存储数据库的传输效率提升-ETLCloud结合HBASE
一、大数据存储数据库–HBASE
HBase,作为一个开源的分布式列存储数据库,基于Google的Bigtable设计而成,专为处理大规模结构化数据而优化。使用HBase打造大数据解决方案的好处主要包括:高可扩展性,能够处理PB级的数据;实时读取和写入能力,适合实时数据分析;灵活的模式设计,支持动态列的添加,便于快速适应变化的需求;以及与Hadoop生态系统的紧密集成,增强了数据处理和分析的能力。因此,HBase在大数据存储与处理方面被广泛应用,成为企业实现数据驱动决策的强大工具。

二、选择ETLCloud对数据进行ETL并加载到HBASE数据源
数据集成和管理平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。选择强大的数据迁移工具ETLCloud,可以轻松完成大数据存储解决方案。
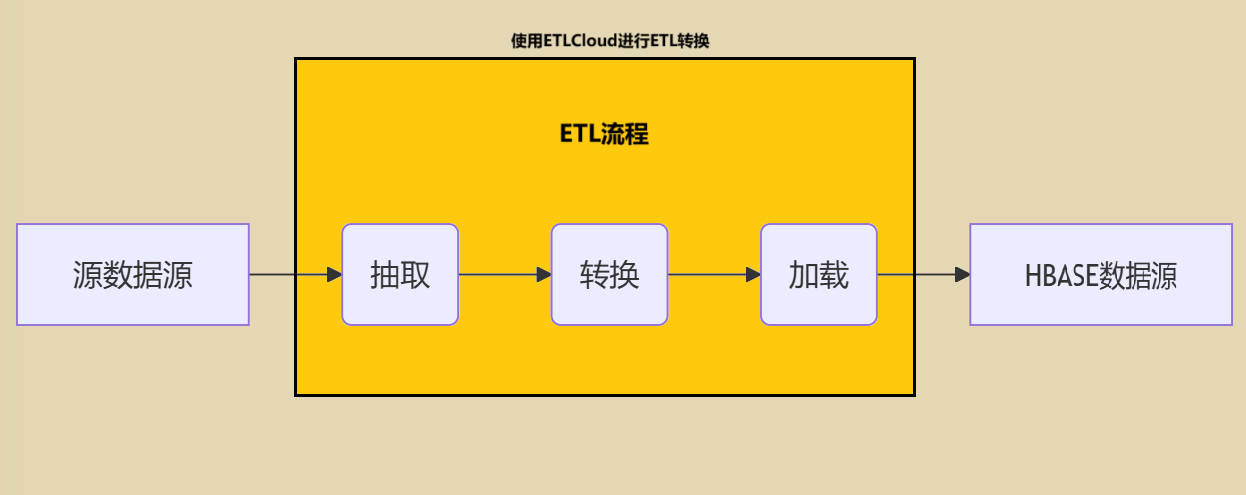
三、使用ETLCloud零代码快速构建ETL流程
流程设计:
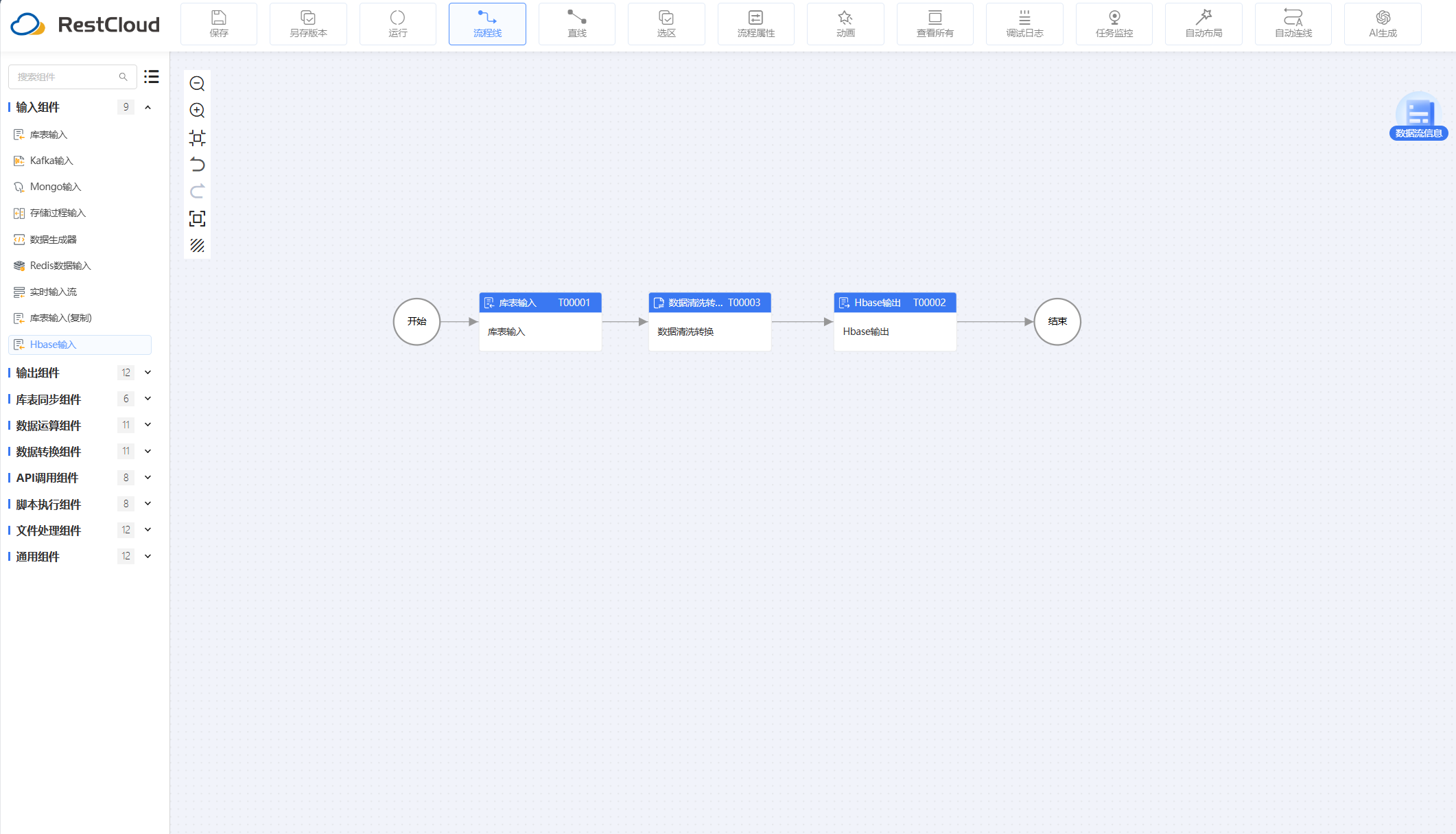
准备工作:
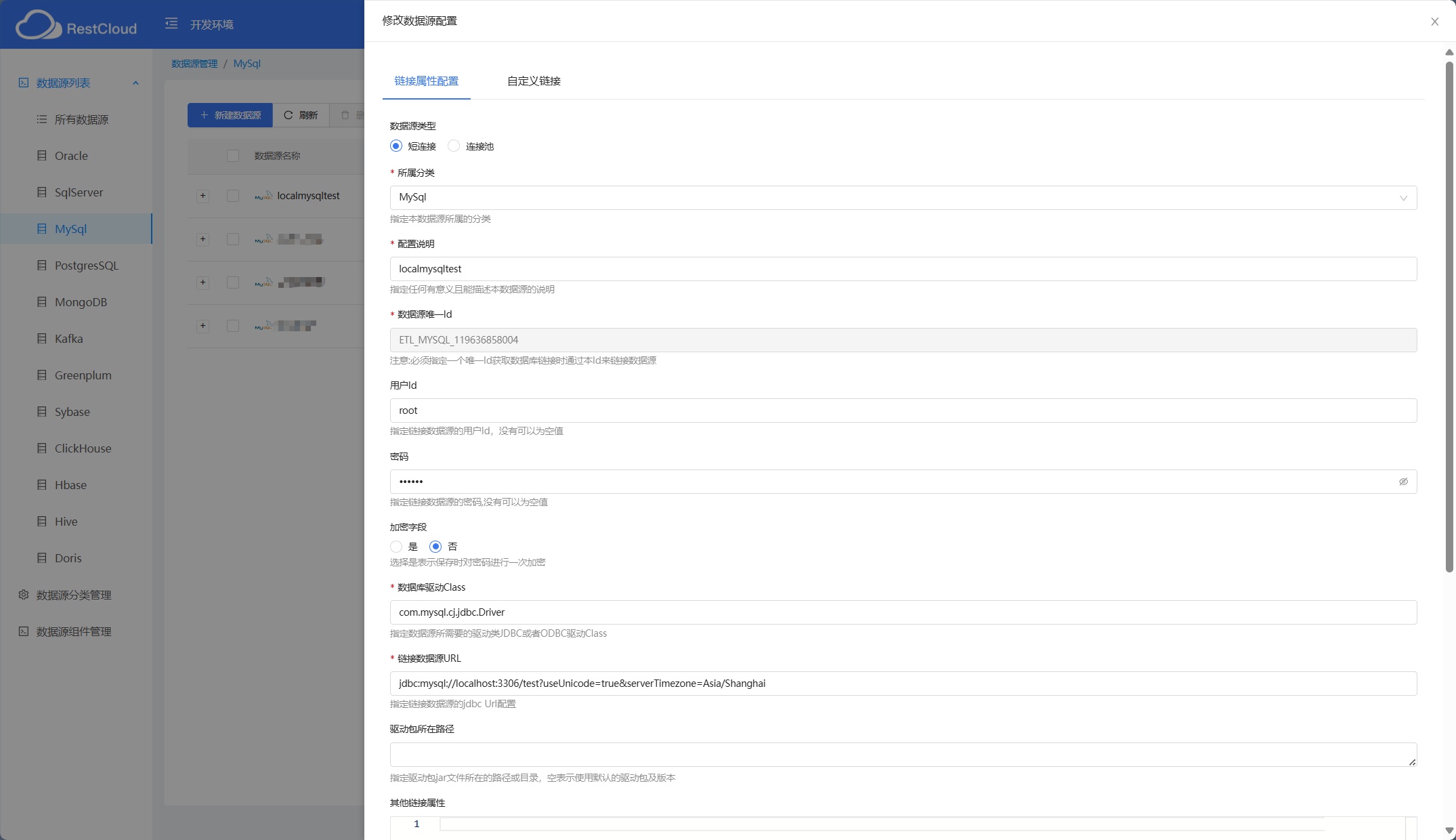
配置源表数据源:
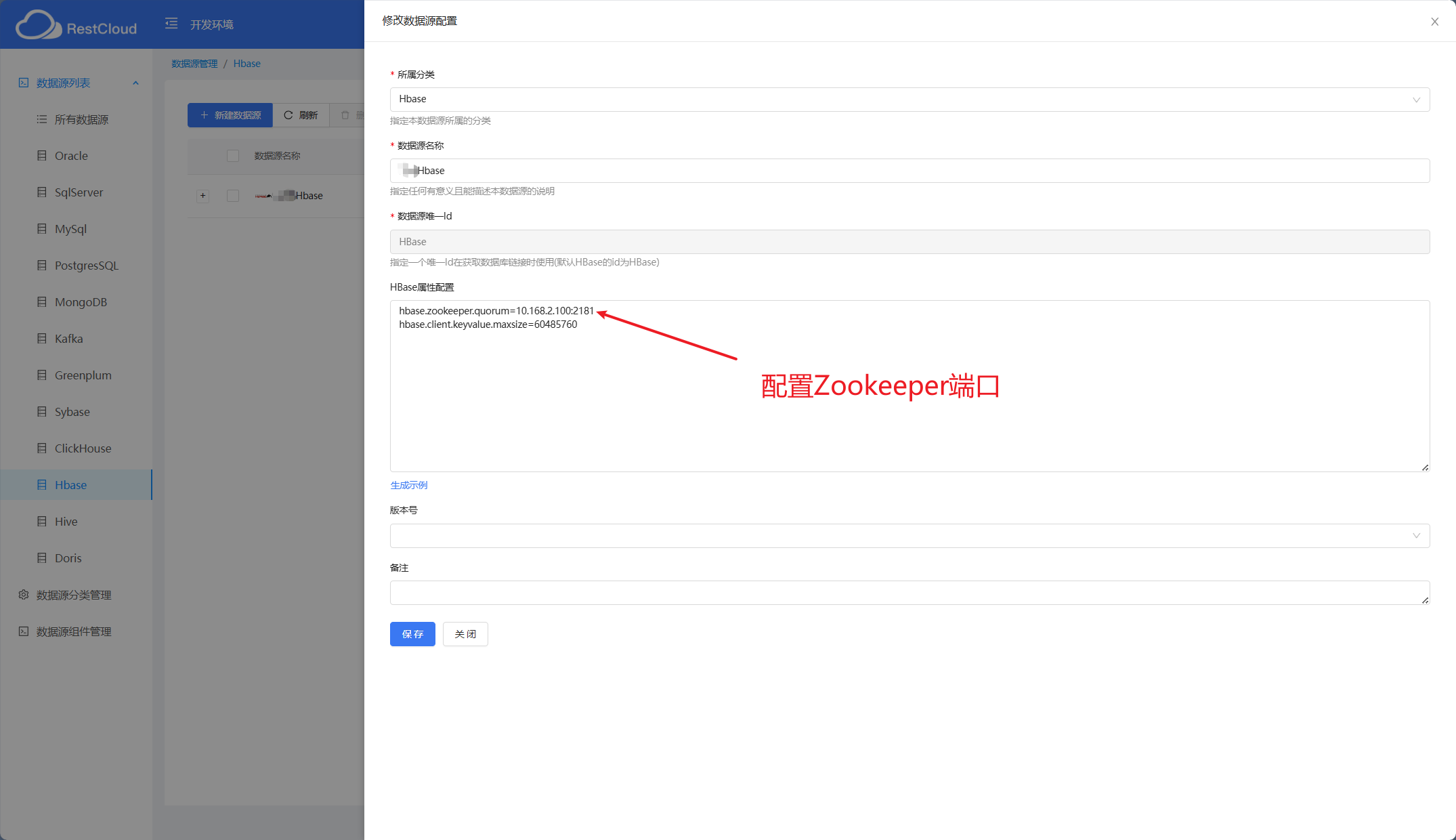
配置Hbase数据源:
组件设置:
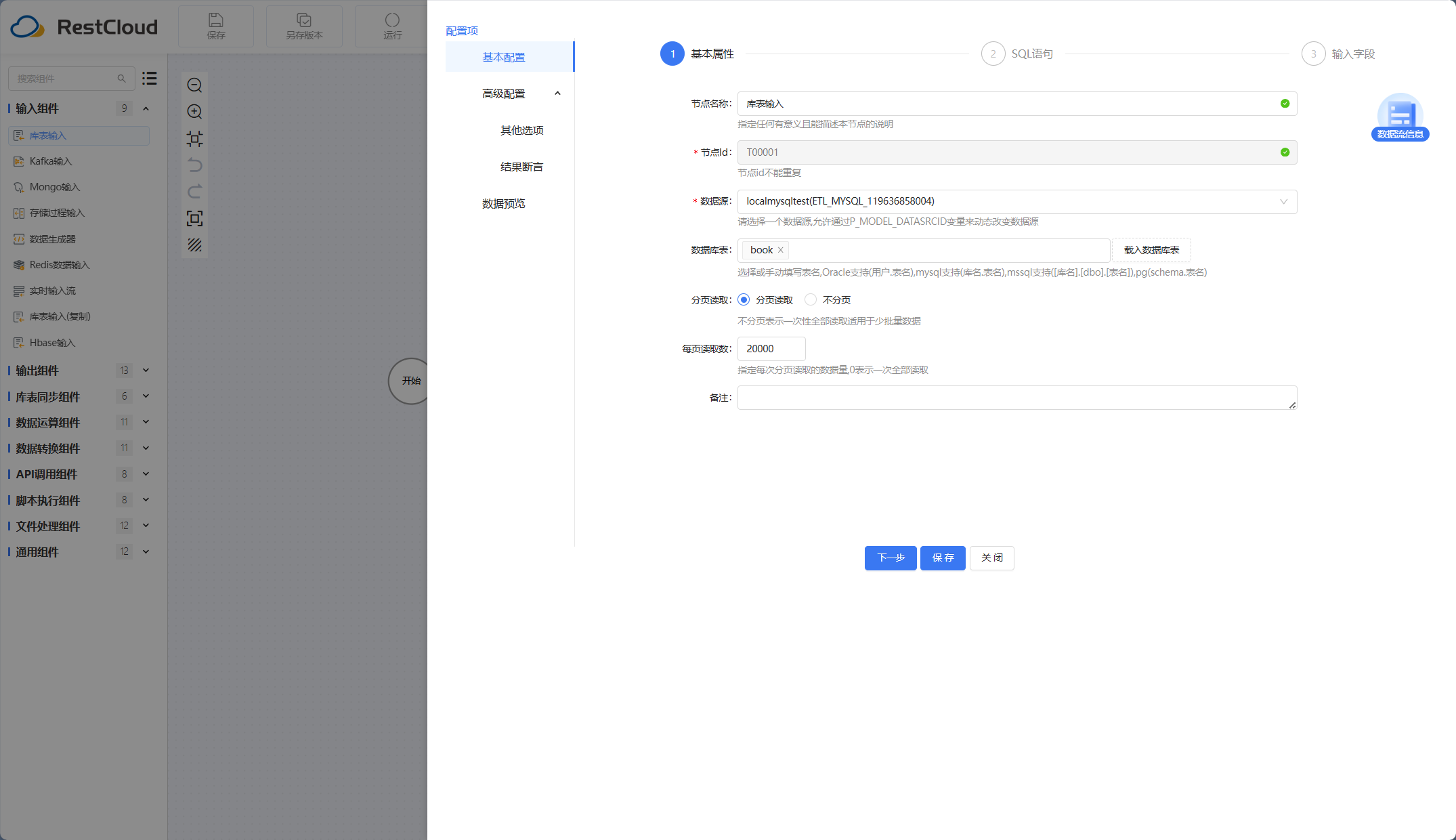
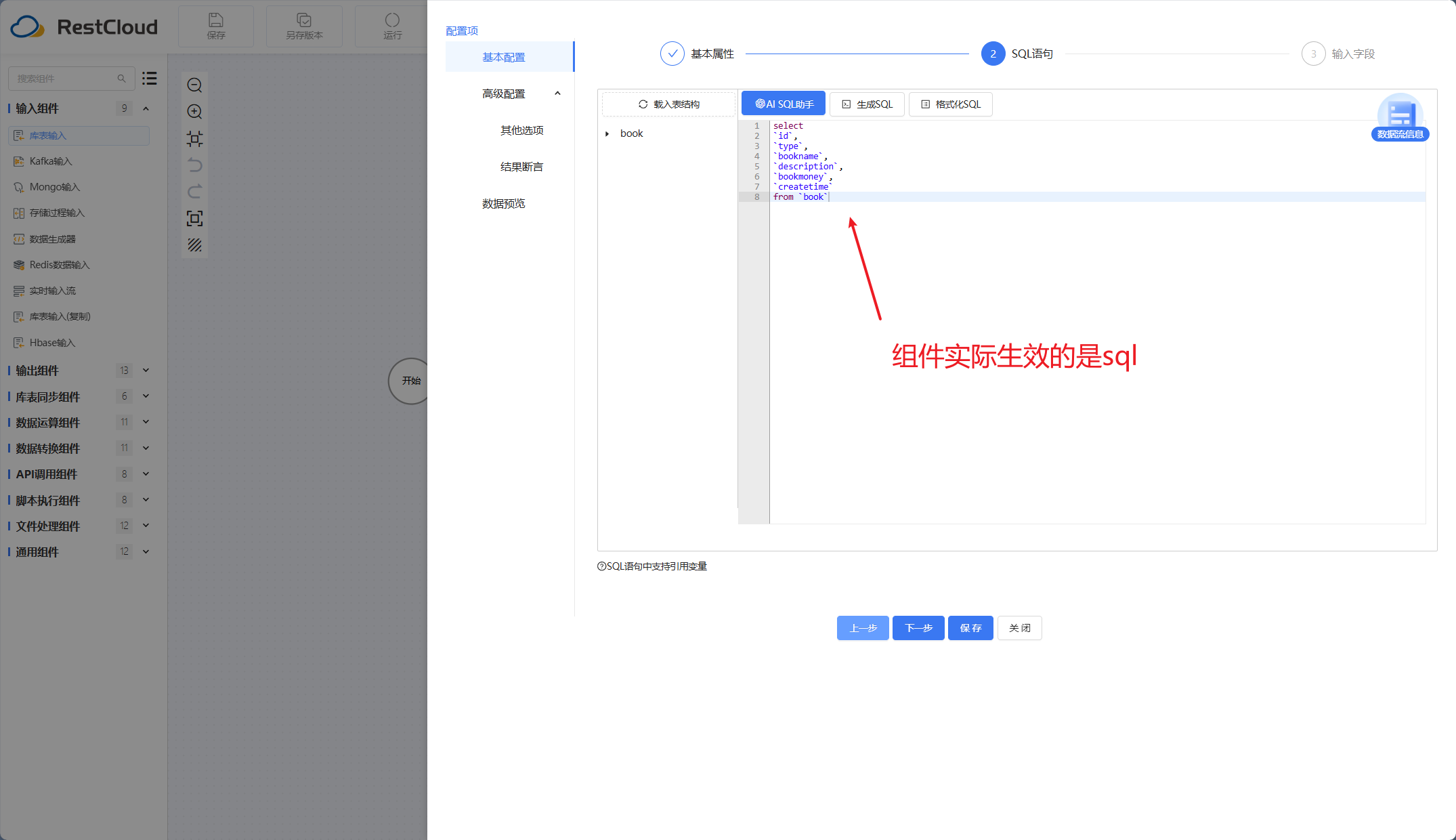
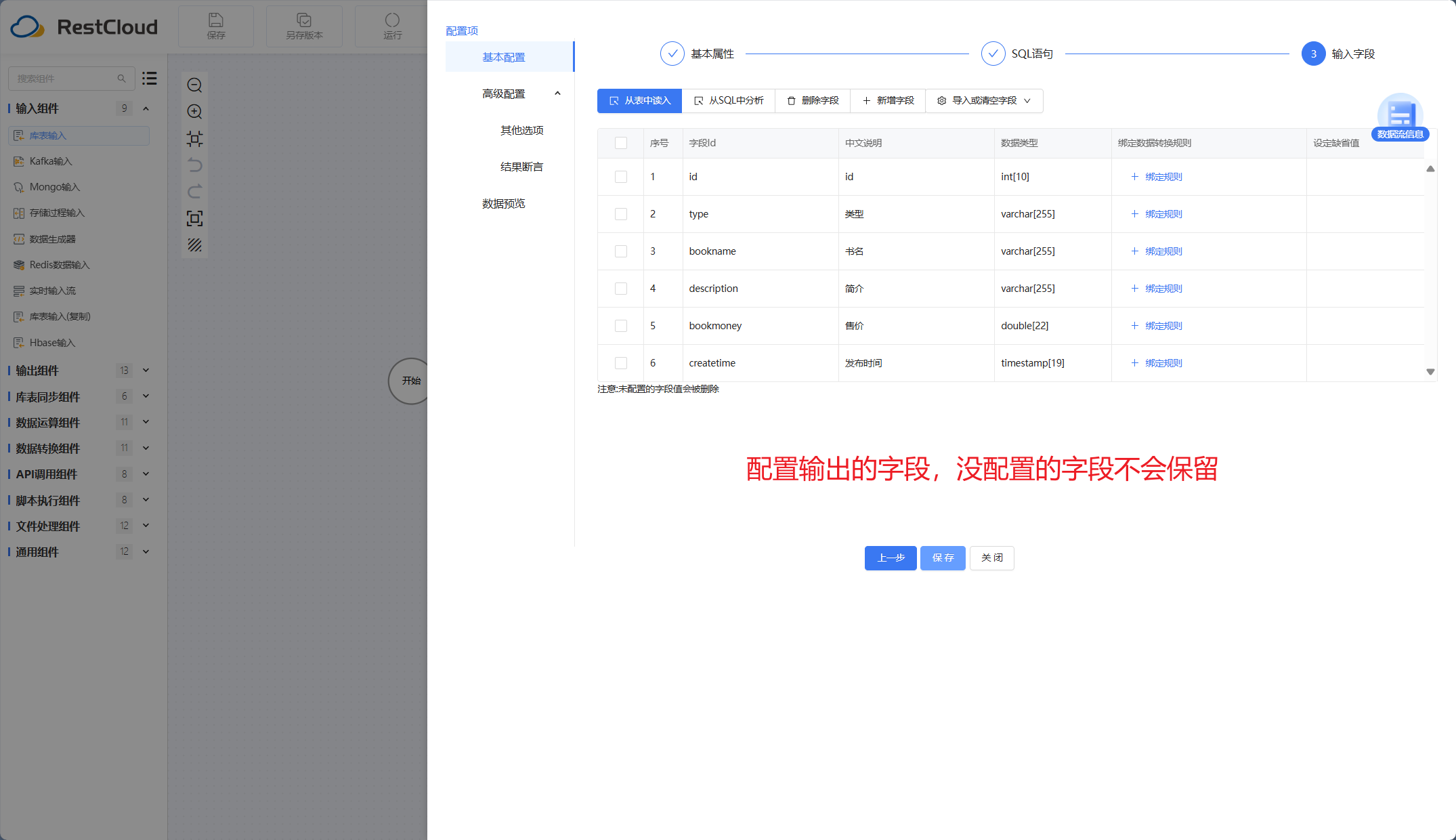
库表输入组件:
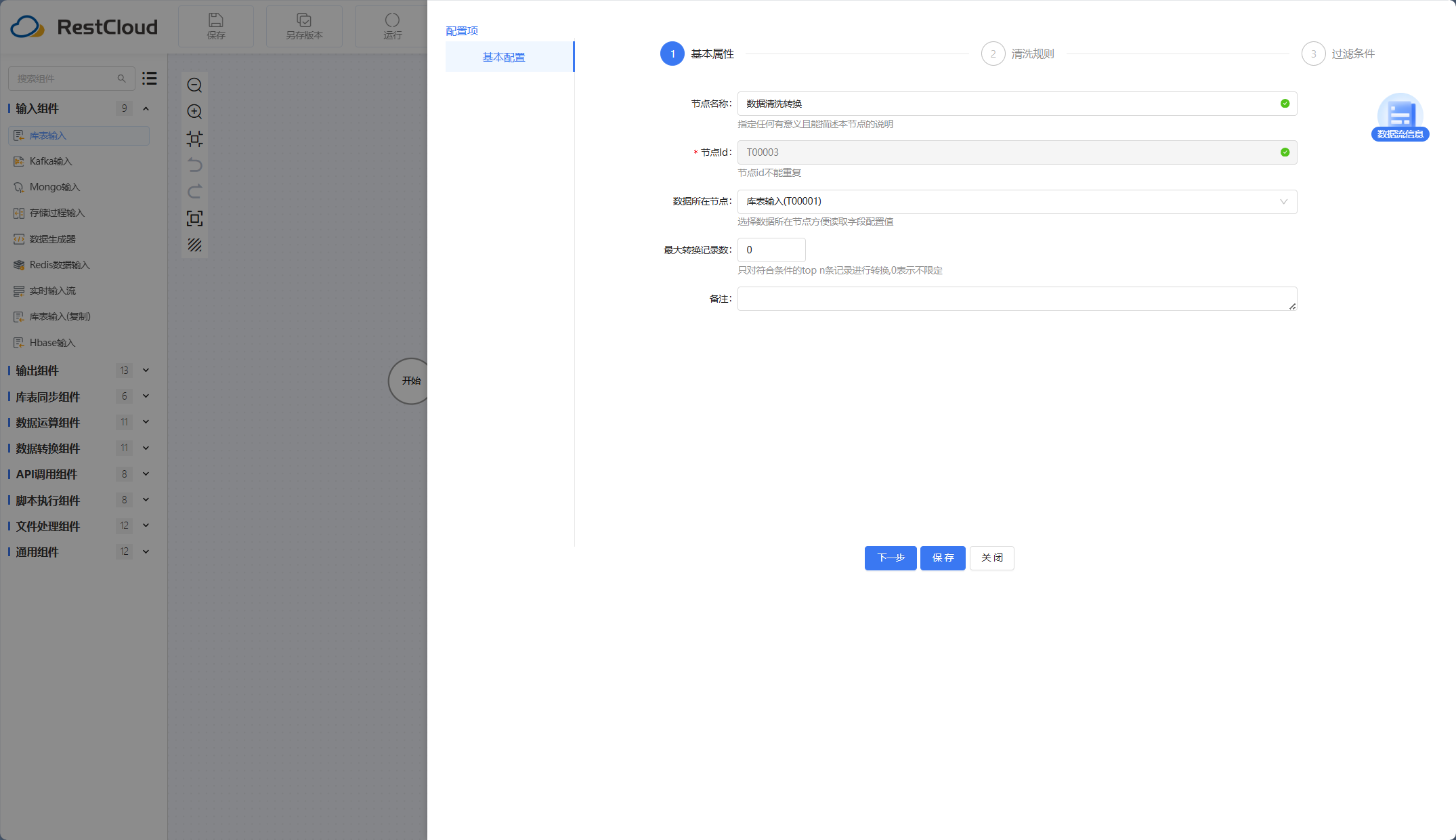
