【学习笔记】如何训练大模型
如何在许多 GPU 上训练真正的大型模型?
单个 GPU 工作线程的内存有限,并且许多大型模型的大小已经超出了单个 GPU 的范围。有几种并行范式可以跨多个 GPU 进行模型训练,还可以使用各种模型架构和内存节省设计来帮助训练超大型神经网络。
并行训练
训练超大型神经网络模型的主要瓶颈是对大量 GPU 内存的强烈需求,远远超过单个 GPU 机器上可以托管的内存。除了模型权重(例如数百亿个浮点数)之外,存储中间计算输出(例如梯度和优化器状态)(例如Adam中的动量和变化)通常甚至更昂贵。此外,训练大型模型通常会与大型训练语料库配对,因此单个过程可能需要很长时间。
因此,并行性是必要的。并行性可以发生在不同的维度,包括数据、模型架构和张量操作。
数据并行性
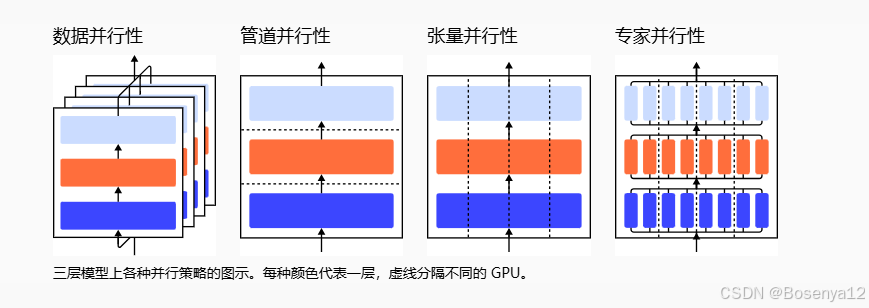
数据并行性 (DP) 最幼稚的方法是将相同的模型权重复制到多个工作线程中,并将一部分数据分配给每个要同时处理的工作线程。
如果模型大小大于单个 GPU 节点的内存,则 Naive DP 无法正常工作。像 GeePS (Cui et al. 2016) 这样的方法将暂时未使用的参数卸载回 CPU,以便在模型太大而无法放入一台机器时使用有限的 GPU 内存。数据交换传输应在后端进行,并且不会干扰训练计算。
模型并行性
模型并行性 (MP) 旨在解决模型权重无法适应单个节点的情况。计算和模型参数分布在多台机器上。与数据并行性不同,每个工作线程托管整个模型的完整副本,MP 仅在一个工作线程上分配一小部分模型参数,因此内存使用量和计算量都减少了。
由于深度神经网络通常包含一堆垂直层,因此将大型模型逐层拆分感觉很简单,其中一小群连续的层被分组到一个工作线程上的一个分区中。然而,通过具有顺序依赖性的多个此类工作线程运行每个数据批次的幼稚实现会导致等待时间的巨大泡沫和计算资源的严重利用不足。
管道并行性
管道并行性 (PP) 将模型并行性与数据并行性相结合,以减少低效的时间“气泡”。主要思想是将一个小批量分成多个微批量,并使每个阶段的工作人员能够同时处理一个微批量。请注意,每个微批次都需要两次传递,一次向前,一次向后。工作线程间通信仅传输激活(向前)和梯度(向后)。这些通道的调度方式以及梯度的聚合方式在不同的方法中有所不同。分区(工作线程)的数量也称为管道深度。
张量并行性
模型并行度和管道并行度都会垂直分割模型。OTOH 我们可以在多个设备上水平划分一个张量运算的计算,称为张量并行度 (TP)。
训练大型神经网络的技术
大型神经网络是 AI 领域许多最新进展的核心,但训练它们是一项艰巨的工程和研究挑战,需要编排一组 GPU 来执行单一的同步计算。
大型神经网络是 AI 领域许多最新进展的核心,但训练它们是一项艰巨的工程和研究挑战,需要编排一组 GPU 来执行单一的同步计算。随着集群和模型大小的增长,机器学习从业者已经开发了越来越多的技术来在许多 GPU 上并行进行模型训练。乍一看,理解这些并行技术可能看起来令人生畏,但只要对计算结构做出一些假设,这些技术就会变得更加清晰——在这一点上,你只是在从 A 到 B 的不透明位之间穿梭,就像网络交换机在数据包周围穿梭一样。
训练神经网络是一个迭代过程。在每次迭代中,我们都会通过模型的层(在新窗口中打开)计算一批数据中每个训练样本的输出。然后继续进行另一次传递向后(在新窗口中打开)通过各层,通过计算 a 传播每个参数对最终输出的影响程度梯度(在新窗口中打开)关于每个参数。批次的平均梯度、参数和一些每个参数的优化状态将传递给优化算法,例如亚当(在新窗口中打开),用于计算下一次迭代的参数(在数据上的性能应该略好一些)和新的每个参数的优化状态。随着训练对成批数据的迭代,模型会不断发展,以产生越来越准确的输出。
各种并行技术将此训练过程划分为不同维度,包括:
- 数据并行性 - 在不同的 GPU 上运行批处理的不同子集;
- 流水线并行性 - 在不同的 GPU 上运行模型的不同层;
- 张量并行性 - 分解单个运算的数学运算,例如在 GPU 之间拆分的矩阵乘法;
- Mixture-of-Experts - 仅通过每层的一小部分处理每个示例。
参考链接
How to Train Really Large Models on Many GPUs?
Techniques for training large neural networks