用户画像系列——Spark任务调优实践
在画像标签的加工和写入hbase中,我们采用了spark来快速进行处理和写入。但是在实际线上运行的过程中,仍然遇到了不少问题,下面来总结下遇到的一些问题
1.数据倾斜问题
其实spark 数据倾斜思路和hive、mapreduce 数据倾斜思路处理类似,先看运行的任务,找到spark监控,active job -> stage -> task, 最终我们就能找到运行的task,可以看一些运行时长远超其他的task,同时处理的数据量也远超其他task,这种情况就是有数据倾斜了。
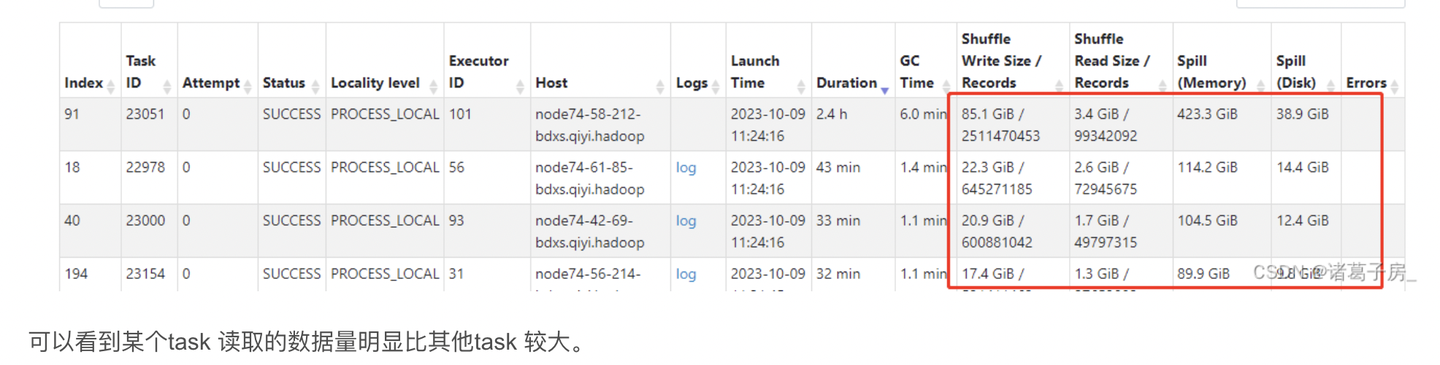
然后我们就可以对我们自己的数据进行分析:

可以很明显的看到前两条数据要比后面的其他数据量级要大,因此可以看出来存在数据倾斜。
数据倾斜的思路也是比较简单:
(1)可以在id前加随机前缀,先统计一次,然后去掉前缀再统计,这样就能解决数据倾斜问题了。
(2)或者有一些认为这种数据是脏数据可以直接过滤,丢弃掉也可以,需要根据业务场景进行判断。
2.任务处理很慢
