strimzi operator 部署kafka集群(可外部访问)
Strimzi介绍
官方文档:https://strimzi.io/docs/operators/0.42.0/overview#kafka-components_str
Strimzi介绍 Strimzi 是一个用于 Apache Kafka 在 Kubernetes 上部署和管理的开源项目。它提供了一组 Kubernetes 自定义资源定义(Custom Resource Definitions,CRDs)、控制器和操作符,使得在 Kubernetes 环境中轻松地部署、管理和操作 Kafka 集群成为可能。Strimzi 项目旨在简化 Kafka 在 Kubernetes 上的部署和运维,同时利用 Kubernetes 的优势,如弹性、可扩展性和自动化。
以下是 Strimzi 的一些关键特性和优势:
Kubernetes原生支持: Strimzi 利用 Kubernetes 的原生资源和概念,如Pods、Services、PersistentVolumeClaims(PVCs)等,使得 Kafka 集群的部署和管理与 Kubernetes 中其他应用程序类似。
自定义资源定义(CRDs): Strimzi 提供了一组自定义资源定义(CRDs),用于描述 Kafka 集群、主题、用户等 Kafka 相关的资源,使得用户可以通过 Kubernetes API 对其进行管理。
多种部署选项: Strimzi 支持多种部署模式,包括单节点、多节点、高可用、多集群等,可以根据需求选择合适的部署模式。
集成安全性: Strimzi 支持 Kafka 的安全功能,包括TLS/SSL加密、身份认证、授权等,以确保 Kafka 集群的安全性。
自动化运维: Strimzi 提供了一组控制器和操作符,可以自动化 Kafka 集群的运维任务,如扩展、备份、升级等,减少了运维人员的工作量。
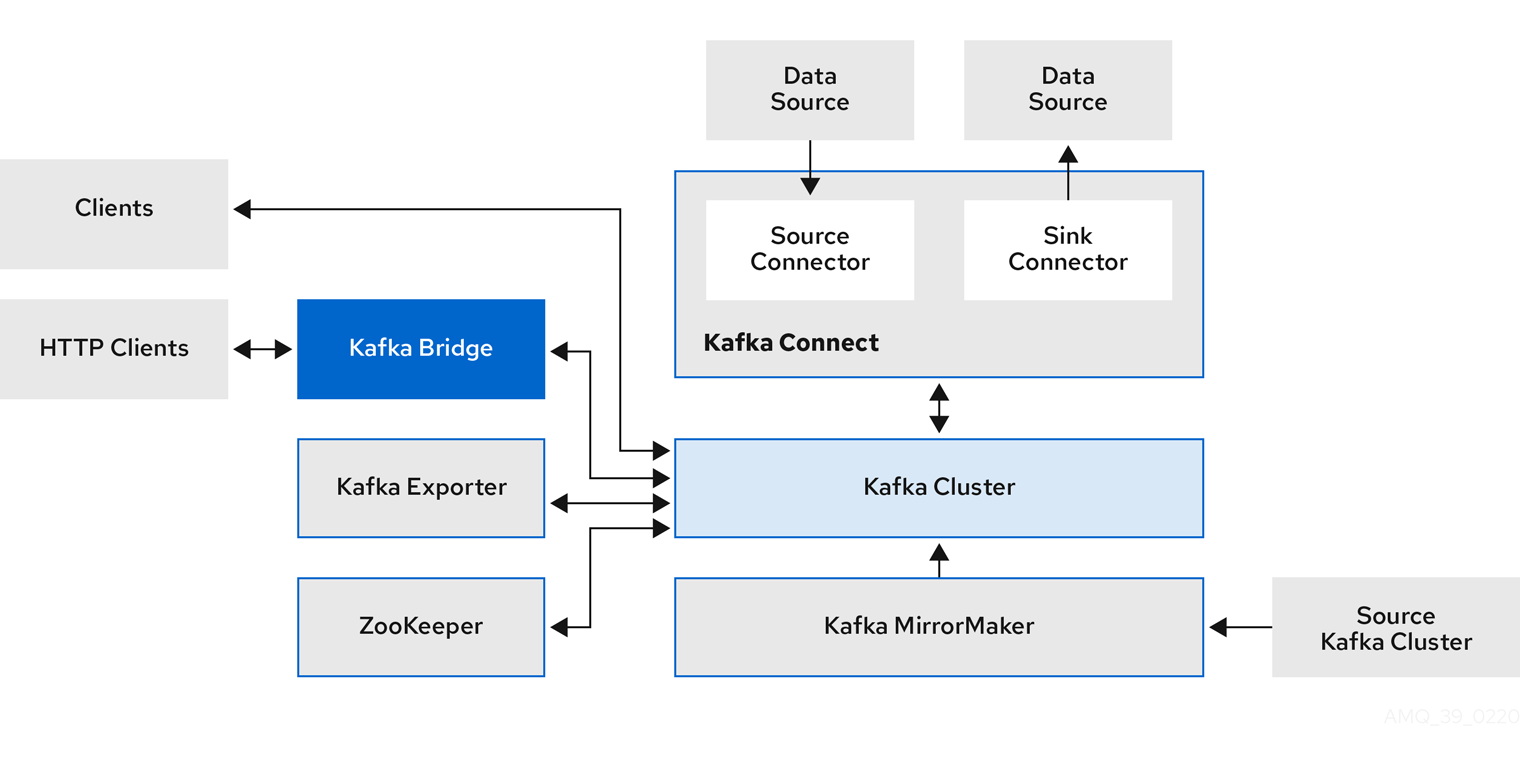
Kafka 组件架构
Apache Kafka 组件可通过 Strimzi 发行版部署到 Kubernetes。Kafka 组件通常以集群形式运行,以确保可用性。
包含 Kafka 组件的典型部署可能包括:
- Kafka代理节点集群
- 复制的 ZooKeeper 实例的ZooKeeper集群
- Kafka Connect集群用于外部数据连接
- Kafka MirrorMaker集群用于在辅助集群中镜像 Kafka 集群
- Kafka Exporter提取额外的 Kafka 指标数据用于监控
- Kafka Bridge向 Kafka 集群发出基于 HTTP 的请求
- Cruise Control用于在代理节点之间重新平衡主题分区
虽然这些组件并非全部都是必需的,但您至少需要 Kafka 和 ZooKeeper。有些组件可以在没有 Kafka 的情况下部署,例如 MirrorMaker 或 Kafka Connect。
- Kafka 集群由负责消息传递的代理组成。
- ZooKeeper 用于集群管理。在 KRaft(Kafka Raft 元数据)模式下部署 Kafka 时,通过在 Kafka 节点内集成代理和控制器角色,集群管理得到简化,无需 ZooKeeper。Kafka 节点承担代理、控制器或两者的角色。在 Strimzi 中使用节点池配置角色。
