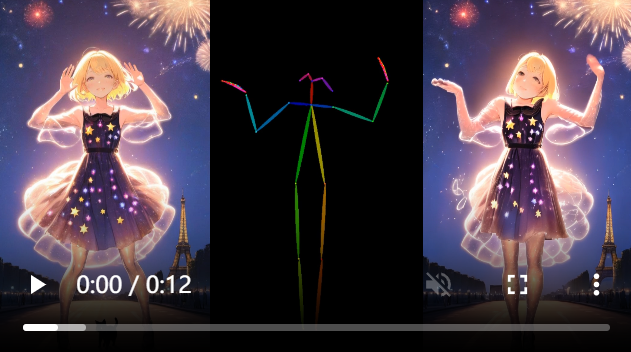
MusePose模型部署指南
一、模型介绍
MusePose是一个基于扩散和姿势引导的虚拟人视频生成框架。
主要贡献可以概括如下:
- 发布的模型能够根据给定的姿势序列,生成参考图中人物的舞蹈视频,生成的结果质量超越了同一主题中几乎所有当前开源的模型。
- 发布该
pose align算法,以便用户可以将任意舞蹈视频与任意参考图像对齐,这显著提高了推理性能并增强了模型的可用性。 - 修复了几个重要的错误,并在 Moore-AnimateAnyone的代码基础上做了一些改进。
二、部署流程
1. 环境要求
- Python 3.10 或更高版本
- 推荐:CUDA 11.7 或更高版本
2. 克隆并安装依赖项
git clone https://github.com/TMElyralab/MusePose.git
pip install -r requirements.txt
3. 下载mim软件包
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
4.下载权重
git lfs install
git clone https://www.modelscope.cn/jackle/ComfyUI-MusePose-models.git

pretrained_weights 最后,这些权重应按如下方式组织:
./pretrained_weights/
|-- MusePose
| |-- denoising_unet.pth
| |-- motion_module.pth
| |-- pose_guider.pth
| └── reference_unet.pth
|-- dwpose
| |-- dw-ll_ucoco_384.pth
| └── yolox_l_8x8_300e_coco.pth
|-- sd-image-variations-diffusers
| └── unet
| |-- config.json
| └── diffusion_pytorch_model.bin
|-- image_encoder
| |-- config.json
| └── pytorch_model.bin
└── sd-vae-ft-mse|-- config.json└── diffusion_pytorch_model.bin
三、推理
1. 准备
在文件夹中准备参考图片和舞蹈视频 ./assets,并按照示例进行组织:
./assets/
|-- images
| └── ref.png
└── videos└── dance.mp4
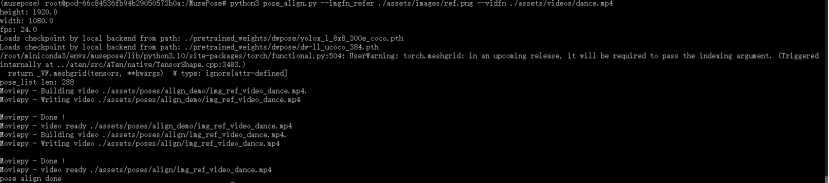
2. 姿势对齐
获取参考图的对齐 dwpose:
python pose_align.py --imgfn_refer ./assets/images/ref.png --vidfn ./assets/videos/dance.mp4
此后,您可以在其中看到姿势对齐结果 ./assets/poses,其中 ./assets/poses/align/img_ref_video_dance.mp4 是对齐的 dwpose,而 ./assets/poses/align_demo/img_ref_video_dance.mp4 用于调试。
3. 推断 MusePose
将参考图的路径和对齐的 dwpose 添加到测试配置文件中,./configs/test_stage_2.yaml 例如:
test_cases:"./assets/images/ref.png":- "./assets/poses/align/img_ref_video_dance.mp4"
然后,只需运行
python test_stage_2.py --config ./configs/test_stage_2.yaml
./configs/test_stage_2.yaml 是推理配置文件的路径。
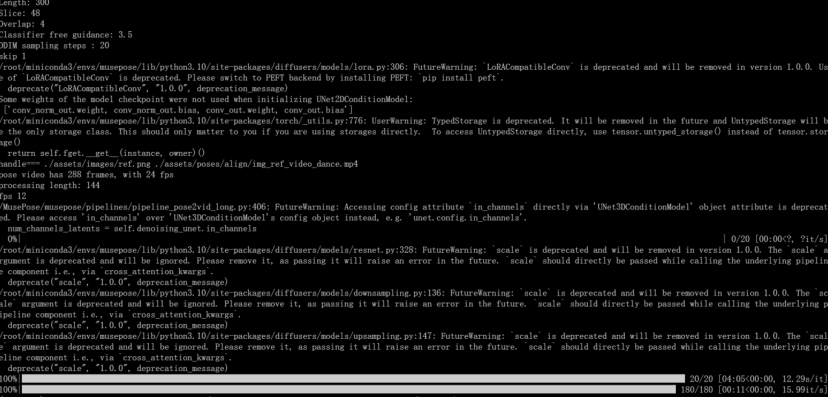
最后,你可以在 ./output/文件夹下查看
4. 降低 VRAM 成本
如果要降低 VRAM 成本,可以设置推理的宽度和高度。例如,
python test_stage_2.py --config ./configs/test_stage_2.yaml -W 512 -H 512
它将首先生成 512 x 512 的视频,然后将其调整回姿势视频的原始大小。
目前在 512 x 512 x 48 上运行需要 16GB VRAM,在 768 x 768 x 48 上运行需要 28GB VRAM。但需要注意的是,推理分辨率会影响最终结果(尤其是人脸区域)。
5. 面部美容
如果要增强脸部区域以获得更好的脸部一致性,可以使用FaceFusion。您可以使用该 face-swap 功能将参考图中的脸部交换到生成的视频中。
四、界面演示