并行程序设计基础——并行I/O(3)
目录
一、多视口的并行文件并行读写
1、文件视口与指针
1.1 MPI_FILE_SET_VIEW
1.2 MPI_FILE_GET_VIEW
1.3 MPI_FILE_SEEK
1.4 MPI_FILE_GET_POSTION
1.5 MPI_FILE_GET_BYTE_OFFSET
2、阻塞方式的视口读写
2.1 MPI_FILE_READ
2.2 MPI_FILE_WRITE
2.3 MPI_FILE_READ_ALL
2.4 MPI_FILE_WRITE_ALL
3、非阻塞方式的视口读写
3.1 MPI_FILE_IREAD
3.2 MPI_FILE_IWRITE
4、两步非阻塞视口组调用
4.1 MPI_FILE_READ_ALL_BEGIN
4.2 MPI_FILE_READ_ALL_END
4.3 MPI_FILE_WRITE_ALL_BEGIN
4.4 MPI_FILE_WRITE_ALL_END
本节继续对并行I/O部分的剩余内容进行介绍。
一、多视口的并行文件并行读写
前面所介绍的文件读写方法,都不涉及文件指针,文件读写的位置都是作为参数明确给出的,这一部分介绍的文件读取都是从一个特定的文件视口中,从文件指针的当前位置,对文件进行读写操作。
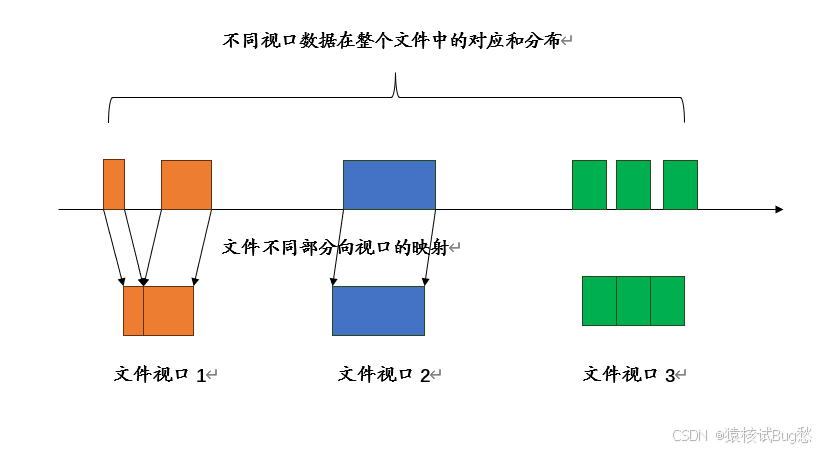
不同进程对应的文件指针可以是互不相同的,它们可以分别指向同一文件的不同位置。视口是相对于某一进程来说的,它是特定进程所能看到的文件,某一进程的文件视口可以是整个文件,但多数情况下,文件视口只是整个文件的一个或几个部分。文件视口在整个文件中对应的部分可以是不连续的,但各个进程看到的其文件视口中的数据却是连续的。
1、文件视口与指针
文件视口可以用一个三元组来表示:
<起始偏移,基本类型,文件类型>
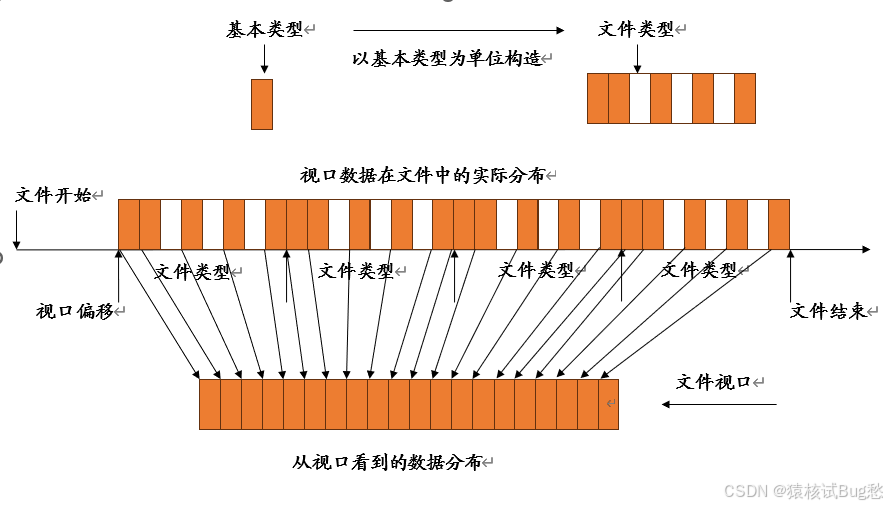
其中偏移是指该视口在文件中的起始位置,该位置度量是以字节为单位的。基本类型是视口数据存取的基本单位,基本类型可以是MPI的预定义数据类型或派生数据类型。文件类型或者就是基本类型,或者是从基本类型派生出来的其它类型,文件类型真正限定了文件中哪些数据可以被视口访问,哪些数据对视口是不可见的。文件视口就是文件中从特定的偏移开始,连续多个直至文件结束的特定文件类型组成的。
1.1 MPI_FILE_SET_VIEW
MPI_FILE_SET_VIEW设置文件视口,它是一个组IO调用,所有与fh相联系的进程组中的进程都执行这一调用。调用进程在fh对应的文件中设置本进程的文件视口,该视口相对于文件头的偏移是disp,即视口首先从文件中跳过disp个字节,然后给出了视口数据的基本数据单位etype,以后所有对该视口的访问必须以etype为单位来进行,而filetype则在etype的基础上,通过以etype为单位定义数据类型filetype,将视口不需要的数据排斥在外,即一般filetype定义的数据类型是有“空穴”的,这些空穴是视口无需访问的数据。