其他每个 Kafka 组件都与 Kafka 集群交互以执行特定的角色。
Kafka 组件交互
-
Apache ZooKeeper
Apache ZooKeeper 提供集群协调服务,存储和跟踪代理和消费者的状态。ZooKeeper 还用于控制器选举。如果使用 ZooKeeper,则在运行 Kafka 之前必须准备好 ZooKeeper 集群。在 KRaft 模式下,ZooKeeper 不是必需的,因为协调由 Kafka 集群中作为控制器运行的 Kafka 节点管理。 -
Kafka Connect
Kafka Connect 是一个集成工具包,用于使用连接器插件在 Kafka 代理和其他系统之间传输数据。Kafka Connect 提供了一个框架,用于将 Kafka 与外部数据源或目标(例如数据库)集成,以便使用连接器导入或导出数据。连接器是提供所需连接配置的插件。 -
源连接器将外部数据推送到 Kafka。
-
接收器连接器从 Kafka 中提取数据
外部数据被翻译并转换成适当的格式。
您可以通过配置来部署 Kafka Connect build,该配置会自动构建包含数据连接所需连接器插件的容器映像。 -
Kafka MirrorMaker
Kafka MirrorMaker 在两个 Kafka 集群之间(在数据中心内或跨数据中心)复制数据。
MirrorMaker 从源 Kafka 集群获取消息并将其写入目标 Kafka 集群。 -
Kafka桥
Kafka Bridge 提供了用于将基于 HTTP 的客户端与 Kafka 集群集成的 API。 -
Kafka Exporter
Kafka Exporter 提取数据作为 Prometheus 指标进行分析,主要是与偏移量、消费者组、消费者滞后和主题相关的数据。消费者滞后是指写入分区的最后一条消息与消费者当前从该分区获取消息之间的延迟
Strimzi operators
官方文档:https://strimzi.io/docs/operators/latest/deploying#assembly-operators-str
Strimzi operators 专门设计了专业的操作知识,以有效管理 Kubernetes 上的 Kafka。每个操作员都执行不同的功能。
Cluster Operator
Cluster Operator 负责在 Kubernetes 上部署和管理 Apache Kafka 集群。它可自动设置 Kafka 代理以及其他 Kafka 组件和资源。
Topic Operator
Topic Operator 管理 Kafka 集群内主题的创建、配置和删除。
User Operator
User Operator 管理需要访问 Kafka 代理的 Kafka 用户。
部署 Strimzi 时,首先要部署 Cluster Operator。然后,Cluster Operator 即可处理 Kafka 的部署。您还可以使用 Cluster Operator(推荐)或作为独立操作员部署 Topic Operator 和 User Operator。您可以将独立操作员与不受 Cluster Operator 管理的 Kafka 集群一起使用。
Topic Operator 和 User Operator 是 Entity Operator 的一部分。Cluster Operator 可以根据 Entity Operator 的配置部署其中一个或者两个 Operator。
