JVM笔记(九)选择合适的垃圾收集器
Epsilon收集器
Epsilon收集器由RedHat公司在JEP 318中提出,在此提案里Epsilon被形容成一个无操作的收集器(A No-Op Garbage Collector),而事实上只要Java虚拟机能够工作,垃圾收集器便不可能是真正“无操作”的。原因是“垃圾收集器”这个名字并不能形容它全部的职责,更贴切的名字应该是本书为这一部分所取的标题——“自动内存管理子系统”。一个垃圾收集器除了垃圾收集这个本职工作之外,它还要负责堆的管理与布局、对象的分配、与解释器的协作、与编译器的协作、与监控子系统协作等职责,其中至少堆的管理和对象的分配这部分功能是Java虚拟机能够正常运作的必要支持,是一个最小化功能的垃圾收集器也必须实现的内容。
收集器的权衡
我们应该如何选择一款适合自己应用的收集器呢?这个问题的答案主要受以下三个因素影响:
应用程序的主要关注点是什么?如果是数据分析、科学计算类的任务,目标是能尽快算出结果,那吞吐量就是主要关注点;如果是SLA应用,那停顿时间直接影响服务质量,严重的甚至会导致事务超时,这样延迟就是主要关注点;而如果是客户端应用或者嵌入式应用,那垃圾收集的内存占用则是不可忽视的。
运行应用的基础设施如何?譬如硬件规格,要涉及的系统架构是x86-32/64、SPARC还是ARM/Aarch64;处理器的数量多少,分配内存的大小;选择的操作系统是Linux、Solaris还是Windows等。
使用JDK的发行商是什么?版本号是多少?是ZingJDK/Zulu、OracleJDK、Open-JDK、OpenJ9抑或是其他公司的发行版?该JDK对应了《Java虚拟机规范》的哪个版本?
一般来说,收集器的选择就从以上这几点出发来考虑。举个例子,假设某个直接面向用户提供服务的B/S系统准备选择垃圾收集器,一般来说延迟时间是这类应用的主要关注点,那么:
如果你有充足的预算但没有太多调优经验,那么一套带商业技术支持的专有硬件或者软件解决方案是不错的选择,Azul公司以前主推的Vega系统和现在主推的Zing VM是这方面的代表,这样你就可以使用传说中的C4收集器了。
如果你虽然没有足够预算去使用商业解决方案,但能够掌控软硬件型号,使用较新的版本,同时又特别注重延迟,那ZGC很值得尝试。
如果你对还处于实验状态的收集器的稳定性有所顾虑,或者应用必须运行在Windows操作系统下,那ZGC就无缘了,试试Shenandoah吧。
如果你接手的是遗留系统,软硬件基础设施和JDK版本都比较落后,那就根据内存规模衡量一下,对于大概4GB到6GB以下的堆内存,CMS一般能处理得比较好,而对于更大的堆内存,可重点考察一下G1。
虚拟机及垃圾收集器日志
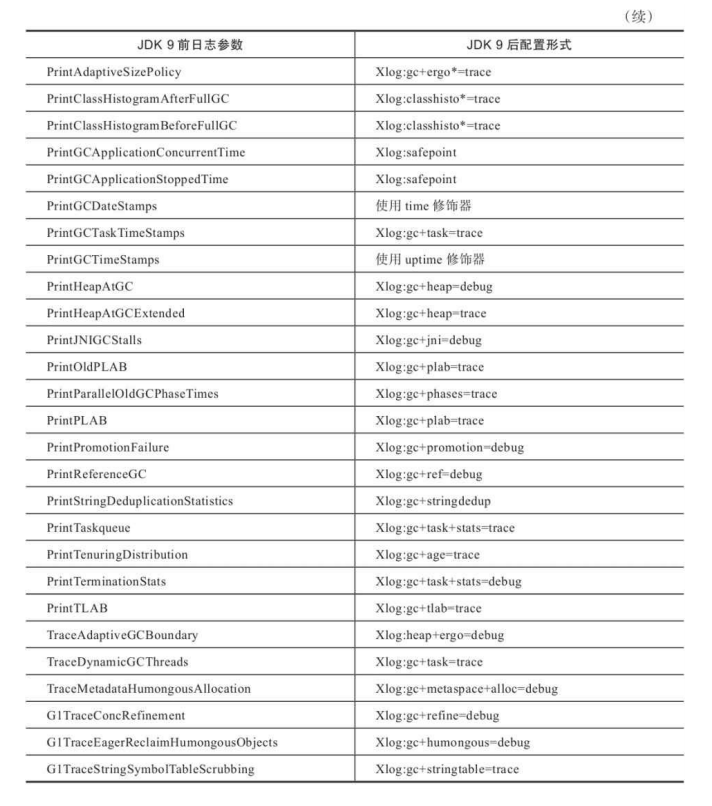
阅读分析虚拟机和垃圾收集器的日志是处理Java虚拟机内存问题必备的基础技能,直到JDK 9,这种混乱不堪的局面才终于消失,HotSpot所有功能的日志都收归到了“-Xlog”参数上.
