推理加速papers
《A Survey on Efficient Inference for Large Language Models》2024-07
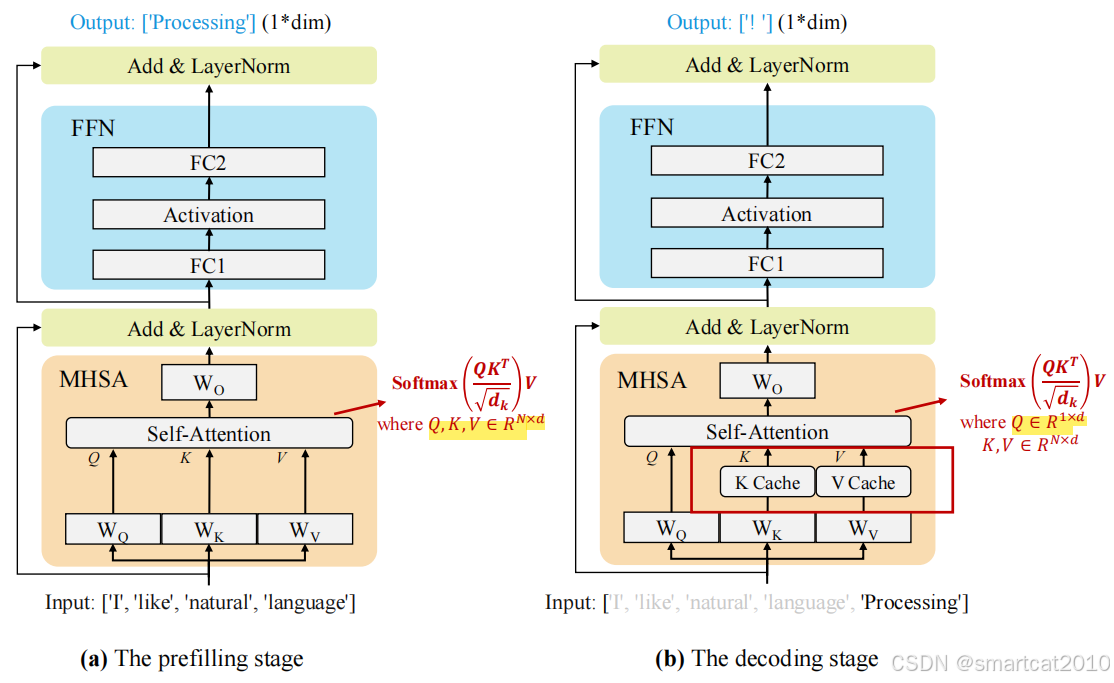
1. Q、K、V的计算,都是矩阵乘法;
2. prefilling阶段,每次计算,Q是N个向量一起;decoding阶段,每次计算,Q是1个向量计算;
3. 疑问:prefilling阶段,序列里靠前的tokens,能把包括其后面的tokens在内的所有tokens,都进行V的加权和吗?
4. 疑问:不知道
的作用是啥?