部署 Cluster Operator
认识Cluster Operator
- Strimzi的Cluster Operator是一个自定义的Kubernetes操作符,用于管理和运行Kafka集群。
- 它是Strimzi的核心组件之一,负责监视Kafka集群的运行状态、处理集群级别的配置变更、创建、删除和更新Kafka集群资源等。
- Cluster Operator可以自动化部署、升级和维护Kafka集群,使得Kafka集群可以自动化、高效地运行在Kubernetes中。
- 主要用途是将Kafka和Kubernetes整合在一起,提供了一种简单、可扩展且可靠的方式来管理Kafka集群。
Kafka集群、Topic Operator、User Operator
为了能够使用 Cluster Operator 管理 Kafka 集群,您必须将其部署为 Kafka 资源。 Strimzi 提供了示例部署文件来执行此操作。您可以使用这些文件同时部署 Topic Operator 和 User Operator。
部署 Cluster Operator 后,使用 Kafka 资源部署以下组件:
- Kafka集群
- Topic Operator
- User Operator
在安装 Kafka 时,Strimzi 还安装了 ZooKeeper 集群,并添加了连接 Kafka 和 ZooKeeper 所需的配置。
如果您尚未将 Kafka 集群部署为 Kafka 资源,则无法使用 Cluster Operator 对其进行管理。例如,这适用于在 Kubernetes 外部运行的 Kafka 集群。但是,您可以将 Topic Operator 和 User Operator 与不受 Strimzi 管理的 Kafka 集群一起使用,方法是将它们部署为独立组件。您还可以在非 Strimzi 管理的 Kafka 集群中部署和使用其他 Kafka 组件。
部署 Cluster Operator 以监视所有命名空间
官方文档: https://strimzi.io/quickstarts/
此过程演示如何部署 Cluster Operator 以监视 Kubernetes 集群中所有命名空间中的 Strimzi 资源。
在此模式下运行时,Cluster Operator 会自动管理创建的任何新命名空间中的集群。
创建一个名为 kafka 的命名空间
kubectl create namespace kafka
获取项目代码
# 使用默认的 main 分支即可
git clone https://github.com/strimzi/strimzi-kafka-operator.git
cd strimzi-kafka-operator
配置RBAC
先决条件
- 您需要一个有权创建和管理 CustomResourceDefinition 和 RBAC(ClusterRole 和 RoleBinding)资源的帐户。
修改RoleBinding文件
sed -i 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
编辑 install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml 文件
<