redis内存淘汰策略-------Reservoir Sampling(水库采样)
文章目录
- 过期删除策略和内存淘汰策略
- 内存淘汰策略
- evictionPoolEntry
- evictionPoolPopulate
- Reservoir Sampling
- dictGetRandomKey
- dictGetSomeKeys
- Reservoir Sampling
- chatgpt对Reservoir Sampling的介绍
过期删除策略和内存淘汰策略
详细介绍请参考博客“redis过期删除策略和内存淘汰策略”
内存淘汰策略
为了节省内存,redis并没有采用传统的方法实现LRU和LFU而是基于随机采样的方式,近似实现LRU和LFU,并引入淘汰池进行优化。接下来详细看看是如何淘汰池进行优化的。具体实现在"evict.c"文件中的函数"evictionPoolPopulate"。
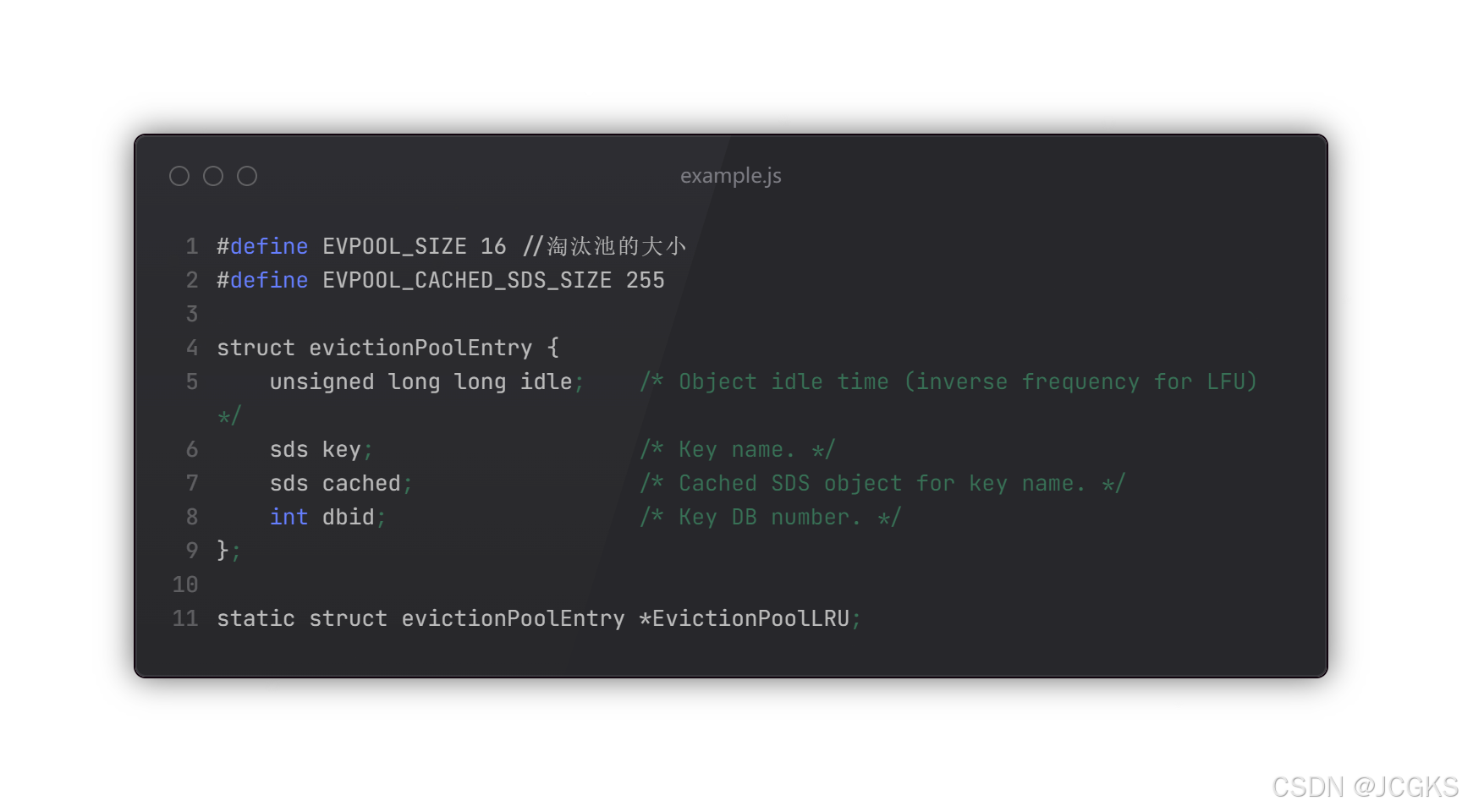
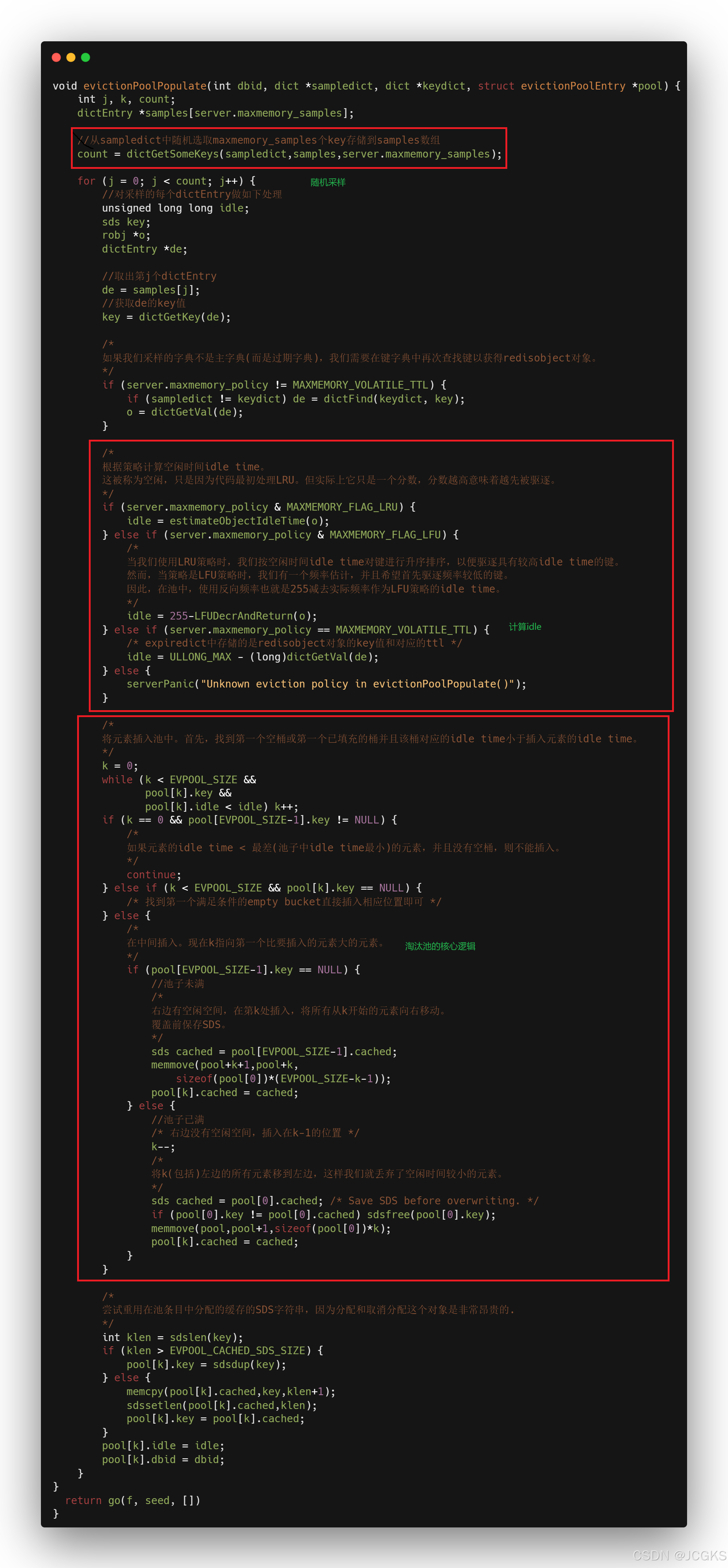
/* This is a helper function for performEvictions(), it is used in order* to populate the evictionPool with a few entries every time we want to* expire a key. Keys with idle time bigger than one of the current* keys are added. Keys are always added if there are free entries.** We insert keys on place in ascending order, so keys with the smaller* idle time are on the left, and keys with the higher idle time on the* right. */这个函数是"performEvictions()"的辅助函数。每当想要过期一些key时该函数被用来向淘汰池填充一些数据。当淘汰池未满时,keys总是被添加;反之的话,添加具有更大idle time的keys。淘汰池按照idle time升序排序,即较小idle time的key存储在淘汰池的左边,较大idle time的key存储在淘汰池的右边。