一般这种情况,需要我们去看我们运行慢的任务,如果不存在数据倾斜问题,那就需要去分析运行的jstack 堆栈信息。(多观察刷新几次 观察堆栈信息,看看是不是一直在执行某个方法,说明一直在这里执行)

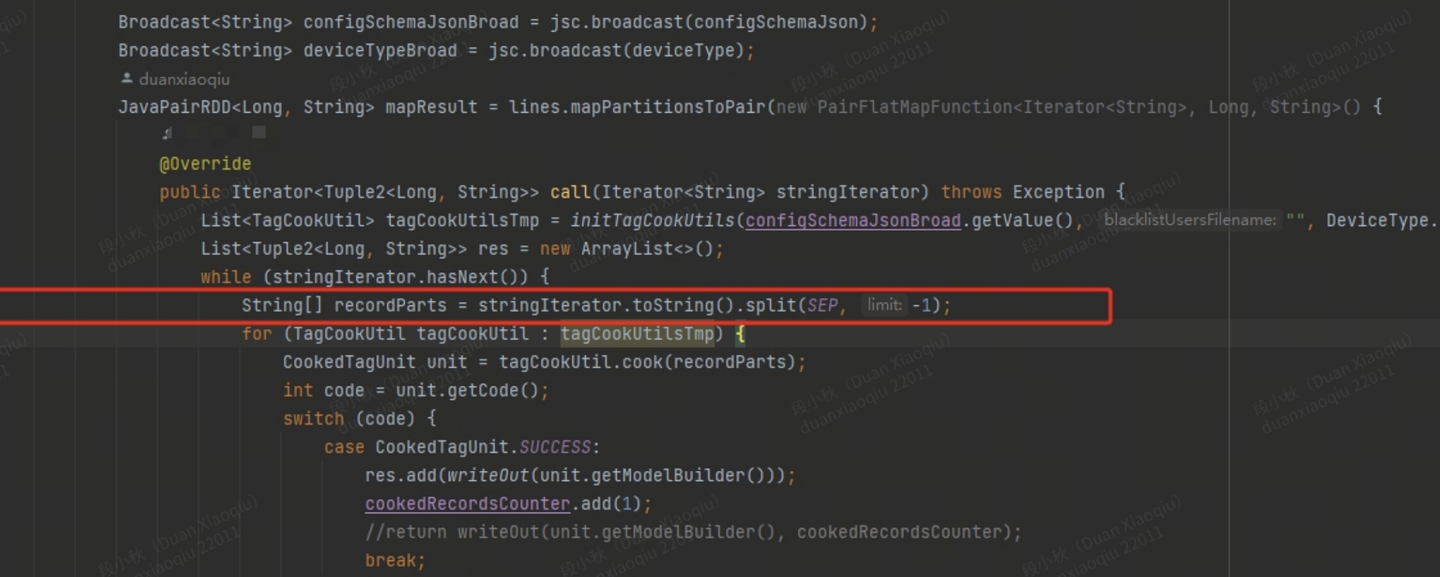
之前遇到代码死循环(这个明显是代码写错了),一直卡在某个方法里出不来,也是通过查看堆栈信息发现的。
再有的优化手段:textfile 格式 优化成 parquet 格式(parquet格式⽀持⾃动split,当单个文件过大时spark读进来之后可以支持自动split),但是texfile是不支持的。
3.spark oom 问题
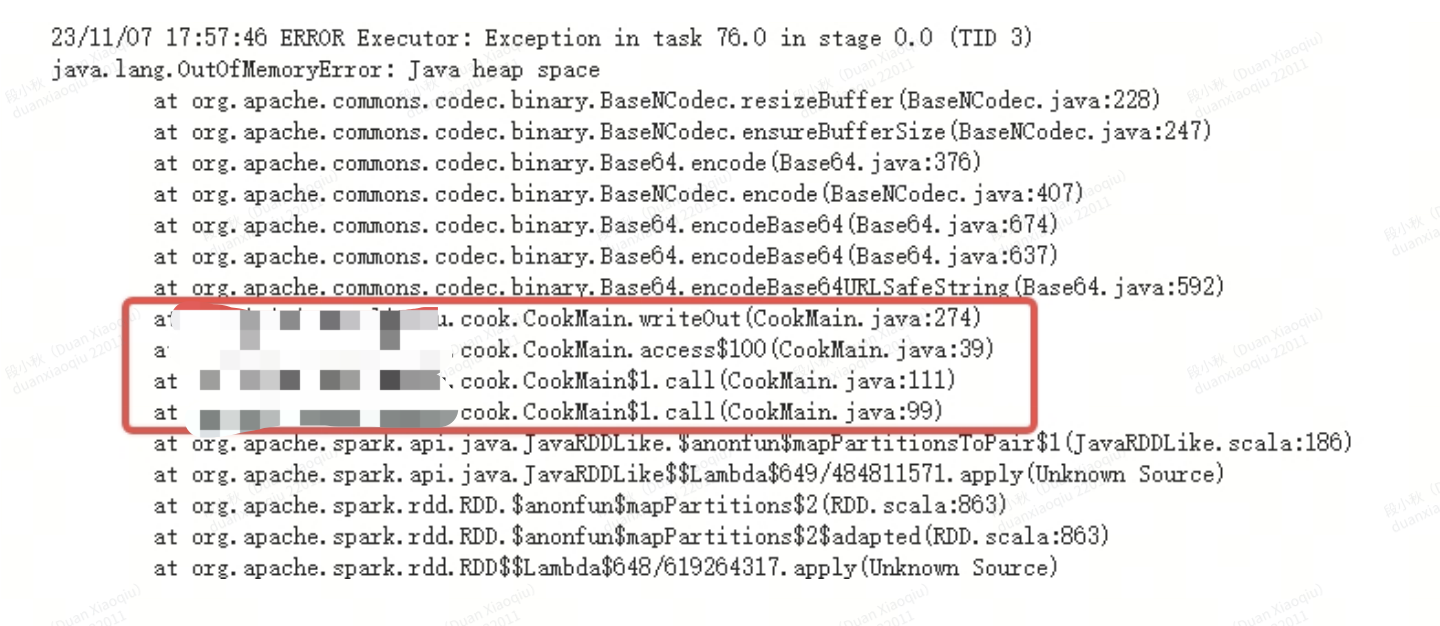
(1)driver 端 oom:spark collect 把大数据拉到了driver 端
(2)excutor 端 oom: mapPartitions 提供给了我们更加强大的数据控制力,怎么理解呢?我们可以一次拿到一个分区的数据,那么我们就可以对一个分区的数据进行统一处理,会加大内存的开销,可能会导致 oom 问题也是需要注意的
当然大家,也可以继续看看前面写的用户画像系列文章