Redis-哨兵
概念
Redis Sentinel 相关名词解释

注意:
- 哨兵机制不负责存储数据,只是对其它的redis-server进程起到监控的作用
- 哨兵节点,也会搞一个集合,防止一个挂了
⼈⼯恢复主节点故障
用户监控:
实际开发中,对于服务器后端开发,监控程序,是很重要的
服务器长期运行,总会有一些意外,具体什么时候出现意外,无法预知,就写一个监控程序,来监控服务器的运行状态
监控程序,往往搭配报警程序
服务器出现状态异常,就触发报警程序,给程序员报警
程序员如何恢复?
1.先看看主节点能不能抢救,好不好抢救
2.如果主节点短时间内难以恢复,就挑一个从节点,设置为新的主节点
a)选中新的主节点,通过slaveof no one自立山头
b)把其他的从节点,修改slaveof发主节点IP port,连上新的主节点
c)告知客户端,让客户端能够连接新的主节点,完成修改操作
当之前挂的主节点,修改好之后,就可以作为一个新的从节点,挂到这组机器中
当然,这个人工干预的做法,十分繁琐
哨兵⾃动恢复主节点故障
当主节点出现故障时,RedisSentinel能⾃动完成故障发现和故障转移,并通知应⽤⽅,从⽽实现 真正的⾼可⽤
Redis Sentinel 架构

这三个哨兵进程会监控现有的redis master和slave
(监控:这些进程之间,会建立tcp长连接,定期发送心跳包)
借助上述的监控机制,就可以及时发现,某个主机是否挂了
如果从节点挂了,无影响
如果主节点挂了,问题就大了,哨兵就要发挥作用了
- 此时,一个哨兵节点发现主节点挂了,不够,需要多个哨兵节点共同认同这件事,防止出现误判
- 主节点确实是挂了,这些哨兵节点,就会推举出一个leader,由这个leader负责从现有的从节点,挑选出一个作为新的主节点
- 挑选出新的主节点之后,哨兵节点,就会自动控制被选中的节点,执行slave no one,并且控制其它从节点,修改slaveof到新的主节点
- 哨兵节点会自动通知客户端程序,告知新的主节点是谁,后续客户端就会针对新的主节点进行写操作了

RedisSentinel核心功能
监控:Sentinel节点会定期检测Redis数据节点、其余哨兵节点是否可达
故障转移:实现从节点晋升(promotion)为主节点并维护后续正确的主从关系
通知:Sentinel节点会将故障转移的结果通知给应⽤⽅
安装部署(基于docker)
引入
这里涉及到六个节点,此时,只有一个云服务器,就在这里完成搭建
由于这些节点很多,相互之间容易打架,依赖的端口号/配置文件/数据文件...
如果直接部署,就需要去避开这些冲突,这种方式比较繁琐
下面用docker去解决上述问题:
docker可以认为是一个"轻量级"的虚拟机,起到了虚拟机这样的的隔离环境的效果,但是又没有吃很多的硬件资源,即使是比较拉跨的云服务器,也能构造出好几个这样的虚拟的环境
docker中关键概念"容器",看作一个轻量级的虚拟机
docker中"镜像"和"容器"的关系,相当于"可执行程序"和"进程"关系
拉取到的镜像,里面包含一个精简的linux操作系统,并且上面会安装redis,只要基于这个镜像创建一个容器跑起来,此时,redis服务器就搭建好了
准备工作
①安装docker和docker-compose
apt install docker-compose
②停⽌之前的redis-server
service redis-server stop
# 停⽌ redis-sentinel 如果已经有的话
service redis-sentinel stop
③ 使⽤docker获取redis镜像
#配置
vim /etc/docker/daemon.json
{
"registry-mirrors":["https://dockerpull.com"]
}
sudo systemctl daemon-reload
sudo systemctl restart docker
docker pull redis:5.0.9