命令行中最关键的参数是选择器(Selector),它由标签(Tag)和日志级别(Level)共同组成。
标签可理解为虚拟机中某个功能模块的名字,它告诉日志框架用户希望得到虚拟机哪些功能的日志输出。垃圾收集器的标签名称为“gc”,由此可见,垃圾收集器日志只是HotSpot众多功能日志的其中一项。
日志级别从低到高,共有Trace,Debug,Info,Warning,Error,Off六种级别,日志级别决定了输出信息的详细程度,默认级别为Info,HotSpot的日志规则与Log4j、SLF4j这类Java日志框架大体上是一致的。另外,还可以使用修饰器(Decorator)来要求每行日志输出都附加上额外的内容,支持附加在日志行上的信息包括:
·time:当前日期和时间。
·uptime:虚拟机启动到现在经过的时间,以秒为单位。
·timemillis:当前时间的毫秒数,相当于System.currentTimeMillis()的输出。
·uptimemillis:虚拟机启动到现在经过的毫秒数。
·timenanos:当前时间的纳秒数,相当于System.nanoTime()的输出。
·uptimenanos:虚拟机启动到现在经过的纳秒数。
·pid:进程ID。
·tid:线程ID。
·level:日志级别。·tags:日志输出的标签集。
如果不指定,默认值是uptime、level、tags这三个,此时日志输出类似于以下形式:
[3.080s][info][gc,cpu] GC(5) User=0.03s Sys=0.00s Real=0.01s
下面笔者举几个例子,展示在JDK 9统一日志框架前、后是如何获得垃圾收集器过程的相关信息,以下均以JDK 9的G1收集器(JDK 9下默认收集器就是G1,所以命令行中没有指定收集器)为例。
1)查看GC基本信息,在JDK 9之前使用-XX:+PrintGC,JDK 9后使用-Xlog:gc:
2)查看GC详细信息,在JDK 9之前使用-XX:+PrintGCDetails,在JDK 9之后使用-X-log:gc*,用通配符*将GC标签下所有细分过程都打印出来,如果把日志级别调整到Debug或者Trace(基于版面篇幅考虑,例子中并没有),还将获得更多细节信息:
3)查看GC前后的堆、方法区可用容量变化,在JDK 9之前使用-XX:+PrintHeapAtGC,JDK 9之后使用-Xlog:gc+heap=debug:
4)查看GC过程中用户线程并发时间以及停顿的时间,在JDK 9之前使用-XX:+PrintGCApplicationConcurrentTime以及-XX:+PrintGCApplicationStoppedTime,JDK 9之后使用-Xlog:safepoint:
5)查看收集器Ergonomics机制(自动设置堆空间各分代区域大小、收集目标等内容,从Parallel收集器开始支持)自动调节的相关信息。在JDK 9之前使用-XX:+PrintAdaptive-SizePolicy,JDK 9之后使用-Xlog:gc+ergo*=trace:
6)查看熬过收集后剩余对象的年龄分布信息,在JDK 9前使用-XX:+PrintTenuring-Distribution,JDK 9之后使用-Xlog:gc+age=trace: