【算法】生成分布式 ID 的雪花算法
ID 是数据的唯一、不变且不重复的标识,在查询数据库的数据时必须通过 ID 查询,在分布式环境下生成全局唯一的 ID 是一个重要问题。
雪花算法(snowflake)是一种生成分布式环境下全局唯一 ID 的算法,该算法由 Twitter 发明,用于推文 ID 的生成。国内百度的 UidGenerator,美团的 Leaf 对雪花算法进行了优化,也都在 GitHub 上开源了。
一、为什么需要分布式 ID
在单机场景下,我们对 ID 的要求通过 MySQL 的主键自增就可以满足。
但随着系统数据量、并发压力的增加,原本的单机环境无法满足,需要对 MySQL 进行分库分表,对服务器进行分布式部署。此时,仅仅依靠 MySQL 的主键自增就有问题了。假设现在扩至两台数据库服务器,每台服务器的表 table1 上的 ID 都从 1 开始自增,此时就存在 ID 冲突了。当查询表 table1 中 ID = 234 的数据时,无法确定是哪一台服务器上的 ID。

在分布式环境下,数据遍布在不同服务器上的数据库中,此时我们如何为不同的数据生成全局唯一的主键呢?
答案就是:使用分布式 ID !
二、雪花算法的实现
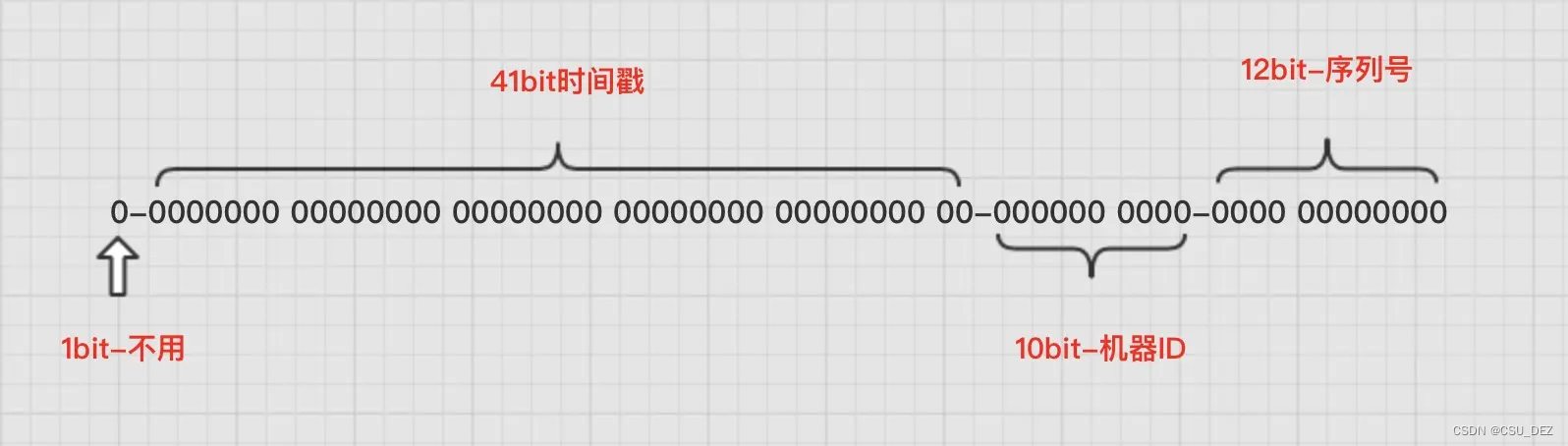
雪花算法生成的 分布式 ID 由四部分组成:
- 第一个 bit,恒为 0。
- 第 2 ~ 42 个bit,表示时间戳,单位是毫秒。
- 第 43 ~ 52 个bit,表示机器 ID,最多 1024 个机器节点,这部分可以根据业务不同做修改。
- 第 53 ~ 64 个bit,表示序号,即某台机器在这一毫秒内生成的 ID 的序号。可以用这 12 位 bit 区分一毫秒内生成的 ID,最多区分 4096 个不同 ID。
那么在 1ms 时间内,最多可以生成 1024 x 4096 = 4194304 个 ID。
雪花算法的优点自不必多说,生成速度快,可灵活修改,生成 ID 有序递增等。
同时它的显著缺点就是需要解决重复 ID 问题,因为它依赖时间,当机器时间不准时,就可能出现 ID 冲突。