计算机网络基础 - 传输层(1)
计算机网络基础
- 传输层
- 概述
- 多路复用与解复用
- 概述
- 解复用的工作原理
- 无连接多路解复用
- 面向连接的多路复用
- 无连接运输:UDP
- 概述
- UDP 主要应用
- UDP 报文段结构
- 可靠数据传输的原理
- 概述
- 构建可靠数据传输协议
- 经完全可靠信道的可靠数据传输:rdt1.0
- 经具有比特差错信道的可靠数据传输:rdt2.x
- 经具有比特差错的丢包信道的可靠数据传输:rdt3.0
大家好呀!我是小笙,本章我主要分享计算机网络基础 - 传输层(1)学习总结,希望内容对你有所帮助!!
传输层
概述
为运行在不同主机上的应用进程提供逻辑通信(有两个传输层协议可供应用选择:TCP/UDP)
传输协议运行在端系统
- 发送方:将应用层的报文分成报文段,然后传递给网络层
- 接收方:将报文段重组成报文,然后传递给应用层
运输层和网络层的关系
-
网络层服务:主机间的逻辑通信
-
传输层服务:进程间的逻辑通信
- 依赖于网络层的服务(延时、带宽)
- 并对网络层的服务进行增强(数据丢失、顺序混乱、加密)
注意:有些服务是可以加强的:可靠性、安全性;但有些服务是不可以被加强的:带宽、延迟
传输层协议
可靠的、保序的传输: TCP
- 多路复用、解复用
- 拥塞控制
- 流量控制
- 建立连接
不可靠、不保序的传输:UDP
- 多路复用、解复用
- 没有为尽力而为的 IP 服务添加更多的其它额外服务
都不提供的服务: 延时保证 、带宽保证
多路复用与解复用
概述
在发送方主机多路复用
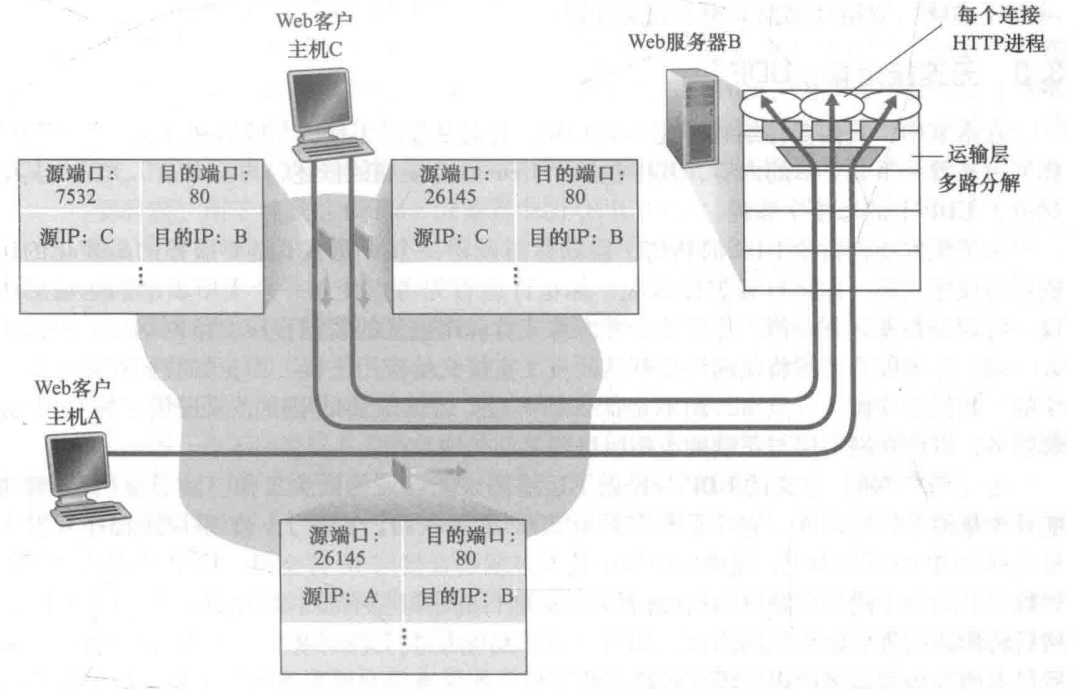
从多个套接字接收来自多个进程的报文,根据套接字对应的 IP 地址和端口号等信息对报文段用头部加以封装
注意: 该头部信息用于以后的解复用
在接收方主机多路解复用
根据报文段的头部信息中的 IP 地址和端口号将接收到的报文段发给正确的套接字(和对应的应用进程)