数据清洗转换组件:
该组件在这个位置是指代了ETL中转换的操作,实际场景如果有更复杂的数据处理需求可以手动设计流程,手动配置数据需要转换的清洗规则以及过滤条件。
Hbase输出组件:
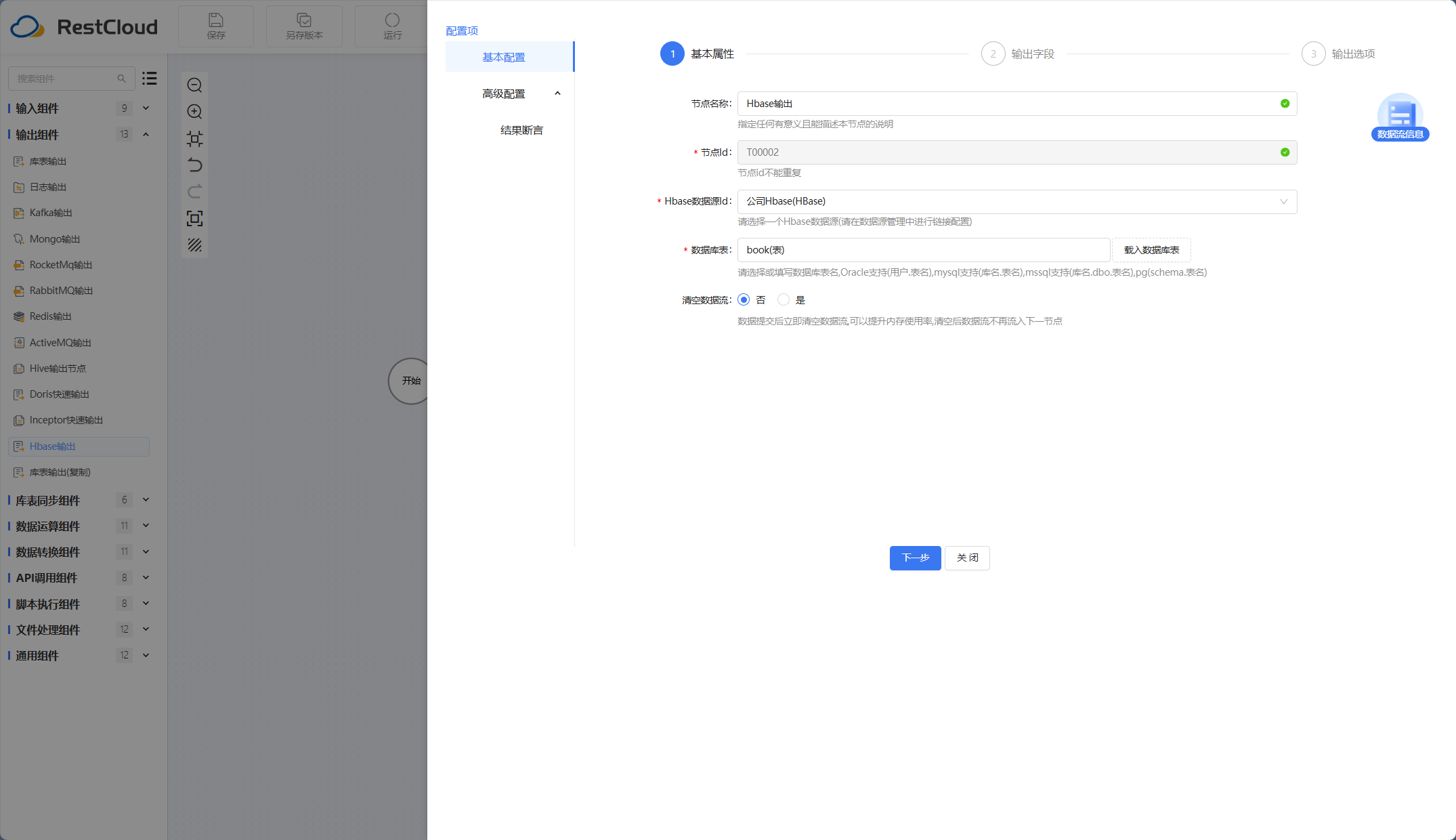
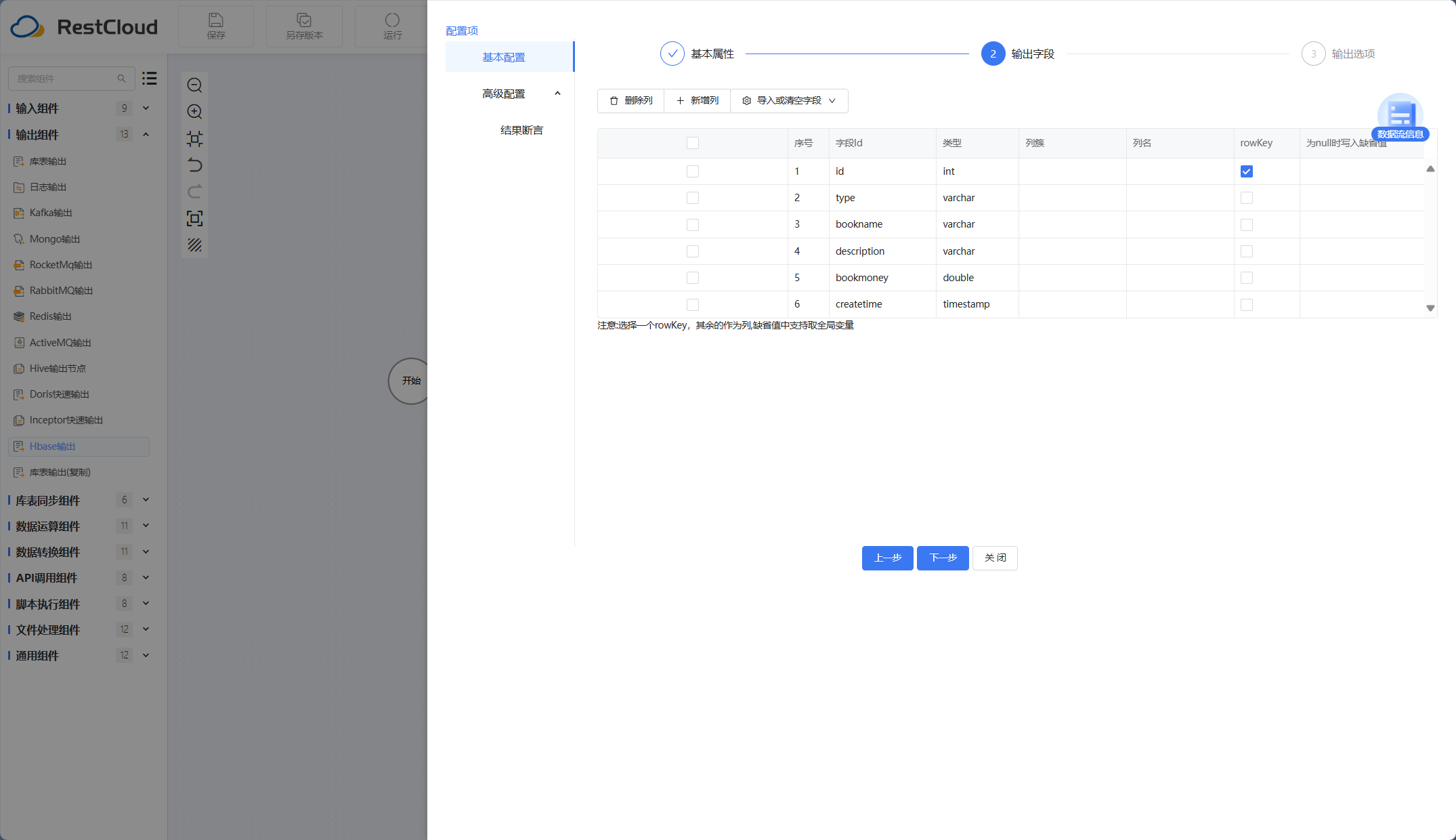
