【基于协同过滤算法的推荐系统项目实战-2】了解协同过滤推荐系统
本文目录
- 1、推荐系统的关键元素
- 1.1 数据
- 1.2 算法
- 1.3 业务领域
- 1.4 展示信息
- 2、推荐算法的主要分类
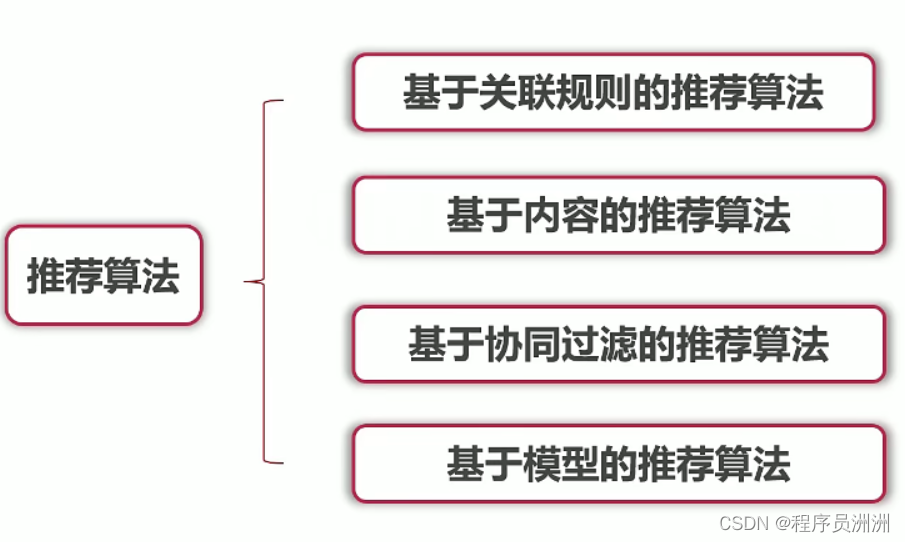
- 2.1 基于关联规则的推荐算法
- 基于Apriori的算法
- 基于FP-Growth的算法
- 2.2 基于内容的推荐算法
- 2.3 基于协同过滤的推荐算法
- 3、推荐系统常见的问题
- 1、冷启动
- 2、数据稀疏
- 3、不断变化的用户喜好
- 4、推荐系统效果评测
- 4.2 模型离线实验
- 4.2 用户A\B Test在线实验
1、推荐系统的关键元素
1.1 数据
数据是整个推荐系统的基石,我们需要对数据进行清洗和预处理。
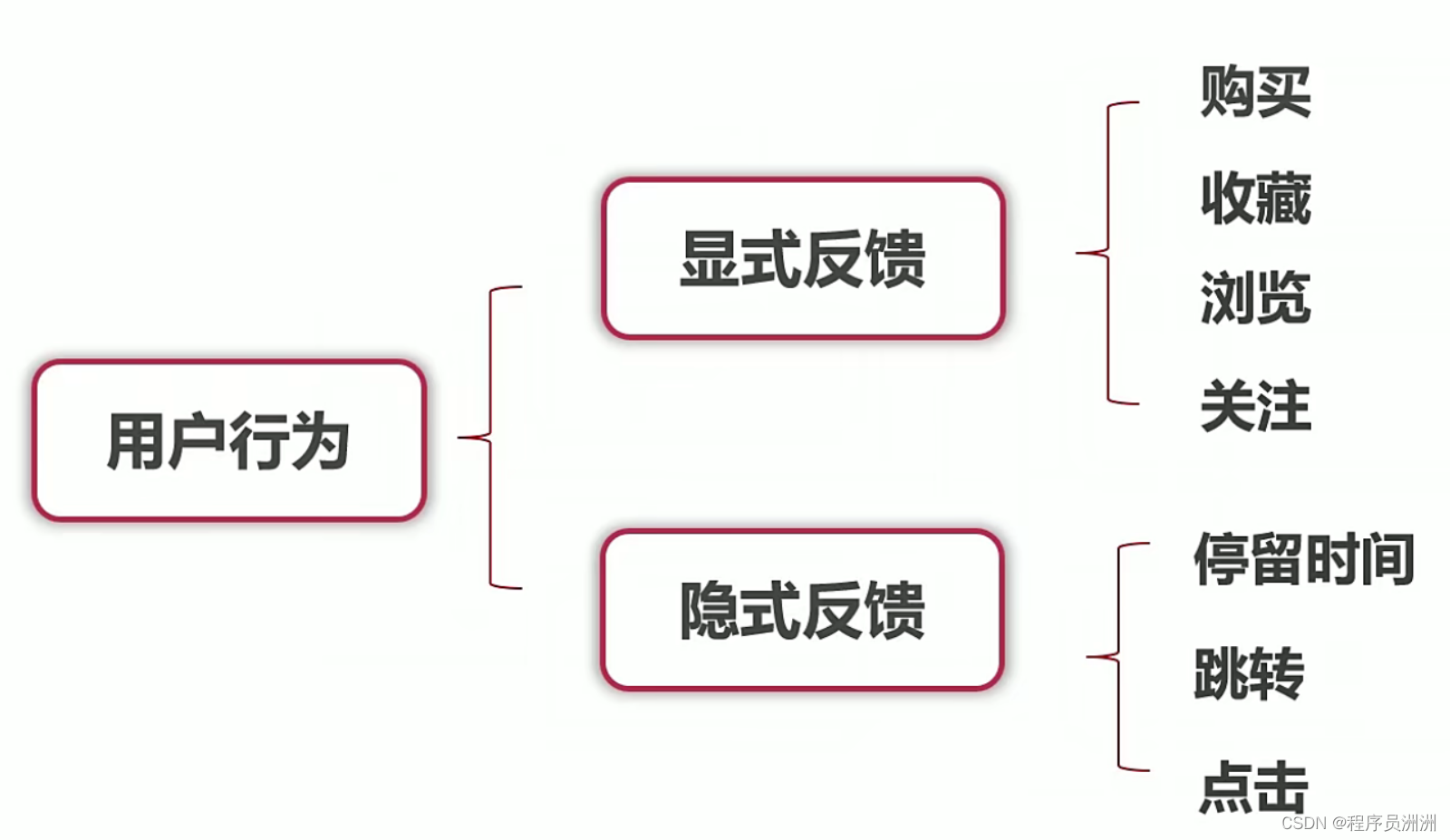
用户行为能够真实的反映每个用户的偏好和习惯,其中的显示反馈数据会比较稀疏,隐式的反馈数据蕴含了大量的信息。