解复用的工作原理
作用:TCP或者UDP实体采用哪些信息,将报文段的数据部分交给正确的socket,从而交给正确的进程
当主机收到 IP 数据报,主机联合使用IP地址和端口号将报文段发送给合适的套接字
- 每个数据报有源 IP 地址和目标 IP 地址
- 每个报文段有一个源端口号和目标端口号
- 每个数据报承载一个传输层报文段

无连接多路解复用
创建套接字
服务器端
serverSocket = socket(PF_INET,SOCK_DGRAM,0);
bind(serverSocket,&sad,sizeof(sad)); // (serverSocket 和 sad 指定的端口号捆绑)
客户端
ClientSocket=socket(PF_INET,SOCK_DGRAM,0);
// 不需要 bind 指定的端口号(客户端使用什么端口号无所谓,客户端主动找服务器)
在接收端,UDP套接字用二元组标识 (目标IP地址、目标端口号)
当主机收到 UDP 报文段
- 检查报文段的目标端口号
- 用该端口号将报文段定位给套接字
注意:如果两个不同源 IP 地址/源端口号的数据报,但是有相同的目标 IP 地址和端口号,则被定位到相同的套接字

面向连接的多路复用
TCP套接字:四元组本地标识(源 IP地址、源端口号、目的 IP地址、目的端口号)
- 解复用:接收主机用这四个值来将数据报定位到套接字
- 服务器能够在一个 TCP 端口上同时支持多个TCP套接字
- Web服务器对每个连接客户端有不同的套接字(非持久对每个请求有不同的套接字)
无连接运输:UDP
概述
使用UDP时,在发送报文段之前,发送方和接收方的运输层实体之间没有握手。正因为如此,UDP被称为是无连接的(“尽力而为”的服务,报文段可能丢失、送到应用进程的报文段乱序)
为什么许多应用适用于 UDP?
- 实时应用通常要求最小的发送速率,不希望过分地延迟报文段的传送,且能容忍一些数据丢失,TCP 服务模型并不是特别适合这些应用的需要
- 无须连接建立,这可能是 DNS 运行在 UDP 之上而不是运行在TCP之上的主要原因(如果运行在 TCP 上,则 DNS 会慢得多)
- 无连接状态,某些专门用于某种特定应用的服务器当应用程序运行在 UDP 之上而不是运行在 TCP 上时,一般都能支持更多的活跃客户
- 分组首部开销小。每个 TCP 报文段都有20字节的首部开销,而 UDP 仅有8字节的开销
UDP 主要应用
- 流媒体(丢失不敏感,速率敏感、应用可控制传输速率)
- DNS
- SNMP
UDP 报文段结构
- 通过端口号可以使目的主机将应用数据交给运行在目的端系统中的相应进程
- 长度字段指示了在UDP报文段中的字节数(首部加数据)
- 接收方使用检验和来检查在该报文段中是否出现了差错

校验和
目标: 检验和用于确定当UDP报文段从源到达目的地移动时,其中的比特是否发生了改变
发送方的UDP:对报文段中的所有 16 比特字的和进行反码运算,求和时遇到的任何溢出都被回卷。得到的结果被放在UDP报文段中的检验和字段
// 假定我们有下面3个16比特的字
0110011001100000
0101010101010101
1000111100001100// 求和得: 0100101011000010 (求和时遇到的任何溢出都被回卷)
// 反码运算就是将所有的0换成1,所有的1转换成0。因此反码运算结果是1011010100111101
接收方:计算接收到的报文段的校验和检查计算出的校验和与校验和字段的内容是否相等
- 不相等 - 检测到差错
- 相等 - 没有检测到差错,但也许还是有差错 (残存错误)
说明:虽然UDP提供差错检测,但它对差错恢复无能为力
可靠数据传输的原理
概述
实现这种服务抽象是可靠数据传输协议的责任。由于可靠数据传输协议的下层协议也许是不可靠的,因此这是一项困难的任务。(例如,TCP是在不可靠的(IP)端到端网络层之上实现的可靠数据传输协议)
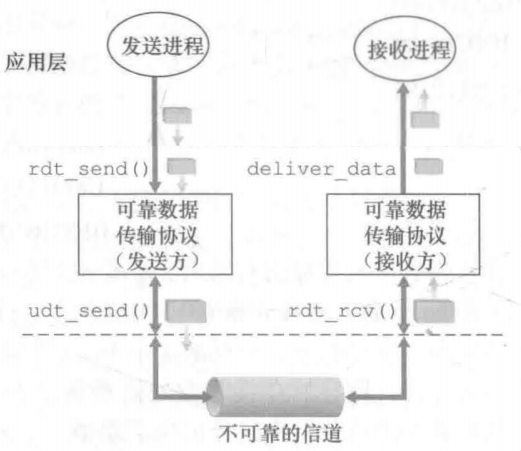
构建可靠数据传输协议
经完全可靠信道的可靠数据传输:rdt1.0
底层信道是完全可靠的,称该协议为 rdt1.0 即发送与接收只做传输操作
- 没有比特出错
- 没有分组丢失
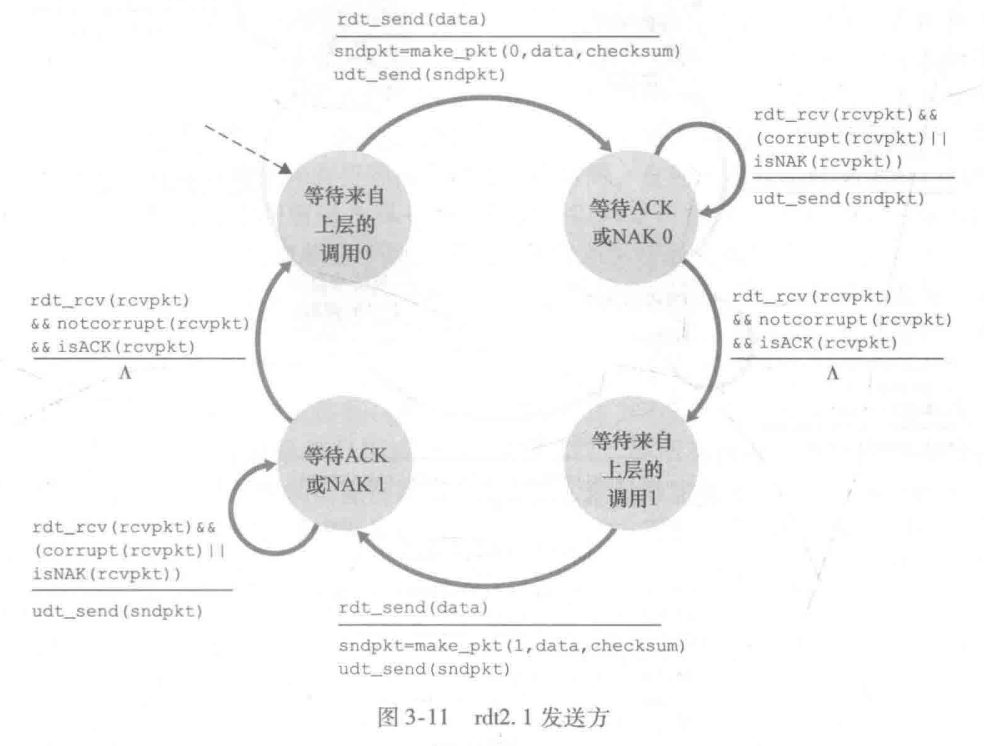
有限状态机是一种数学模型,用于表示和控制系统的状态变化,如下图发送端和接收端的状态在发送/接收到分组的时候发生变化
- FSM 的初始状态用虚线表示
- 引起变迁的事件显示在表示变迁的横线上方
- 事件发生时所采取的动作显示在横线下方


注意:如果对一个事件没有动作或没有就事件发生而采取了一个动作,我们将在横线上方或下方使用符号 ∧,以分别明确地表示缺少动作或事件
经具有比特差错信道的可靠数据传输:rdt2.x
底层信道更为实际的模型是分组中的比特可能受损的模型。在分组的传输、传播或缓存的过程中,这种比特差错通常会出现在网络的物理部件中
控制报文使得接收方可以让发送方知道哪些内容被正确接收,哪些内容接收有误并因此需要重复。在计算机网络环境中,基于这样重传机制的可靠数据传输协议称为自动重传请求(ARQ)协议
ARQ 协议中还需要另外三种协议功能来处理存在比特差错的情况
- 差错检测
- 接收方反馈(ACK 肯定确认,NAK 否定确认)
- 重传
rdt2.0
数据传输过程
- 发送端协议正等待来自上层传下来的数据
- 当 rdt_send(data) 事件出现时,发送方将产生一个包含待发送数据的分组,带有检验和,然后经由 udt_send(sndpkt) 操作发送该分组
- 发送方协议等待来自接收方的 ACK 或 NAK 分组
- 如果收到一个 ACK 分组,则发送方知道最近发送的分组已被正确接收,因此协议返回到等待来自上层的数据的状态
- 如果收到一个 NAK 分组,该协议重传上一个分组并等待接收方为响应重传分组而回送的 ACK 和 NAK
注意:当发送方处于等待 ACK 或 NAK 的状态时,它不能从上层获得更多的数据,这就是说 rdt send() 事件不可能出现;仅当接收到 ACK 并离开该状态时才能发生这样的事件。因此发送方将不会发送块新数据,除非发送方确信接收方已正确接收当前分组。由于这种行为,这样的协议被称为停等协议


