PDF文件为什么不能编辑是?是啥原因导致的,有何解决方法
PDF文件格式广泛应用于工作中,但有时候我们可能遇到无法编辑PDF文件的情况。这可能导致工作效率降低,特别是在需要修改文件内容时显得尤为棘手。遇到PDF不能编辑时,可以看看是否以下3个原因导致的。

一、文件受保护
有些PDF文件可能被设置了密码或权限限制,以防止未经授权的编辑。这种保护措施确保了文件内容的安全性和完整性,但也给需要编辑的用户带来了不便。
解决方法:取消编辑保护
1、我们通过PDF编辑器打开PDF文件,然后点击菜单选项卡【保护】列表中的【删除安全设置】。
2、弹出对话框后,在空白栏里输入原本设置的密码,再点击【确定】即可移除保护。
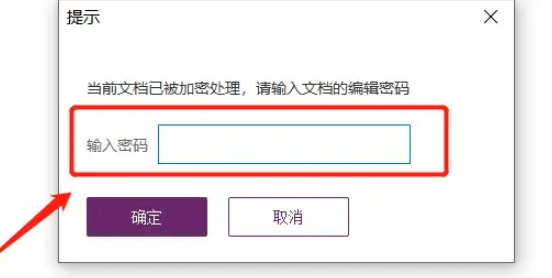
注意事项:
如果不小心忘记限制密码,就无法通过PDF编辑器来解除限制,这种情况,需要借助其他工具的帮助。
比如小编使用的PassFab for PDF工具,可以不用密码,直接移除PDF文件的限制保护。
在工具里选择【解除限制】模块,然后导入PDF文件,即可一键解除。

二、文本被转为图像
为了保持文档的原始格式和布局,有些PDF文件中的文本可能被转换为图像。这种情况下,用户无法直接编辑文本内容。
解决方法:转换文件格式
对于无法直接编辑的图片文件,用户可以尝试将其转换为其他可编辑的格式,如Word、Excel等。通过转换文件格式,用户可以在可编辑的环境中修改文件内容,然后再将其转换回PDF格式。
三、文件损坏或格式错误
在某些情况下,PDF文件可能由于损坏或格式错误而无法正常编辑。这可能是由于文件传输过程中的错误、存储介质问题或软件兼容性问题导致的。
解决方法:利用OCR技术:
如果PDF文件中的文本被转换为图像,用户可以利用OCR(光学字符识别)技术将图像中的文字转换为可编辑的文本。OCR技术可以识别图像中的文字,并将其转换为可编辑的文本层,从而实现对文本的编辑。