/* When an LFU policy is used instead, a reverse frequency indication is used* instead of the idle time, so that we still evict by larger value (larger* inverse frequency means to evict keys with the least frequent accesses).*/当使用LFU策略时,用反向频率reverse frequency代替idle time。按照reverse frequency升序排序,较大的inverse frequency意味着keys具有较小的lfu值即least frequent accesses。
evictionPoolEntry
evictionPoolPopulate
Reservoir Sampling
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
接下来看一下随机采样的逻辑。
dictGetRandomKey
首先看一下随即采取一个dictEntry的逻辑
/* Return a random entry from the hash table. Useful to* implement randomized algorithms */
从hash table中返回一个随机entry。用来实现随机算法。
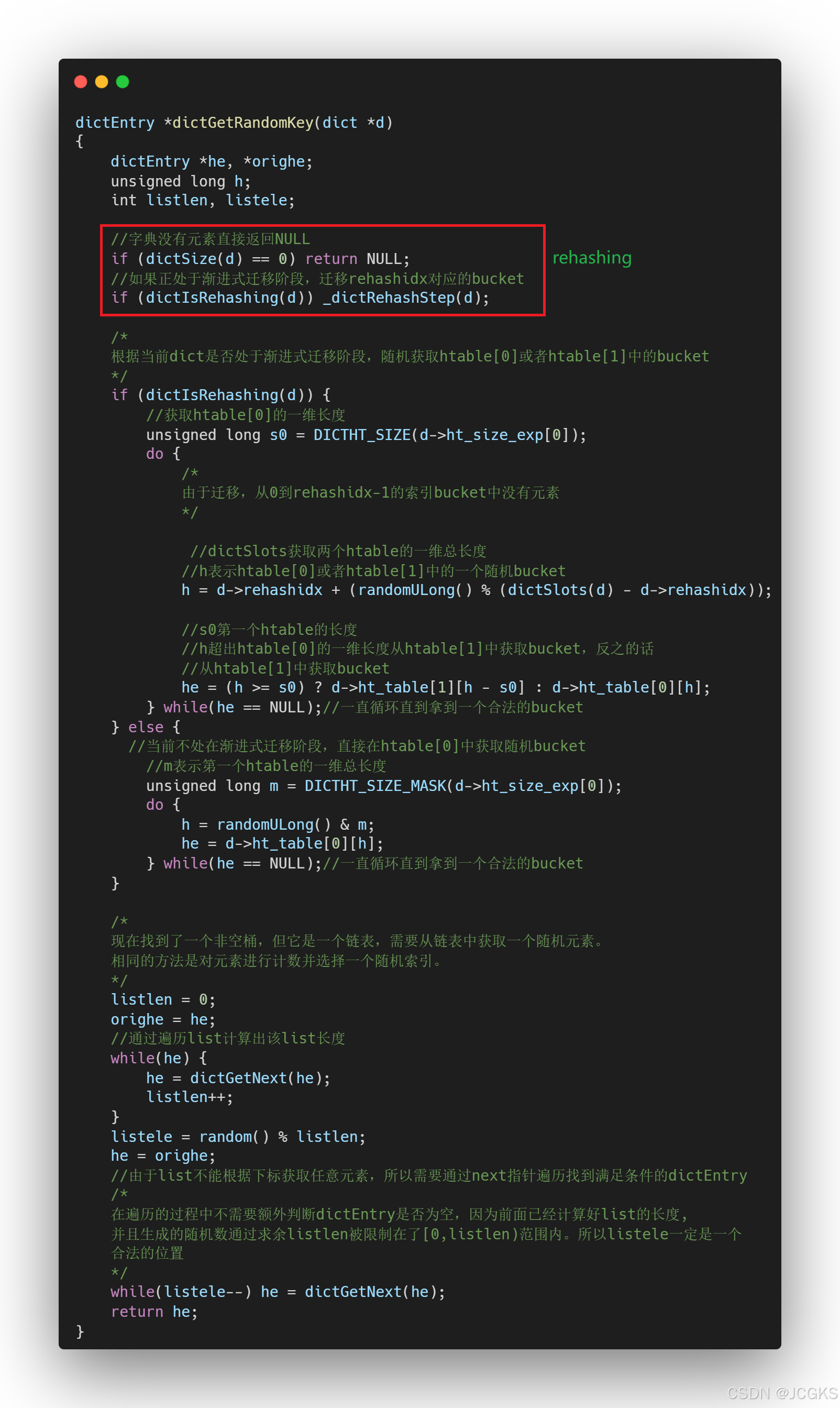
从代码中可以看出,在进行随机采样一个dictEntry时,会判断dict当前是否处于rehashing阶段,如果是的话就进行迁移操作
在"redis7.2.2|Dict"这篇文章中已经介绍过,dict何时会发生rehashing
dictGetSomeKeys
接下来看一下随机采取多个dictEntry的逻辑。
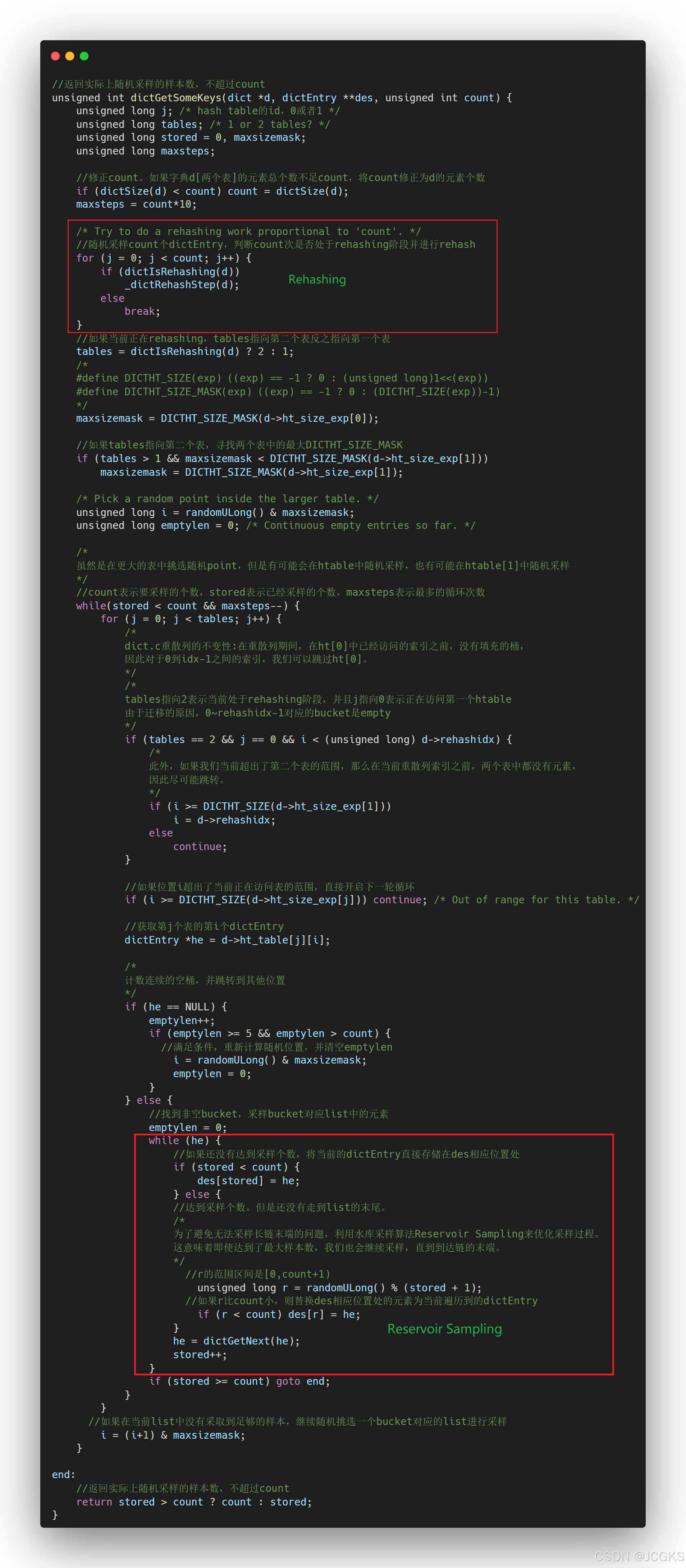
