说起来很简单,做起来很复杂:解密Chat GPT背后的原理与技术
你或许已经体验过ChatGPT,它能快速回答各种问题,生成文案、编写代码,甚至陪你聊些有趣的话题。看似简单易用,背后却隐藏着强大的技术支持。
输入几句话,ChatGPT仿佛“理解”了你的问题,立即给出准确的回答。但你可能好奇,它是怎么做到的?
其实,ChatGPT并不是真的“理解”我们,它背后是一个复杂的深度学习模型,通过大量的数据训练和无数次的推算来生成答案。每一句话的生成,都是在处理大量的词语和上下文,经过层层推理才得出的结果。
今天,我们就一起来揭开这个智能助手的技术秘密,探讨ChatGPT的工作原理,从最初的简单模型,到如今强大、流畅的交互能力,了解它背后那些令人惊叹的技术细节。这不仅是一次技术揭秘,更是了解AI如何改变我们生活的机会。
准备好了吗?让我们一探究竟!
1. GPT的核心理念:语言处理的全新思路
ChatGPT的基础是GPT(Generative Pre-trained Transformer),一种基于深度学习的语言模型。通俗来讲,GPT就像是一个从海量文本中“学习”语言模式的大脑。它的任务是根据你提供的上下文生成连贯的文字。
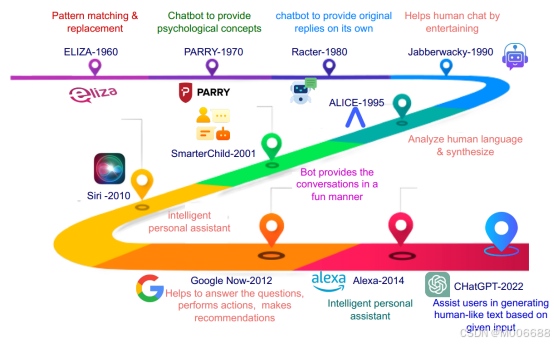
图:GPT Road Map
GPT背后的工作机制是自回归语言模型,也就是通过前面的词来预测下一个词。看似简单的“填空游戏”,实际上涉及了成千上万次的复杂运算。
细节解读:GPT模型中的核心组件是数以亿计的参数。这些参数类似于人脑中的神经突触,调节着模型的反应能力。当你输入一段文字时,GPT根据这些参数对输入进行处理,生成合适的下文。参数越多,模型的表现就越接近自然语言的表达。
2. Transformer架构:引领AI语言革命的技术
ChatGPT的强大来源于Transformer架构,它是一个颠覆性的自然语言处理模型架构。核心的技术就是自注意力机制(Self-Attention Mechanism),使得模型不仅能理解单个词的意义,还能快速抓住整个句子中的上下文关系。
标准的 Transformer 模型主要由两个模块构成:
Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。
技术亮点:传统语言模型处理文本时,常常只能逐字逐句进行,这样处理长句子时就容易“遗忘”之前的信息。而Transformer则不一样,它可以一次性“看到”整个句子,并理解词语之间的复杂关联。比如,当你说“我喜欢读书,因为它让我放松”,Transformer架构能够理解“喜欢读书”与“放松”之间的联系,并生成符合语境的回答。
这种全局处理能力,使得Transformer成为现代自然语言处理的“核心技术”,大幅提升了语言理解的效率和准确性。
3. 预训练与微调:ChatGPT的学习之路
ChatGPT并非一开始就拥有语言理解的能力,它经历了两个主要的学习过程:预训练和微调。
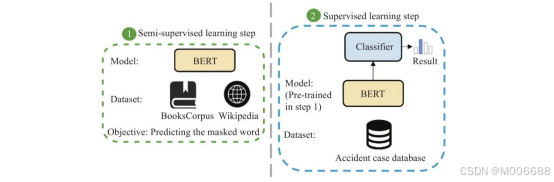
BERT模型预训练-微调过程
- - 预训练:在这一阶段,GPT模型通过海量文本数据进行自我“学习”,它需要从上下文中预测出缺失的单词。你可以把这个过程想象成一个无限的“填词游戏”,通过反复纠错,模型逐渐掌握语言的结构和规律。
- - 微调:预训练完成后,模型还需要进一步微调,以适应特定任务。ChatGPT在微调阶段使用的是对话数据集,这让它在与人互动时表现得更加自然。