但是存在很多问题(概括的来说就是分组丢失或者乱码)
- 发送方发送的分组丢失,接收方并没有接收到分组
- 接收方接收到的分组受损(乱码)
- 接收方发送了 ACK 或 NAK 分组,但是发送方没有接收到分组
- 发送方接收的 ACK 或 NAK 分组受损(乱码)
注意:丢失问题主要在 rdt3.0 解决,乱码问题主要在 rdt2.x 解决
升级版:rdt2.1
接收方发送的 ACK 或 NAK 分组受损(乱码),接收方可以通过重传之前的分组(冗余分组)的形式,但是接收方无法知道接收到的分组是新的还是一次重传!
解决方法:在数据分组中添加新的字段,让发送方对其数据分组编号(即将发送数据分组的序号),接收方只需要检查序号即可确定收分组是否是一次重传(如果发送方每次发送一个分组的话,就可以通过 1bit 来表示序号,也就是 1、0)

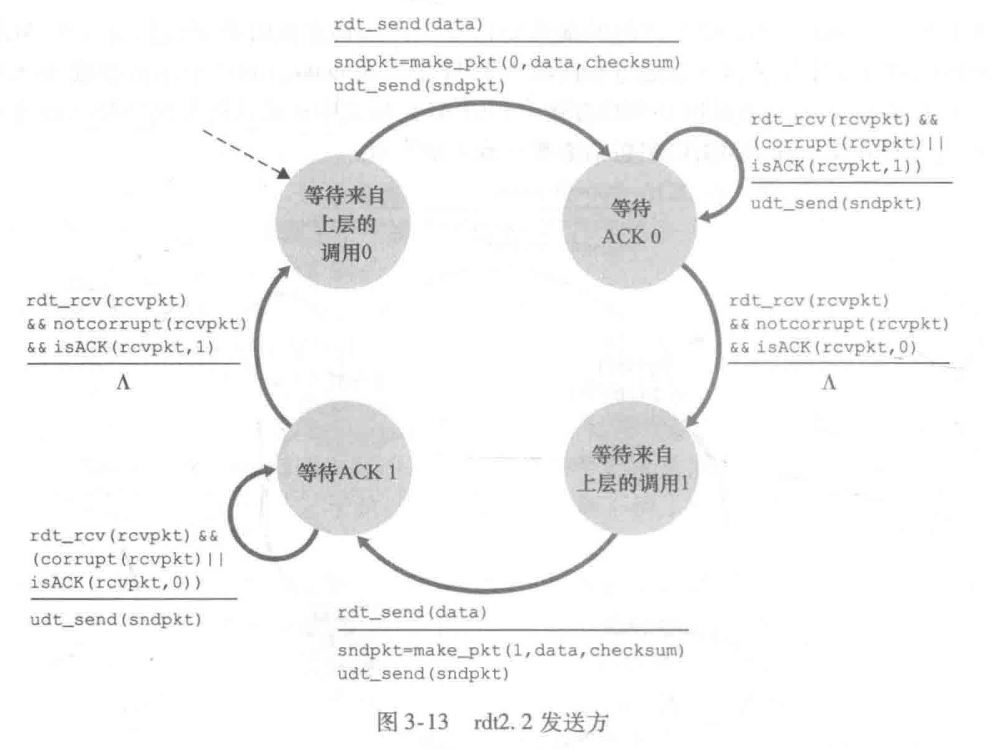
无NAK的可靠数据传输协议:rdt2.2
前提条件
当接收方每次接收一个分组的话(就可以通过 1bit 来表示序号,也就是 1、0),发送一个是对上次正确接收的分组的 ACK,来表示本次接收到分租有误(即ACK1 表示 NAK0,ACK0 表示 NAK1)