/* This function samples the dictionary to return a few keys from random* locations.** It does not guarantee to return all the keys specified in 'count', nor* it does guarantee to return non-duplicated elements, however it will make* some effort to do both things.** Returned pointers to hash table entries are stored into 'des' that* points to an array of dictEntry pointers. The array must have room for* at least 'count' elements, that is the argument we pass to the function* to tell how many random elements we need.** The function returns the number of items stored into 'des', that may* be less than 'count' if the hash table has less than 'count' elements* inside, or if not enough elements were found in a reasonable amount of* steps.** Note that this function is not suitable when you need a good distribution* of the returned items, but only when you need to "sample" a given number* of continuous elements to run some kind of algorithm or to produce* statistics. However the function is much faster than dictGetRandomKey()* at producing N elements. */
这个函数对字典进行采样,从随机位置返回几个键。
它不保证返回'count'中指定的所有键,也不保证返回不重复的元素,但是它会努力做到这两件事。
返回的指向哈希表项的指针存储在指向dictEntry指针数组的'des'中。
数组必须至少有容纳'count'元素的空间,这是我们传递给函数的参数,用于告诉我们需要多少个随机元素。
该函数返回存储在'des'中的项数,如果哈希表中包含的元素少于'count',或者在合理的步骤中没有找到足够的元素,则可能小于'count'。
请注意,当您需要返回项的良好分布时,此函数不适用,而只适用于需要“抽样”给定数量的连续元素以运行某种算法或生成统计数据时。
然而,在生成N个元素时,该函数比dictGetRandomKey()快得多。
在生成N个元素时,该函数比dictGetRandomKey()快得多。
从代码中可以看出,在进行随机采样一个dictEntry时,会判断dict当前是否处于rehashing阶段,如果是的话就进行迁移操作
在"redis7.2.2|Dict"这篇文章中已经介绍过,dict何时会发生rehashing
- 通过研究代码发现:在生成N个元素时,函数"dictGetSomeKeys"确实要比函数"dictGetRandomKey"快得多。
- 因为对于"dictGetSomeKeys"函数来说,只需要确定一个bucket然后沿着list取样即可。但是对于"dictGetRandomKey"函数每生成一个元素都需要随机找到一个bucket并且还需要计算list的长度并且找到其中一个随机位置。
Reservoir Sampling
/* Collect all the elements of the buckets found non empty while iterating
* To avoid the issue of being unable to sample the end of a long chain,
* we utilize the Reservoir Sampling algorithm to optimize the sampling process.
* This means that even when the maximum number of samples has been reached,
