Java避坑案例 - 线程池错误的混用引发的性能故障分析
文章目录
- 问题现象
- 问题分析
- 问题修复
- 线程池的混用策略
- 任务类型与线程池配置
- 最佳实践

问题现象
代码使用了线程池异步处理一些内存中的数据,但通过监控发现处理得非常慢,整个处理过程都是内存中的计算不涉及 IO 操作,也需要数秒的处理时间,应用程序 CPU 占用也不是特别高,有点不可思议
问题分析
经排查发现,业务代码使用的线程池,除了自身业务使用,同时还被一个后台的文件批处理任务用到了。
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 2,1, TimeUnit.HOURS,new ArrayBlockingQueue<>(100),new ThreadFactoryBuilder().setNameFormat("batchfileprocess-threadpool-%d").build(),new ThreadPoolExecutor.CallerRunsPolicy());public int handleFile() throws ExecutionException, InterruptedException {return threadPool.submit(calcTask()).get();}接下来我们模拟一下文件批处理的代码,在程序启动后通过一个线程开启死循环逻辑,不断向线程池提交任务,任务的逻辑是向一个文件中写入大量的数据
/*** 在Bean初始化完成后执行的方法* 此方法初始化线程池并启动一个新线程来执行特定任务*/
@PostConstruct
public void init() {// 打印线程池的初始状态和统计信息printStats(threadPool);// 创建并启动一个新的线程来执行批处理任务new Thread(() -> {// 生成一个由'a'字符组成的100万字符长的字符串作为负载String payload = IntStream.rangeClosed(1, 1_000_000).mapToObj(__ -> "a").collect(Collectors.joining(""));// 无限循环执行任务while (true) {// 使用线程池执行写入操作threadPool.execute(() -> {try {// 写入当前时间戳和负载到文件中Files.write(Paths.get("artisan.txt"), Collections.singletonList(LocalTime.now().toString() + ":" + payload), UTF_8, CREATE, TRUNCATE_EXISTING);} catch (IOException e) {// 打印异常信息e.printStackTrace();}// 记录日志,表示批处理任务完成log.info("batch file processing done");});}}).start();
}/*** 定期打印线程池的运行统计信息* 此方法内部创建了一个新的单线程调度器,用于定期执行打印线程池统计信息的任务* 它提供了线程池大小、活动线程数、已完成任务数和队列中任务数的信息* 这些信息有助于监控线程池的性能和工作负载* * @param threadPool 线程池对象,其统计信息将被打印*/
private void printStats(ThreadPoolExecutor threadPool) {Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {// 打印分割线,用于区分不同的统计时间点log.info("=========================");// 打印线程池当前的线程数量log.info("Pool Size: {}", threadPool.getPoolSize());// 打印当前活动线程的数量log.info("Active Threads: {}", threadPool.getActiveCount());// 打印已完成任务的总数log.info("Number of Tasks Completed: {}", threadPool.getCompletedTaskCount());// 打印队列中等待执行的任务数量log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());// 再次打印分割线,结束本次统计信息的打印log.info("=========================");}, 0, 1, TimeUnit.SECONDS);
}流程如下:
通过 printStats 方法打印出的日志可以看到,这个线程池中的 2 个线程任务是相当重的。

-
线程池的 2 个线程始终处于活跃状态,队列也基本处于打满状态
-
因为开启了CallerRunsPolicy 拒绝处理策略,所以当线程满载队列也满的情况下,任务会在提交任务的线程,或者说调用 execute 方法的线程执行,也就是说不能认为提交到线程池的任务就一定是异步处理的。如果使用了 CallerRunsPolicy 策略,那么有可能异步任务变为同步执行。从日志的第四行也可以看到这点。这也是这个拒绝策略比较特别的原因
试想一下: 业务代码复用这样的线程池来做内存计算,会怎样???
