深度学习应用技巧总结与pytorch框架下训练过程的记忆技巧
大家好,我是微学AI,今天给大家总结一下深度学习模型训练过程中的一些技巧总结,以及pytorch框架下训练过程的记忆技巧,很有用的干货,理解模型训练过程的步骤,让流程难懂,难记忆的过程变得简单,让你成为深度学习领域的大神。
一、深度学习应用技巧总结与记忆技巧
我把深度学习应用技巧比喻成种值优质的果实。
训练数据预处理:数据可以说是深度学习的“种子”,这个是模型训练的第一步。没有数据是训练不出模型的。数据预处理是深度学习中非常重要的一个环节。通过对数据进行归一化、标准化、缺失值填充等操作,可以有效地减小训练误差,并提高模型的泛化能力。
特征工程:特征工程相当于在众多的种子中选择特等有优势的种子。特征工程是将原始数据转换成适合于机器学习算法输入的特征向量的过程。在深度学习中,卷积神经网络(CNN)、循环神经网络(RNN)等模型通常需要从原始数据中提取出特征。通过优秀的特征工程,可以提高模型的性能和精度。
模型选择:模型选择相当于选择合适的土壤来种植种子,正所谓橘生淮南则为橘生于淮北则为枳,只有合适的土壤环境才能种出好果实。模型选择是针对不同的任务,有不同的深度学习模型可以选择。例如,对于图像分类问题,可以使用经典的卷积神经网络(如LeNet、AlexNet、VGG、GoogLeNet、ResNet等);对于序列建模任务,可以采用循环神经网络、长短时记忆网络(LSTM)、门控循环单元(GRU)等模型。
超参数调优:超参数调优相当于调试不同的肥料,帮助果实长的又大又甜。深度学习模型存在大量的超参数,包括学习率、批量大小、迭代次数、正则化项系数等。这些超参数的设置会影响到模型的训练效果和性能。因此,需要通过实验来优化超参数。
模型集成:模型集成相当于多种植技术综合来用于果实的发育。深度学习中,通常使用集成学习方法来提高模型的性能。比如,Bagging、Boosting和Stacking等方法可以将多个训练好的基础模型进行组合,得到更加优秀的集成模型。
优化算法:优化算法相当于因时因地进行灌溉,优化灌溉次数与范围。深度学习模型的训练过程通常采用梯度下降法,但是不同的梯度下降算法可能导致不同的收敛速度和局部最优解。因此,需要选择合适的优化算法,例如Adam、RMSProp等。
二、PyTorch框架模型训练过程
关于在PyTorch框架下快速记忆模型训练过程,可以按照以下步骤进行:
数据加载:首先需要将数据集加载到内存中,可以使用PyTorch提供的DataLoader类来实现。在数据加载时需要指定批次大小、数据增强等参数。
模型定义:在模型定义阶段需要选择合适的模型架构,并对其进行初始化。可以使用PyTorch提供的nn.Module类来定义模型。
损失函数定义:在模型训练过程中需要定义损失函数。通常情况下,分类问题可以采用交叉熵损失函数,回归问题可以采用均方误差损失函数等。
优化器定义:优化器用于更新模型参数以最小化损失函数。常用的优化器包括SGD、Adam等。在PyTorch中可以直接调用torch.optim中的优化器类。
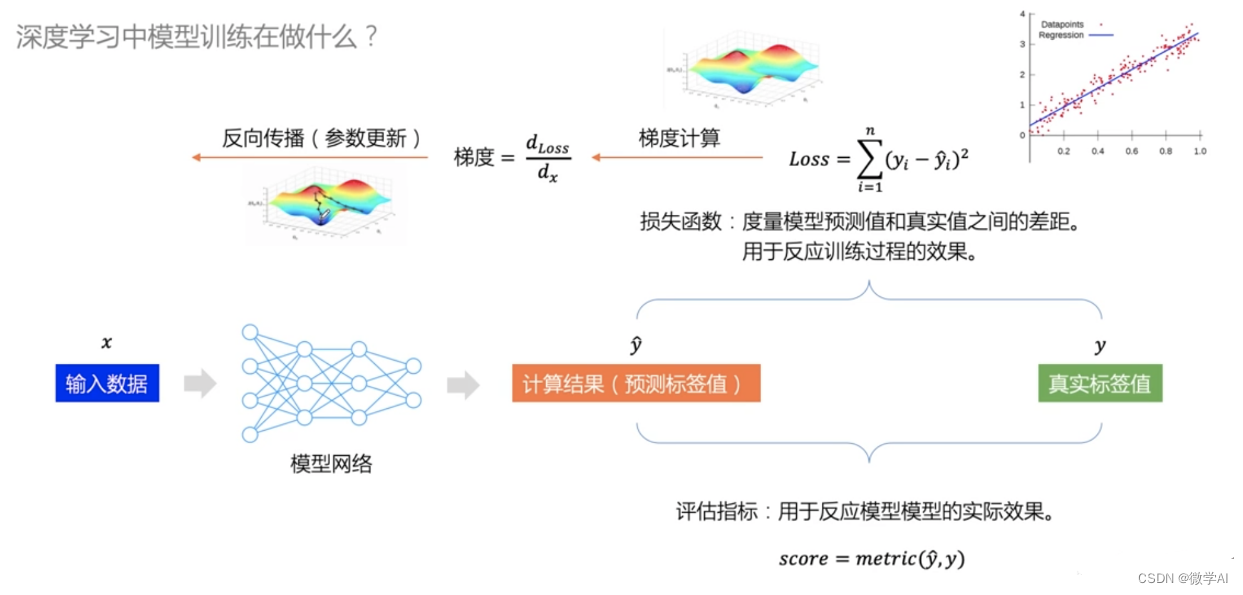
训练模型:训练模型的核心部分是迭代过程,通常使用一个for循环来控制迭代次数。每迭代一次,需要完成以下几个步骤:
-
将数据输入模型并得到输出;inputs, labels = data[0], data[1],outputs = net(inputs)
-
计算损失函数值;loss = criterion(outputs, labels)
-
清空上一步计算的梯度信息;optimizer.zero_grad()
-
反向传播得到梯度信息;loss.backward()
-
使用优化器更新模型参数;optimizer.step()
-
记录训练过程中的指标(如loss、accuracy等):print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
模型评估:在模型训练完成后需要对模型进行评估,通常可以使用测试集或验证集来进行模型性能评估。
模型保存:训练完成后可以将模型参数保存到本地,以便后续使用。可以使用torch.save方法将模型参数保存到文件中。
 可以通过多次实践和总结来快速记忆和掌握这些步骤。同时还要不断地深入学习和探索PyTorch框架的其他特性和应用场景,以提高深度学习训练的效率和精度。
可以通过多次实践和总结来快速记忆和掌握这些步骤。同时还要不断地深入学习和探索PyTorch框架的其他特性和应用场景,以提高深度学习训练的效率和精度。
需要代码辅导,接单,合作的可私信。
往期作品:
深度学习实战项目
1.深度学习实战1-(keras框架)企业数据分析与预测
2.深度学习实战2-(keras框架)企业信用评级与预测
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
7.深度学习实战7-电商产品评论的情感分析
8.深度学习实战8-生活照片转化漫画照片应用
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
...(待更新)