* we continue sampling until we reach the end of the chain.
* See https://en.wikipedia.org/wiki/Reservoir_sampling. */
为了避免在长链末端无法采样的问题,我们采用了Reservoir Sampling算法来优化采样过程。
这意味着即使达到了最大样本数,我们也会继续采样,直到到达链的末端。
有关“Reservior Sampling”的详细介绍见https://en.wikipedia.org/wiki/Reservoir_sampling。
chatgpt对Reservoir Sampling的介绍
水库采样法(Reservoir Sampling)是一种在处理大规模数据流或未知大小的数据集合时,用于从中随机抽取固定数量样本的算法。它特别适用于数据流场景,因为在数据流开始之前并不知道其总量。
核心思想
水库采样的核心思想是在处理一个可能无限大的数据流时,从中抽取固定数量的样本,使得每个数据元素被选中的概率是相同的。
操作步骤
假设我们要从数据流中随机抽取k个元素,具体步骤如下:
- 初始化:创建一个大小为k的“水库”数组,并将前k个元素直接存入水库。
- 替换阶段:
- 对于每一个新的元素(假设这是第n个元素),生成一个随机数r,该随机数的范围是[0, n-1]。
- 如果r的值小于k,则用这个新元素替换水库中的第r个元素。
- 如果r的值大于等于k,则忽略这个元素。
举例说明
假设你有一个数据流,其中包含1000个元素,你想从中随机抽取10个样本。你会按以下步骤进行:
- 将前10个元素直接放入水库。
- 对第11个元素,生成一个随机数r,范围是[0, 10]。如果r的值在0到9之间,则用第11个元素替换水库中对应位置的元素。如果r等于10,则忽略这个元素。
- 重复上述步骤,直到处理完所有的1000个元素。
优势
- 空间效率高:只需要存储k个元素的水库,不论数据流的大小如何,这使得水库采样在内存限制的环境中特别有用。
- 公平性:保证了在最终的k个样本中,数据流中的每个元素被选中的概率是相同的。
应用场景
- 在线广告系统:随机抽取用户的行为数据,用于后续分析。
- 流媒体处理:在数据流不断到来的情况下,实时生成随机样本。
水库采样是一种简单而有效的算法,特别适用于在处理大规模数据时,确保样本具有代表性。