【YashanDB知识库】由于hist_head$中analyze time小于tab$中analyze time导致的sql语句执行慢
本文内容来自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7459465.html?templateId=1718516
问题现象
某局点yashandb cpu使用率100%,经线上分析是由于几个sql执行慢,其中一个sql为简单的单行等值绑定变量过滤+排序。
经分析执行计划,相对以前有所变化,走了另外一个索引(效率低)。
问题的风险及影响
sql语句执行慢,客户的业务受到影响。操作系统cpu 100%可能导致宕机。
问题影响的版本
22.2.10.100
问题发生原因
hist_head 中表对应列的 a n a l y z e t i m e 小于 t a b 中表对应列的analyze time小于tab 中表对应列的analyzetime小于tab中表的analyze time,在执行到estColEqualOrNotParam方法时,由于第一个参数colStats为null导致获得默认selectivity(0.04)后退出。而实际选择率为0.00003,相差甚远,优化器最终估算出来的cost不准,选择了错误的执行计划。
解决方法及规避方式
客户现网通过将错误的索引invisiable后规避。
问题分析和处理过程
现网错误的执行计划及估算出来的rows及cost(sql语句中有hint,可以忽略,实际不加hint也走的是这个执行计划):

过滤条件中sub_account_id的选择性很好,表的总数据量为6千万左右,count(distinct)值为200万左右。很明显,上图中执行计划估算出来的rows是明显失真的。
实际正确的执行计划及cost如下(where语句中多了几个predicate,不影响总量本质):
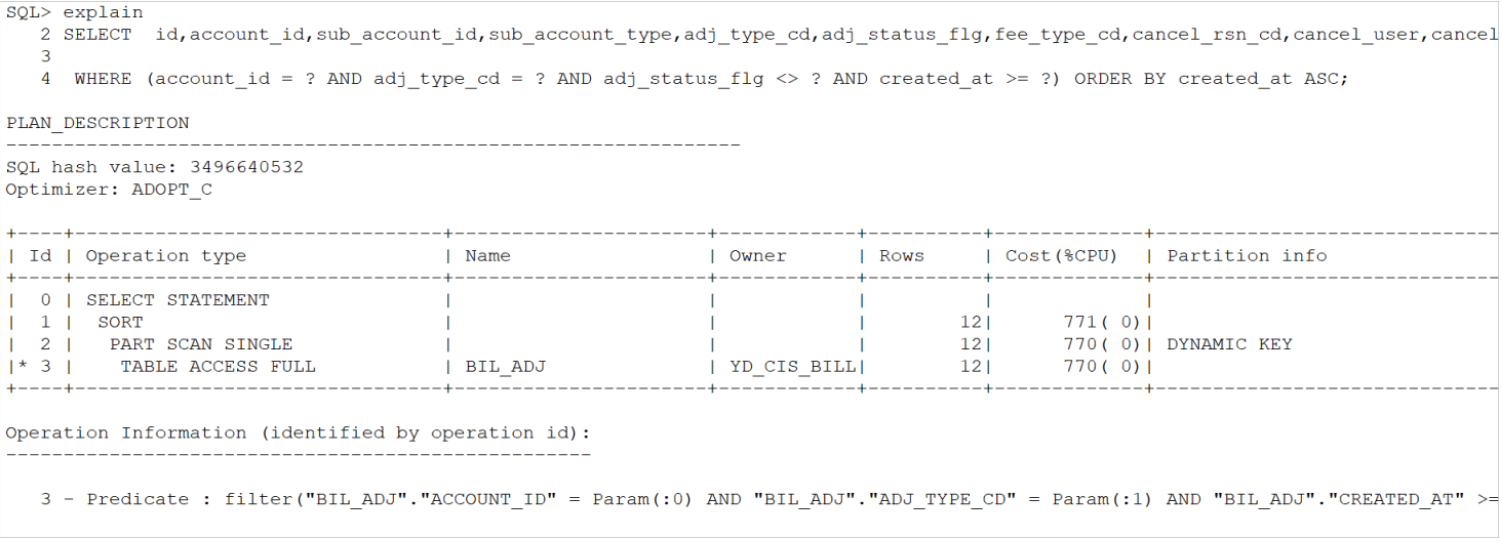
实际优化器在加载列的统计信息用于估算时,如果hist_head 中 a n a l y z e t i m e 小于 t a b 中analyze time小于tab 中analyzetime小于tab中analyze time,或者hist_head$中没有表中相关列的数据,那么就会用默认的selectivity(0.04)来做过滤条件估算,最终导致执行计划走偏。
经验总结
hist_head 中存放了列的普通统计信息, h i s t g r m 中存放了列的普通统计信息,histgrm 中存放了列的普通统计信息,histgrm中存放了列的直方图信息