MPI_FILE_SET_VIEW(fh, disp, etype, filetype, datarep, info)
INOUT fh 视口对应文件的文件句柄
IN disp 视口在文件中的偏移位置
IN etype 视口基本数据类型
IN filetype 视口文件类型
IN datarep 视口数据的表示方法
IN info 传递给运行时的信息//c语言的说明
int MPI_File_set_view(MPI_File fh, MPI_Offset disp, MPI_Datatype etype, MPI_Datatype filetype, char *datarep, MPI_Info info)
//Fortran语言的说明
MPI_FILE_SET_VIEW(FH, DISP, ETYPE, FILETYPE, DATAREP, INFO, IERROR)
CHARACTER*(*) DATAREP
INTEGER FH, ETYPE, FILETYPE, INFO, IERROR从上面内容可知,文件视口其实就是一种特殊的数据类型,它指定的位置不像前面定义派生数据类型那样是在内存中,而是在文件中。它的另一个约束是都必须以基本的数据单位etype为基础来进行定义,而不是可以任意使用不同的数据类型来定义;视口包含数据的多少其实是通过定义内容不连续的数据类型filetype来实现的,该类型不连续的部分是视口不需要访问的部分,手段指定本视口包括哪些数据;从偏移disp开始,连续重复N次直到文件结束,由数据类型filetype得到的新的派生数据类型,才是文件视口对应的数据类型。
以后当进程对它们各自的文件视口进行访问时,可以认为该文件中只包含视口对应的数据,而且数据之间是没有空隙的。
不同的进程,通过在相同的文件上定义互不交叉的文件视口,就可以实现对文件的并行访问。
MPI_FILE_SET_VIEW调用完成后,原来的文件句柄fh就不再代表该文件,而是代表本调用产生的文件视口,以后使用fh对文件的所有操作都是对其视口的操作。
其中视口数据的表示方法有三种:native、internal和external32。定义数据表示是为了高效解决MPI的一致性问题,因为不同类型的计算机,其数据的表示方法是不同的。
①native:该数据表示的含义是数据在文件中的存储方式和在内存中的完全一样。这样在进行文件存取时,就没有数据转换的开销,对文件访问的效率和精度没有损失。显然这种方法在由不同类型的计算机组成的异构环境是行不通的,使用native数据表示虽然效率高,但存在移植性的问题。
②internal:该数据表示是由具体的实现来定义的,比如相同的MPI实现可以在不同类型的机器上实现数据转换,它是为了解决native数据表示的不可移植问题,通过在某一个具体的实现上提供特定的手段,来实现一定程度的移植性,它解决可移植问题并不彻底。
③external32:该数据表示是为了彻底解决任何不同类型机器之间的数