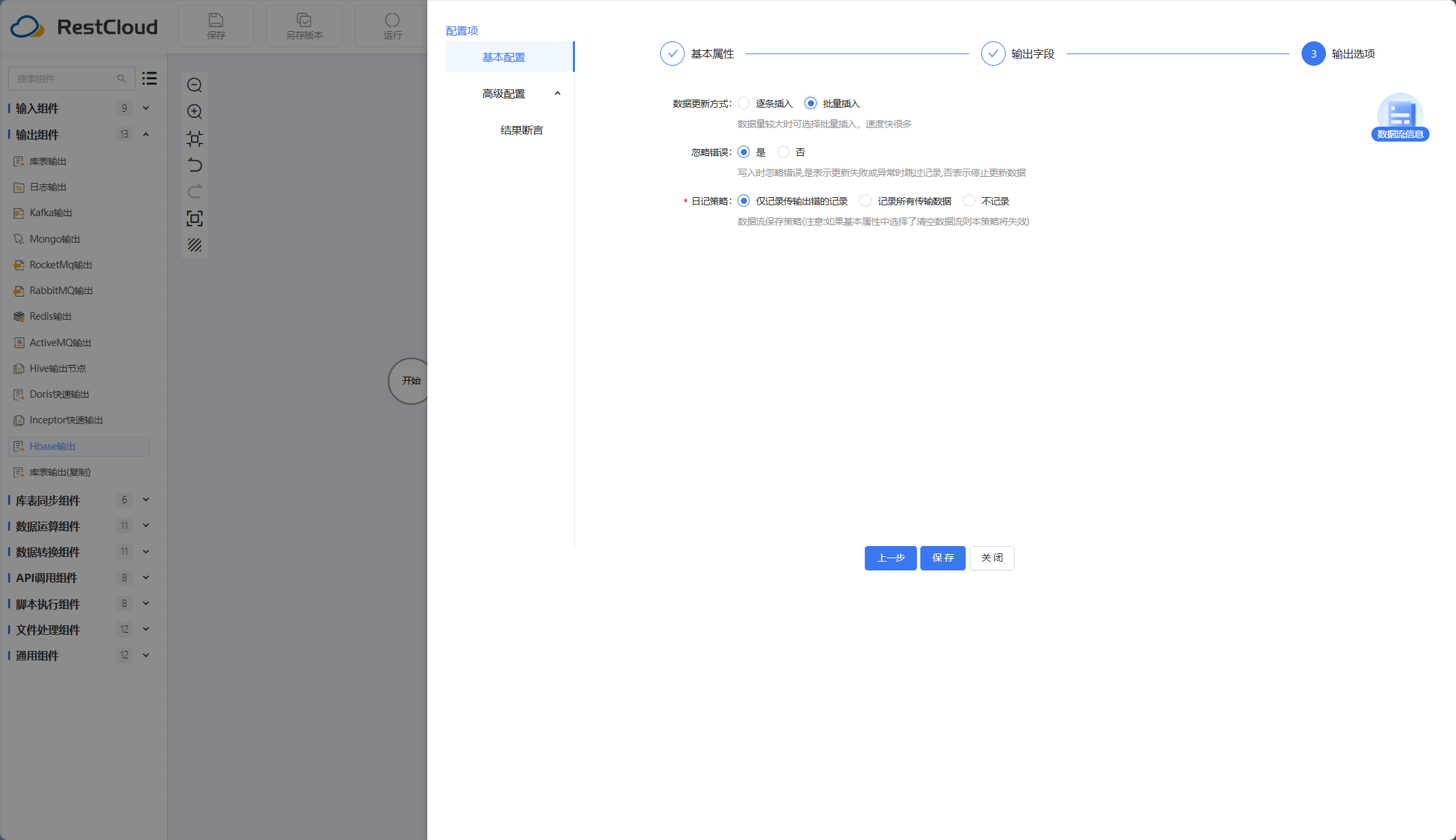
执行流程。
结果:
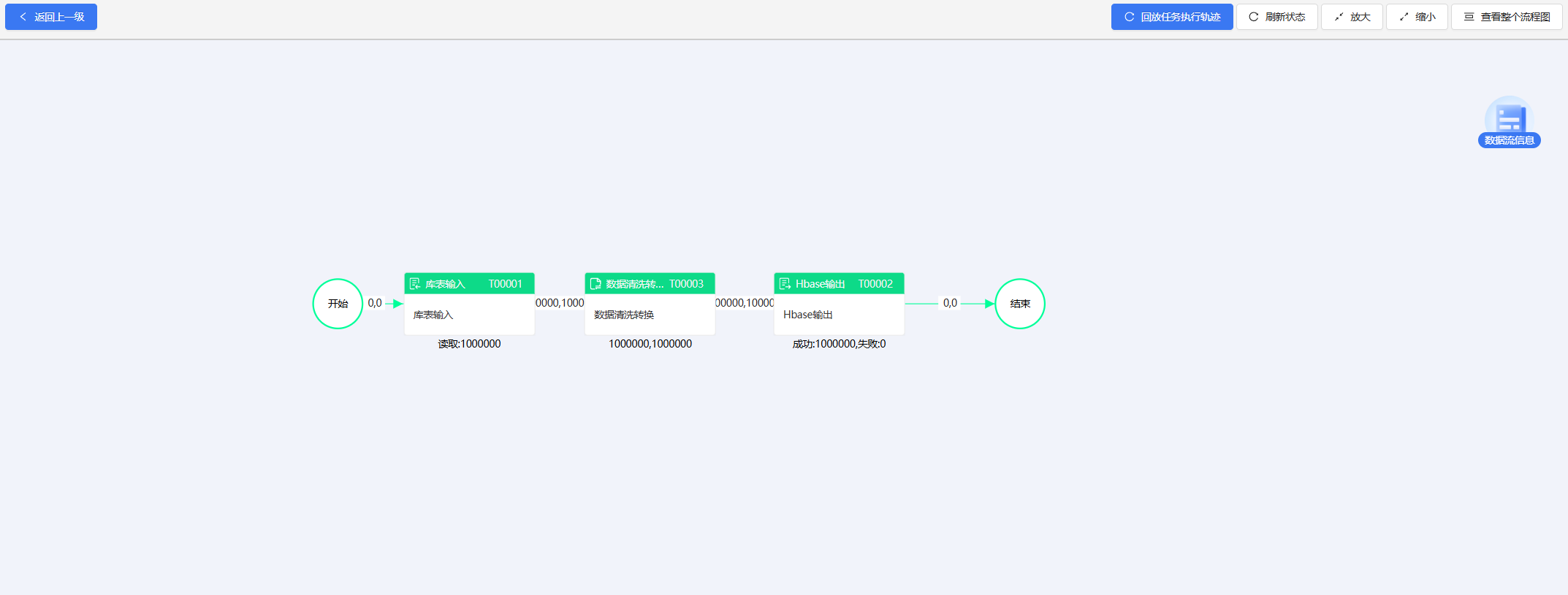
以上便是使用ETLCloud工具对数据进行ETL并入库Hbase的过程。可能实际的需求场景可能会更加复杂,但是不用担心,ETLCloud还提供了非常丰富的数据转换、运算组件来应对数据融合的各种情况,比如如果需要对多个数据源的数据进行合并后再进行分析处理,可以使用双流Join合并组件或者多流Union合并组件完成多个有连接关系或同结构数据源的数据合并。对数据进行提取分析,也可以使用字段名映射、字段值标注等等组件来处理数据知道数据符合目标结构。