细节深入:微调过程中的核心技术是监督学习与强化学习。在监督学习中,开发者会给模型提供正确答案,帮助它进一步优化。而强化学习则引入了人类反馈:模型生成多个不同的回答,人类评估它们的质量,模型再根据评估结果不断调整。这种方式使得ChatGPT在生成对话时越来越贴近人类的思维。
4. 自回归生成:聊天时模型的“思维”过程
当你输入问题时,ChatGPT的回答并不是一次生成的,而是逐词、逐句预测出来的。这个过程称为自回归生成,模型会根据已经生成的内容,不断预测下一个词,直到完成整个回答。
生成优化技术:为了提高回答的质量,ChatGPT采用了多种生成策略,例如top-k采样和top-p采样。
- - top-k采样:模型每次生成下一个词时,会从最有可能的前k个词中随机选择一个,而不是固定地选择最可能的词。这样能增加对话的多样性,避免生成一成不变的答案。
- - top-p采样:这是一种动态调整策略,它根据上下文调整候选词的选择范围,确保生成的内容不仅多样,还与上下文保持一致。
温度调节也是一个重要参数。高温度会让模型生成更多样化的回答,但也可能引入一些不连贯的内容;而低温度则让模型的回答更加保守和准确。开发者可以根据任务需求调整温度,达到最佳的生成效果。
你可能听说过GPT-2、GPT-3甚至是更大的模型。模型的大小通常由参数量决定,参数越多,模型的能力通常越强大。ChatGPT基于的GPT-3模型拥有1750亿个参数,这让它比之前的版本更擅长处理复杂问题。
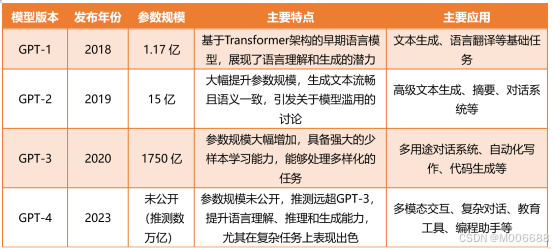
每个参数可以看作是模型的一个“神经元”,越多的神经元意味着模型能够更细致地捕捉语言中的细微差别。这也解释了为什么更大的模型通常能够生成更具连贯性、上下文相关性更强的回答。
然而,如此庞大的模型在训练过程中需要强大的计算资源,例如高性能GPU集群和大量的数据存储。如何在保持模型性能的同时降低计算成本,成为未来AI研究的一个重要方向。
6.GPT的局限:为什么有时它会出错?
虽然ChatGPT表现得非常智能,但它并不完美。有时它会生成一些看似合理但实际上错误的答案。这是因为ChatGPT本质上是一个统计模型,它不具备真正的理解能力或推理能力。

技术瓶颈:GPT无法进行真正的逻辑推理。它依赖于训练数据中学到的模式,而不是通过推理得出结论。因此,当问题需要涉及事实性知识或复杂逻辑推理时,它有时会“卡壳”或者提供错误的答案。此外,ChatGPT也没有“记忆”,每次对话都是全新的,它无法记住之前和你谈过的内容。
结语
从GPT到ChatGPT,这一路的技术发展展示了AI语言模型的巨大潜力。从Transformer架构的创新到参数规模的极限扩展,ChatGPT不仅是一个对话助手,更是现代自然语言处理技术的杰出代表。虽然它还有不少局限,但未来随着技术的进步,它将变得越来越智能。无论是语言生成、逻辑推理还是多模态处理,ChatGPT和它的后继者们都将在更多领域扮演更重要的角色。
超级AI大脑
说了这么多人工智能的的知识,接下来我们想介绍超级AI大脑给大家认识,这是一个复合型的人工智能应用平台。
它会及时推送关于Chat GPT、MJ绘画等人工智能的相关知识,方式也很简单,直接扫二维码即可。

超级AI大脑的出现,是为了帮助每一位朋友更好地使用人工智能这个强大的工具,利用人工智能来处理各种问题,并提供简单明了的解决方案。
也可以直接添加小编的社交媒体账号。
我们希望每个人都可以获得有价值的信息和交流,让我们一起共同进步。