写一段代码测试下,向线程池提交一个简单的任务,这个任务只是休眠 10 毫秒没有其他逻辑
/*** 创建一个计算任务,该任务在执行时会暂停一段时间然后返回固定的结果* * @return Callable<Integer> 一个计算任务,当运行时会暂停10毫秒,然后返回整数1*/
private Callable<Integer> calcTask() {return () -> {// 暂停10毫秒,模拟耗时操作或等待资源TimeUnit.MILLISECONDS.sleep(10);// 返回固定的结果1,表示任务完成return 1;};
}/*** 错误的异步任务处理示例* * 此方法展示了一个错误的异步任务处理方式,通过提交一个计算任务到线程池并立即获取结果的方式* 这种做法未能正确处理异步任务,因为它会导致线程池的线程阻塞,直到任务完成,从而降低了系统的整体性能和响应速度* * @return 计算任务的结果* @throws ExecutionException 如果计算任务执行失败* @throws InterruptedException 如果线程被中断*/
@GetMapping("wrong")
public int wrong() throws ExecutionException, InterruptedException {return threadPool.submit(calcTask()).get();
}使用 wrk 工具对这个接口进行一个简单的压测,可以看到 TPS 为 75,性能的确非常差
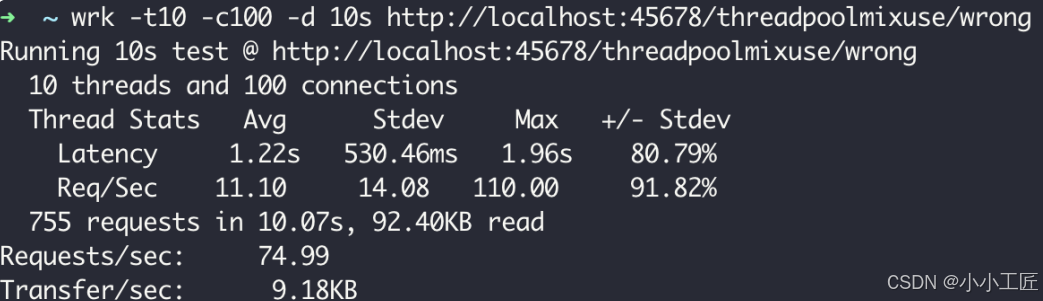
细想一下,问题其实没有这么简单。因为 原来执行 IO 任务的线程池使用的是CallerRunsPolicy 策略,所以直接使用这个线程池进行异步计算的话,当线程池饱和的时候,计算任务会在执行 Web 请求的 Tomcat 线程执行,这时就会进一步影响到其他同步处理的线程,甚至造成整个应用程序崩溃。
问题修复
解决方案很简单,使用独立的线程池来做这样的“计算任务”即可。计算任务打了双引号,是因为我们的模拟代码执行的是休眠操作,并不属于 CPU 绑定的操作,更类似 IO 绑定的操作,如果线程池线程数设置太小会限制吞吐能力
/*** 创建一个固定大小的线程池用于异步计算任务* * 线程池的配置参数说明:* - 核心线程数和最大线程数都设置为200,意味着线程池只会创建200个线程来执行任务* - 线程空闲时间设为1小时,即线程在空闲1小时后将被终止* - 使用ArrayBlockingQueue作为任务队列,队列大小设为1000,这意味着在队列满的情况下,* 新提交的任务将等待直到队列中有空位* - 通过ThreadFactoryBuilder设置线程名称格式,以便于追踪和管理线程*/
private static ThreadPoolExecutor asyncCalcThreadPool = new ThreadPoolExecutor(200, 200,1, TimeUnit.HOURS,new ArrayBlockingQueue<>(1000),new ThreadFactoryBuilder().setNameFormat("asynccalc-threadpool-%d").build());/*** 使用异步方式计算并返回结果* 本方法通过提交一个计算任务到异步计算线程池,并等待任务完成后的结果* 如果任务抛出异常,将会被传播到调用者* * @return 计算结果* @throws ExecutionException 如果计算任务执行失败或被取消* @throws InterruptedException 如果等待结果时线程被中断*/
@GetMapping("right")
public int right() throws ExecutionException, InterruptedException {// 提交一个异步计算任务到线程池并获取Future对象,用于获取计算结果return asyncCalcThreadPool.submit(calcTask()).get();
}使用单独的线程池改造代码后再来测试一下性能,TPS 提高到了 1727
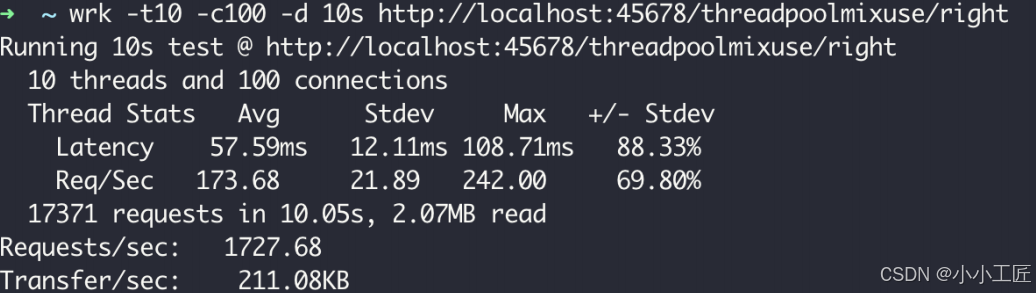
在这个案例中,使用了一个只包含两个核心线程的线程池,同时被 I/O 密集型和 CPU 密集型任务共享,导致了性能瓶颈。由于采用了 CallerRunsPolicy 拒绝策略,当线程池达到饱和时,任务被回退到调用线程执行,进而影响了整个应用的性能。
这种配置的影响是显而易见的:异步任务的执行可能变成了同步执行,进一步降低了应用的响应能力。
线程池的混用策略
线程池的设计确实是为了复用资源,但这并不意味着所有任务都应共享同一个线程池。不同类型的任务(如 I/O 密集型与 CPU 密集型)对线程池的需求差异显著,因此需要谨慎选择线程池的配置和混用策略。
任务类型与线程池配置
- I/O 密集型任务:如网络请求或文件操作,通常需要更多的线程来处理潜在的阻塞,因此可配置较高的核心线程数,且队列大小适中。
- CPU 密集型任务:计算密集型任务应该限制线程数量,通常设置为 CPU 核数或 CPU 核数的两倍,以减少线程切换的开销。这类任务可能需要更大的队列来缓冲任务。
最佳实践
- 任务隔离:为不同类型的任务创建独立的线程池,避免混用。
- 合理配置:根据任务的特性(I/O 密集或 CPU 密集)合理设置线程池的核心参数。
- 监控与调优:定期监控线程池的性能指标,根据实际需求进行调整。