经具有比特差错的丢包信道的可靠数据传输:rdt3.0
协议现在必须处理另外两个关注的问题:怎样检测丢包以及发生丢包后该做些什么
超时重传
从发送方的观点来看,发送方不知道是一个发送的数据分组丢失,还是一个ACK丢失或者只是该分组或ACK过度延时。在所有这些情况下,动作是同样的:重传
为了实现基于时间的重传机制,需要一个倒计数定时器,在一个给定的时间量过期后,可中断发送方
- 每次发送一个分组(包括第一次分组和重传分组)时,便启动一个定时器
- 响应定时器中断(采取适当的动作)
- 终止定时器(比如接收到接收方的确认分组)
发送方需要等待多久才能确定已丢失了某些东西呢?
- 发送方与接收方之间的一个往返时延,可能会包括在中间路由器的缓冲时延
- 等待一个最坏情况的时延可能意味着要等待一段较长的时间,直到启动差错恢复为止。因此实践中采取的方法是发送方明智地选择一个时间值,以判定可能发生了丢包。如果在这个时间内没有收到ACK,则重传该分组
- 如果一个分组经历了一个特别大的时延,发送方可能会重传该分组,即使该数据分组及其ACK都没有丢失。这就在发送方到接收方的信道中引入了冗余数据分组的可能性。幸运的是,rdt2.x 协议已经有足够的功能(即序号)来处理冗余分组情况
以下分别是分组丢失、丢失 ACK 以及过早超时等情况
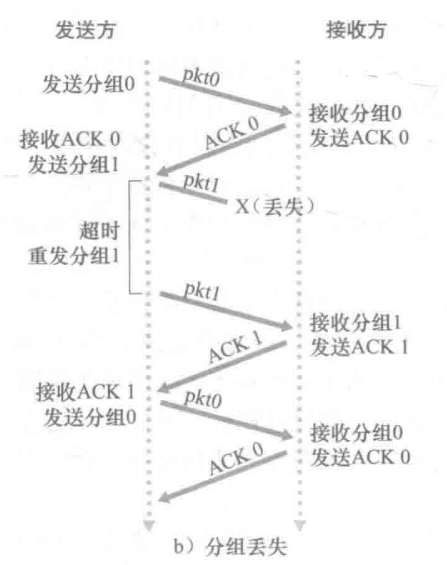


虽然 rdt3.0 协议下网络可以开始工作,但链路容量比较大的情况下,性能很差(一次只发送一个PDU 分组不能够充分利用链路的传输能力)网络协议限制了物理资源的利用!(本质就是 rdt3.0 协议 采用了停止等待的方式,发送的分组和接收的分组只能有一个,因此接下来引入流水线的方式提高性能)

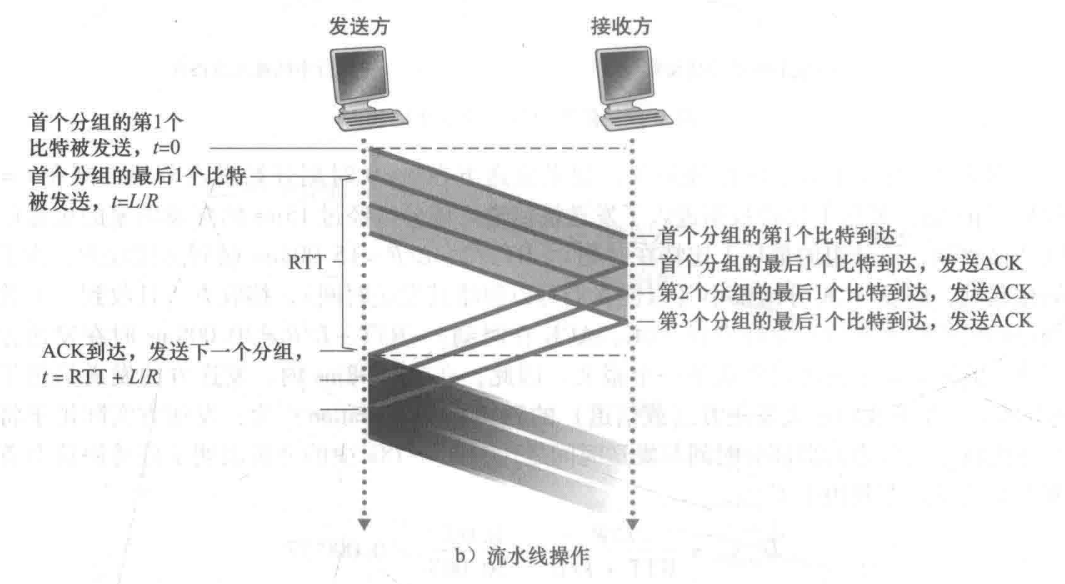
流水线形式的工作原理,且听下回分析!