使用yield压平嵌套字典有多简单?

我们经常遇到各种字典套字典的数据,例如:
nest_dict = {'a': 1,'b': {'c': 2,'d': 3,'e': {'f': 4}},'g': {'h': 5},'i': 6,'j': {'k': {'l': {'m': 8}}}
}
有没有什么简单的办法,把它压扁,变成:
{'a': 1,'b_c': 2,'b_d': 3,'b_e_f': 4,'g_h': 5,'i': 6,'j_k_l_m': 8
}
你肯定想到了使用递归来解决这个问题,那么你可以试一试,看看你的递归函数有多少行代码。
今天,我们使用yield关键字来实现这个需求,在不炫技的情况下,只需要8行代码。在炫技的情况下,只需要3行代码。
要快速地把这个嵌套字典压扁,我们需要从下网上来处理字段。例如对于b->e->f->4这条路径,我们首先把最里面的{'f': 4}转换为一个元组('f', 4)。然后,把这个元组向上抛出,于是得到了元组('e', ('f', 4))。我们把 e拼接到f的前面,变为:('e_f', 4),继续往上抛出,得到('b', ('e_f', 4))。再把b拼接到e_f上面,得到('b_e_f', 4)。完成一条线路的组装。
这个逻辑如果使用yield关键字来实现,就是:
def flat(x):for key, value in x.items():if isinstance(value, dict):for k, v in flat(value):k = f'{key}_{k}'yield (k, v)else:yield (key, value)
运行结果如下图
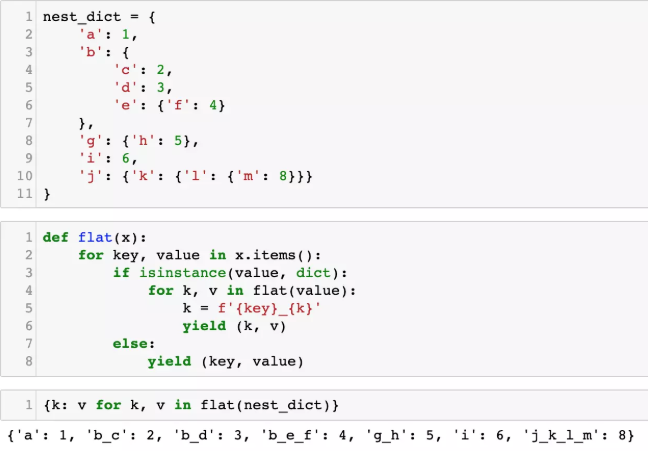
通过使用 yield关键字,字典的key会像是在流水线上一样,一层一层从内向外进行组装,从而形成完整的路径。