FastAPI部署大模型Llama 3.1
项目地址:[self-llm/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md at master · datawhalechina/self-llm (github.com)](https://github.com/datawhalechina/self-llm/blob/master/models/Llama3_1/01-Llama3_1-8B-Instruct FastApi 部署调用.md)
目的:使用AutoDL的深度学习环境,简单部署大模型
## 环境准备
考虑到部分同学配置环境可能会遇到一些问题,我们在AutoDL平台准备了LLaMA3-1的环境镜像,点击下方链接并直接创建Autodl示例即可。 ***https://www.codewithgpu.com/i/datawhalechina/self-llm/self-llm-llama3.1***
首先 `pip` 换源加速下载并安装依赖包
```
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.111.1
pip install uvicorn==0.30.3
pip install modelscope==1.16.1
pip install transformers==4.42.4
pip install accelerate==0.32.1
```
## 模型下载
模型下载社区有魔塔和huggingface(被墙,可能不能使用),所以同意使用魔塔社区的方式下载模型
新建 `model_download.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 `python model_download.py` 执行下载,模型大小为 15GB,下载模型大概需要15 分钟。
```python
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
```

> 注意:如果模型下载失败,可以多试几次:运行 `python model_download.py`
## API部署代码
新建 `api.py` 文件并在其中输入以下内容,粘贴代码后请及时保存文件(Ctrl+`s`)。以下代码有很详细的注释
```
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global model, tokenizer # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
prompt = json_post_list.get('prompt') # 获取请求中的提示
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
# 调用模型进行对话生成
input_ids = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time
}
# 构建日志信息
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3___1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用
```
运行以上代码 `python api.py`
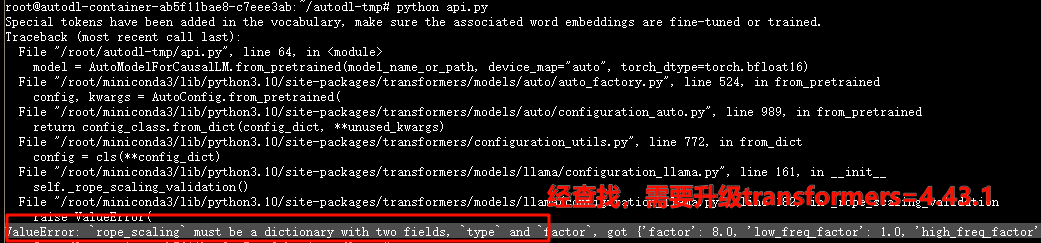
> 如果遇到以下bug:需要`pip install transformers==4.43.1`
## 部署测试
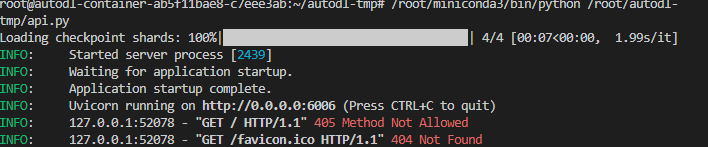
在终端输入以下命令启动api服务:
```
python api.py
```
加载完毕后出现如下信息说明成功。
默认部署在 6006 端口,通过 POST 方法进行调用,可以使用 curl 调用,如下所示:

- `curl`: 这是命令行工具的名字,用于从服务器获取或发送数据。
- `-X POST`: 这个选项指定了请求类型为 `POST`。`POST` 请求通常用于向服务器发送数据。
- `"http://127.0.0.1:6006"`: 这是请求的目标 URL。`127.0.0.1` 是本地回环地址,意味着请求将被发送到同一台计算机上运行的服务。`6006` 是服务监听的端口号。
- `-H 'Content-Type: application/json'`: 这个选项设置了请求头 (`Header`) 中的 `Content-Type` 字段为 `application/json`。这告诉服务器发送的数据是 JSON 格式。
- `-d '{"prompt": "你好"}'`: 这个选项指定了要发送的数据体 (`Body`)。在这里,数据是一个 JSON 对象,其中包含一个键值对,键是 `"prompt"`,值是 `"你好"`。这个数据体将作为请求的一部分发送给服务器。
也可以使用 python 中的 requests 库进行调用,我们新建一个test.ibynb文件,复制如下代码,按`Enter+Shift`运行代码。
```
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('我写了一篇文章:FastAPI部署大模型Llama3.1。你帮我写一段总结,100字以内'))
```
输出结果如下:

**部署大模型Llama 3.1 到 FastAPI**
本文介绍了如何将大模型Llama 3.1 部署到 FastAPI,一个现代、快速、强大的 Python web 框架。通过本教程,你将学习如何将 Llama 3.1 集成到 FastAPI 中,并利用其强大的自然语言处理能力来构建智能应用。
本文涵盖了以下内容:
* 安装和设置 FastAPI
* 下载和部署 Llama 3.1 模型
* 使用 FastAPI 与 Llama 3.1 进行交互
本教程适合任何对 AI 和机器学习感兴趣的开发者。