编排redis主从节点
docker-compose进行容器编排
此处涉及多个redis server,也有多个redis哨兵节点
每一个redis server或者每一个redis哨兵节点都是作为一个单独的容器
通过一个配置文件,把具体要创建哪些容器,每个容器运行的各种参数,描述清楚,后续通过一个简单的命令,就能批量的启动/停止这些容器
注意:
redis哨兵节点,有一个也是可以的,也能完全上面的功能
1.如果哨兵节点只要一个,自身是容易出现问题的
2.出现误判的概率比较高
毕竟网络传输是容易出现抖动或者延迟,丢包的,如果只有一个,出现问题的影响就很大
基本原则 :
在分布式系统中,避免"单点"
哨兵节点,最好奇数个,最少3个
使用yml这样的格式来作为配置文件
1)创建三个容器,作为redis的数据节点(一主,两从)
2)创建三个容器,作为redis的哨兵节点
其实也是可以用一个yml文件,直接启动6个容器,但是如果同时启动,可能是哨兵先启动完成,数据节点后启动完成,哨兵可能就会认为数据节点挂了,会影响观察执行日志的过程


version: '3.7'
services:master:image: 'redis:5.0.9'container_name: redis-masterrestart: alwayscommand: redis-server --appendonly yesports:- 6379:6379slave1:image: 'redis:5.0.9'container_name: redis-slave1restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6380:6379slave2:image: 'redis:5.0.9'container_name: redis-slave2restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6381:6379
~ 

docker容器,可以理解成是一个轻量的虚拟机,在这个容器里,端口号和外面宿主机的端口号是两个体系
如果容器外面使用了5000端口,内部也可以使用,彼此不会冲突
三个容器,每个容器内部的端口号都是自成一派的,容器1的6379和2的6379之间是不会有冲突的,可以把两个容器视为两个主机
有的时候,希望在容器外面能够访问到容器里面的端口,就可以把容器内部的端口映射成宿主机的端口,后续防伪码宿主机的这个端口,就相当于在访问在访问对应容器的对应端口
站在宿主的角度,访问上述几个端口的时候,也不知道这个端口实际上一个宿主机的服务,还是来自容器内部的服务,只要正常去使用即可

此处不必写主节点ip,直接写主节点的容器名
容器启动之后,被分配的ip是啥也不知道
容器名类似于域名一样,docker自动进行域名解析,就得到对应的ip
启动所有容器:
docker-compose up -d

查看正在运行的容器:
docker ps -a
编排 redis-sentinel节点
![]()

version: '3.7'
services:sentinel1:image: 'redis:5.0.9'container_name: redis-sentinel-1restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/etc/redis/sentinel.confports:- 26379:26379sentinel2:image: 'redis:5.0.9'container_name: redis-sentinel-2restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/etc/redis/sentinel.confports:- 26380:26379sentinel3:image: 'redis:5.0.9'container_name: redis-sentinel-3restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/etc/redis/sentinel.confports:- 26381:26379
哨兵节点,会在运行过程中,对配置文件进行自动的修改
因此,就不能拿一个配置文件,给三个容器分别映射
既然内容相同,为啥要创建多份配置⽂件?
redis-sentinel 在运⾏中可能会对配置进⾏rewrite,修改⽂件内容.
如果⽤⼀份⽂件,就可能出现修改混乱的情况

这里的票数,是为了更稳健的确认,当前的redis-server是否挂了,不能听一个哨兵的一面之词

docker的一个核心功能,能够进行端口的映射,容器内使用什么端口都行,但是映射出去之后,还是要确保端口不能重复
sentinel1:


bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000sentinel2和sentinel3:

启动所有容器:

查看运⾏⽇志:

此处这个哨兵节点,不认识redis-master
docker-compose一下子启动了N个容器,此时N个容器处于同一个"局域网"中
可以使这个N个容器之间相互访问
三个redis-server节点,是一个局域网
三个哨兵节点,是另一个局域网,是新创建的
默认情况下,这两个网络不互通
解决方案:可以使用docker-compose把此处的两组服务给放到同一个局域网中
互通
docker network ls列出当前docker中的局域网

在docker-compose.yml中加入:
![]()

version: '3.7'
services:sentinel1:image: 'redis:5.0.9'container_name: redis-sentinel-1restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/etc/redis/sentinel.confports:- 26379:26379sentinel2:image: 'redis:5.0.9'container_name: redis-sentinel-2restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/etc/redis/sentinel.confports:- 26380:26379sentinel3:image: 'redis:5.0.9'container_name: redis-sentinel-3restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/etc/redis/sentinel.confports:- 26381:26379networks:default:external:name: redis-data_default
此时先把原来的docker停止,重启:

再查看logs,成功:

观察redis-sentinel 的配置rewrite
再次打开哨兵的配置⽂件,发现⽂件内容已经被⾃动修改了

哨兵存在的意义,能够在redis主从结构出现问题的时候,找出一个新的主节点来代替之前挂了的节点,保证整个redis仍然是可用状态
重新选举
下面手动把主节点干掉:
![]()
主节点此时就处于退出状态:

查看日志:
![]()

此时redis-master挂了
- sdown:主观下线,本哨兵节点,认为该主节点挂了
- odown:客观下线,好几个哨兵都认为该节点挂了,达成一致(法定票数)
此时就需哨兵节点选出一个新的主节点

此时再去连接6379:
无法连接

看6390和6381:


redis-master 重启之后
把刚才挂了的主节点再启动起来:
![]()


此时就已经失去主节点的身份了
选举原理
哨兵重新选取主节点的流程
1. 主观下线
哨兵节点通过心跳包,判定redis服务器是否正常工作
如果心跳包没有如约而至,就说明redis服务器挂了
此时还不能排除网络波动的影响,只能单方面认为挂了
2. 客观下线
多个哨兵都认为主节点挂了(法定票数),哨兵就认为这个主节点客观下线
3. 选举出哨兵的leader
要让多个哨兵节点,选出一个leader节点,由这个leader负责选一个从节点作为新的主节点
1号哨兵:
![]()
2号哨兵:
![]()
2号哨兵立即给自己投了一票:
![]()
1号投给了自己:
![]()
2,3都投给了2号哨兵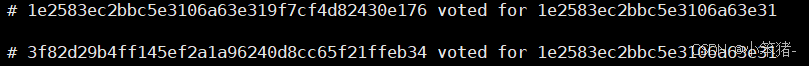
2号就成为了leader
4. leader 挑选出合适的slave成为新的 master
此时leader选举完毕,leader就需要挑选一个从节点,作为新的主节点
1)优先级
每个redis数据节点,都会在配置文件中,有一个优先级的设置
slave-priority默认一样
优先级高的从节点,就会胜出
2)offset
offset最大,就胜出
offset从节点从主节点这边同步数据的进度,数值越大,说明从节点的数据和主节点越接近
3)run id
每个redis节点启动的时候随机生成的一串数字(大小全凭运气)
谁的id⼩,谁上位
新节点指定好之后:
leader就会控制这个从节点,执行slave no one,成为master
再控制其它节点,执行slaveof,让这些其它节点,以新的master作为主节点
总结
- 哨兵节点不能只有⼀个.否则哨兵节点挂了也会影响系统可⽤性.
- 哨兵节点最好是奇数个.⽅便选举leader,得票更容易超过半数.(大部分情况是3个)
- 哨兵节点不负责存储数据.仍然是redis主从节点负责存储.
- 哨兵+主从复制解决的问题是"提⾼可⽤性",不能解决"数据极端情况下写丢失"的问题.
- 哨兵+主从复制不能提⾼数据的存储容量.当我们需要存的数据接近或者超过机器的物理内存,这样 的结构就难以胜任了.为了能存储更多的数据,就引⼊了集群