于深度优先搜索(dfs)和宽度优先搜索(bfs),我们优先考虑能不能使用bfs+剪枝一次通过,因为dfs的局限性有点大,数据稍微大一点就很容易超时(当然也可以通过dfs+剪枝来降低时间复杂度,但是不确定能不能通过)
到这里就结束啦,对以上内容有异议的欢迎大家来讨论。