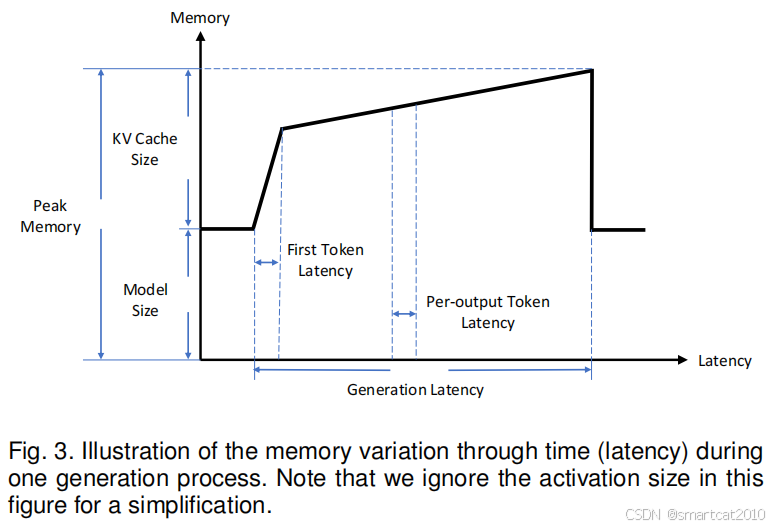
1. 计算prefilling stage期间,KV Cache剧烈上升,因为一次forward中,要记录下很多(input tokens个)tokens的KV;
2. decoding阶段,因为是一个一个token的生成,所以较慢,KV cache一次增长1个token的,所以增长慢;
3. 一个序列生成完之后,释放2个阶段生成的所有KV cache,显存又回到model size;
4. 因为没有backward,所以activation不需要保存,所以很小,忽略之;
5. 疑问:一开始的那段,可以理解为tokenizing和加载token-ids进显存吗?如果理解为prefilling计算,则每算完一层,KV cache都应该增加一些的;
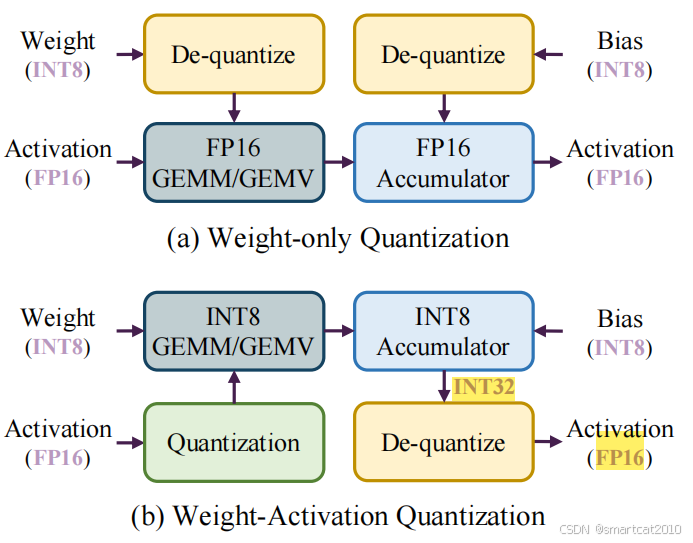
Post-Training Quantization
1. prefilling阶段,计算是矩阵*矩阵(GEMM),时间复杂度O(N^3);加载矩阵时间复杂度O(N^2); 因此是计算密集型;
2. wegith-activation量化,是INT8*INT8的计算,在计算上可以加速;因此适合prefilling阶段;
3. decoding阶段,计算是向量*矩阵(GEMV),时间复杂度O(N^2);加载矩阵时间复杂度O(N^2);因此是访存密集型;
4. weight-only量化,是FP16*FP16的计算,重点不是计算加速,而是读显存加速;因此适合decoding阶段;
1. Weight-only的,一直都用FP16在计算;仅仅是每步把Weight拿出来从INT8反量化为FP16;起到节省模型存放的显存,和加快Weight显存读取的作用;
2. Weight-Activation的,计算是用INT8;除了以上2个好处,新增了加快计算这个好处;每次,INT8的结果INT32,都要反量化为FP16,做一些中间操作(ReLU,LayerNorm等),再交给下一层进行量化为INT8;
Weight-only量化的实验:
1. 将decoding阶段加速约2倍;原因:将Weight矩阵从显存读到计算单元的数据量,减少到一半;
2. prefilling阶段,没有加速,反而略微变慢;原因:该阶段瓶颈是计算,不是访存;反量化反而是增加了一些延迟;
3. decoding阶段,batch-size越大,加速效果约差;原因:计算/访存中,计算的耗时占比增大了,导致访存的加速对整体的贡献比例减少;input context,也是类似现象和原因(计算量在Q、K、V那里增大了,但QKV并没有做量化,因此QKV的访存时间没变,W的访存的那些加速,在整体中的贡献减少了)
4. model越大,加速约大;原因:模型越大,W越大,访存加速效果明显;(疑问:计算量不是也等比增加吗?)
