cudaMemGetInfo()函数cudaDeviceGetAttribute()函数来检查设备上的可用内存
使用CUDA Runtime API中的cudaMemGetInfo()函数来检查设备上的可用内存。该函数将返回当前可用于分配的总设备内存大小和当前可用于分配的最大单个内存块大小。
示例代码,演示了如何在分配内存之前和之后调用cudaMemGetInfo()函数来检查可用内存
size_t free_byte, total_byte;
cudaMemGetInfo(&free_byte, &total_byte);
// 输出设备上的总内存大小和可用内存大小
printf("Device memory: total %ld, free %ld\n", total_byte, free_byte);// 在此处分配内存// 分配内存后再次调用cudaMemGetInfo()来检查可用内存
cudaMemGetInfo(&free_byte, &total_byte);
printf("Device memory after allocation: total %ld, free %ld\n", total_byte, free_byte);首先调用了cudaMemGetInfo()来获取设备上的总内存和可用内存大小。
然后在注释处分配内存,再次调用cudaMemGetInfo()来检查分配内存后的可用内存大小。这可以帮助我们确保我们的内存分配不会超过设备的可用内存。
请注意,cudaMemGetInfo()函数返回的内存大小以字节为单位,因此可能需要将其转换为更具有可读性的单位(例如KB,MB或GB)来更好地了解设备上的内存使用情况。
size_t free_byte, total_byte;cudaMemGetInfo(&free_byte, &total_byte);// 输出设备上的总内存大小和可用内存大小printf("Device memory: total %ld, free %ld\n", total_byte, free_byte);//分配内存float* Ez, * Hy, * Hx;cudaMalloc((void**)&Ez, size1); cudaMemset(Ez, 0, size1);cudaMalloc((void**)&Hy, size1); cudaMemset(Hy, 0, size1);cudaMalloc((void**)&Hx, size1); cudaMemset(Hx, 0, size1);float* Ex, * Ey, * Hz;cudaMalloc((void**)&Ex, size1); cudaMemset(Ex, 0, size1);cudaMalloc((void**)&Ey, size1); cudaMemset(Ey, 0, size1);cudaMalloc((void**)&Hz, size1); cudaMemset(Hz, 0, size1);cudaMemGetInfo(&free_byte, &total_byte);printf("Device memory after allocation: total %ld, free %ld\n", total_byte, free_byte);
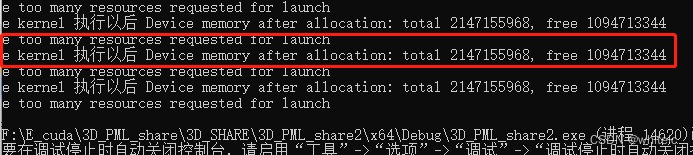
一开始是错误的,我的设备总内存大小为2GB(2147155968字节),在分配内存后剩余可用内存大小为1GB(1094713344字节)。还遇到了“too many resources requested for launch”错误,这通常意味着,线程块或线程数太多,超出了设备的能力范围

把block设置由【32,32,1】改成了【16,16,1】就对了(不太明白为啥会这样,因为我核函数的内容没有改变,只加了一些参数,并且这些参数没有被使用)
建议
检查CUDA Runtime API的返回值,以查看是否有其他错误或警告消息。可以在内核启动后立即调用cudaGetLastError()来检查最后一次CUDA Runtime API调用是否有任何错误,并使用cudaGetErrorString()函数将错误码转换为可读的字符串以进行调试
我的输出结果
如果不清楚的可以利用以下的cudaDeviceGetAttribute()函数查询,如果在使用该函数时出现未定义标识符的错误,则可能是由于未包含必要的CUDA头文件或未链接正确的CUDA库。
- 确保程序中包含了必要的CUDA头文件,例如cuda_runtime.h和device_launch_parameters.h。
#include <cuda_runtime.h>
#include <device_launch_parameters.h> - 使用cudaDeviceGetAttribute()函数时,还需要链接CUDA运行时库和CUDA驱动程序库
- CUDA库的目录位置可能因为操作系统和CUDA版本而异。以下是几个常见的位置:
Linux系统(默认安装):/usr/local/cuda/lib64
Linux系统(使用.run安装):/usr/local/cuda-/lib64
Windows系统(默认安装):C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\version\lib\x64
Windows系统(使用.exe安装):C:\Program Files\NVIDIA Corporation\CUDA\version\lib\x64
在上述目录中,表示安装的CUDA版本。例如,在Linux上,如果使用的是CUDA 11.0,则CUDA库目录应为/usr/local/cuda-11.0/lib64。
请注意,如果在系统上安装了多个CUDA版本,则需要相应地更改库目录路径,以确保使用正确的CUDA版本。
如果无法在上述目录中找到CUDA库,请尝试搜索系统以查找CUDA库。在Linux上,可以运行以下命令:
sudo find / -name “libcuda.so” 2>/dev/null
在Windows上,可以使用文件资源管理器搜索功能来查找CUDA库。
一旦找到了CUDA库的位置,可以使用
-L选项将其添加到链接器命令中。
例如,在Linux上,如果CUDA库目录为/usr/local/cuda/lib64,则可以使用以下命令来编译包含cudaDeviceGetAttribute()函数的CUDA程序:
nvcc your_program.cu -o your_program -lcudart -L/usr/local/cuda/lib64
在Windows上,需要将CUDA库的路径添加到系统环境变量PATH中,以便编译器能够找到CUDA库。
我要分析的.cu文件:
F:\E_cuda\3D_PML_share\3D_SHARE\3D_PML_share2\kernel.cu
我的cuda库文件
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64
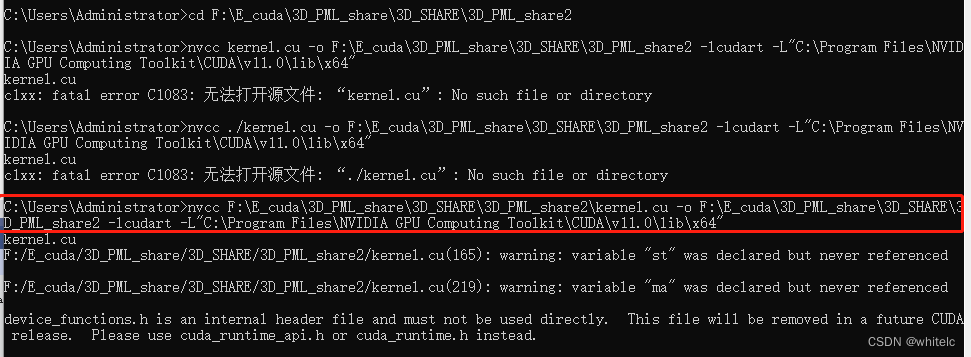
在命令行中输入以下
nvcc F:\E_cuda\3D_PML_share\3D_SHARE\3D_PML_share2\kernel.cu -o F:\E_cuda\3D_PML_share\3D_SHARE\3D_PML_share2 -lcudart -L"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64"
输出结果
输出
kernel.cu
F:/E_cuda/3D_PML_share/3D_SHARE/3D_PML_share2/kernel.cu(165): warning: variable "st" was declared but never referencedF:/E_cuda/3D_PML_share/3D_SHARE/3D_PML_share2/kernel.cu(219): warning: variable "ma" was declared but never referenceddevice_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead.
int max_threads_per_block;cudaDeviceGetAttribute(&max_threads_per_block, cudaDevAttrMaxThreadsPerBlock, 0);printf("Maximum threads per block: %d\n", max_threads_per_block);int max_threads_per_multiprocessor;cudaDeviceGetAttribute(&max_threads_per_multiprocessor, cudaDevAttrMaxThreadsPerMultiProcessor, 0);printf("Maximum threads per multiprocessor: %d\n", max_threads_per_multiprocessor);int max_blocks_per_multiprocessor;cudaDeviceGetAttribute(&max_blocks_per_multiprocessor, cudaDevAttrMaxBlocksPerMultiProcessor, 0);printf("Maximum blocks per multiprocessor: %d\n", max_blocks_per_multiprocessor);int max_threads;cudaDeviceGetAttribute(&max_threads, cudaDevAttrMaxThreadsPerBlockDim, 0);printf("Maximum threads: %d\n", max_threads);