1.2 算法
基于流行度的推荐算法:是基于PV、UV来进行推荐,没有个性推荐。
基于协同过滤的推荐算法:是目前比较主流的一个推荐算法。
基于内容的推荐算法:是通过打标签进行推荐的,可以基于特征向量对内容自动打标签。(以前是人工打标签,现在可以自动打标签了)
基于模型的推荐算法:解决协同过滤算法的数据稀疏性的问题。
1.3 业务领域
不同的领域,不同的行业都会有自己的知识体系,所以泛化的一些推荐系统是无法满足具体领域中的特定的用户需求,所以需要结合知识去特定一些推荐系统。
例如在:
金融领域是基于风险偏好的个性化推荐方法。
社交领域是基于社交信息的用户行为挖掘方法。
电商领域是基于情境感知的个性化偏好的挖掘方法。
1.4 展示信息
可以理解为展示UI,也就是前端数据可视化,你需要把什么样的信息、哪些信息展示给用户,才能做到吸引,高质量的吸引是重要的, 不能过于繁杂,也不能过于少, 要精准。
2、推荐算法的主要分类
2.1 基于关联规则的推荐算法
应用场景:购物篮分析。
通过放入购物篮的不同商品之间的联系,分析顾客的购物习惯。
基于Apriori的算法
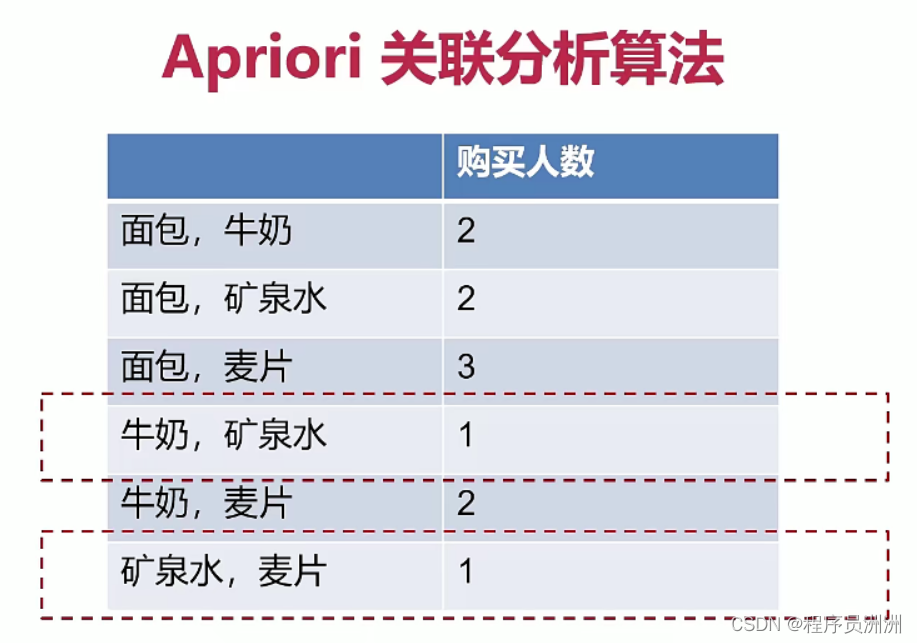
Aparior是无监督学习算法,挖掘一堆数据集中的数据之间的某种关联。但是会存在一些明显的缺点,如数据集很大的时候,运行效率很低。
假设有四种单品,那如果两两组合,那少于某个特定值的就会淘汰,这个特定值叫做 支持度。只有当支持度大于某个特定值的时候,才能认为是有效的。
基于FP-Growth的算法
FP-Growth不产生候选集。另外只需要扫描2次数据集,这是和Apriori最大的两个不同点。
2.2 基于内容的推荐算法
简而言之,就是推荐内容相似的物品。
通过打标签tag来找内容相似的物品,也可以通过文本相似度来找内容相似的物品。
通过自然语言挖掘:文本相似度是通过TF-IDF算法来完成的:提取关键词及其TFIDF值,将共同关键词的TFIDF的值的积并求和,然后获取相似度的值。
最后,也能通过分类算法来分类。

2.3 基于协同过滤的推荐算法
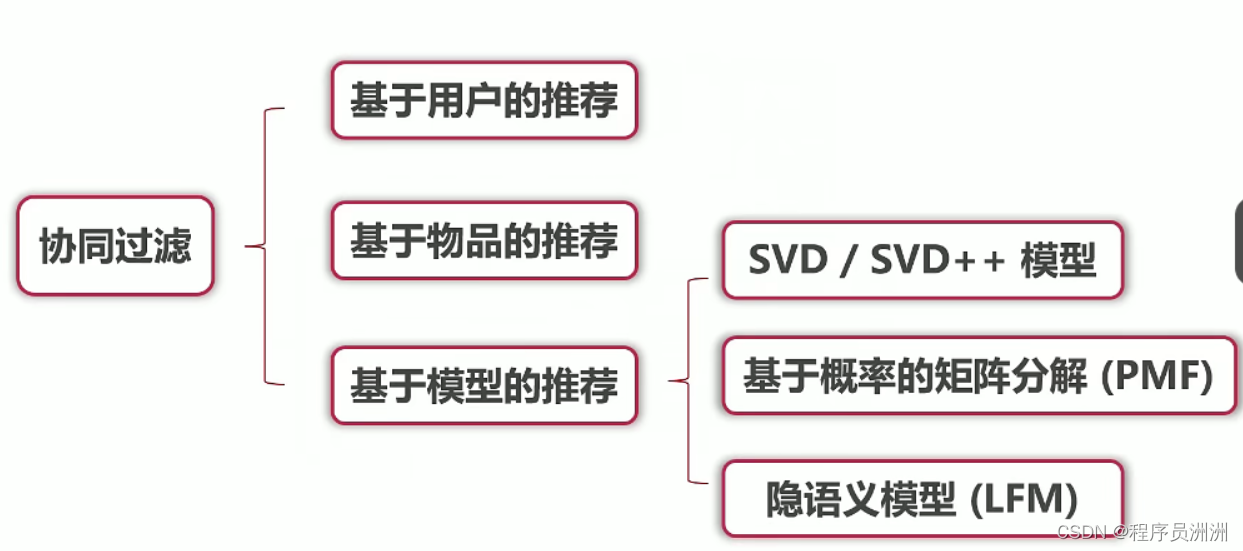
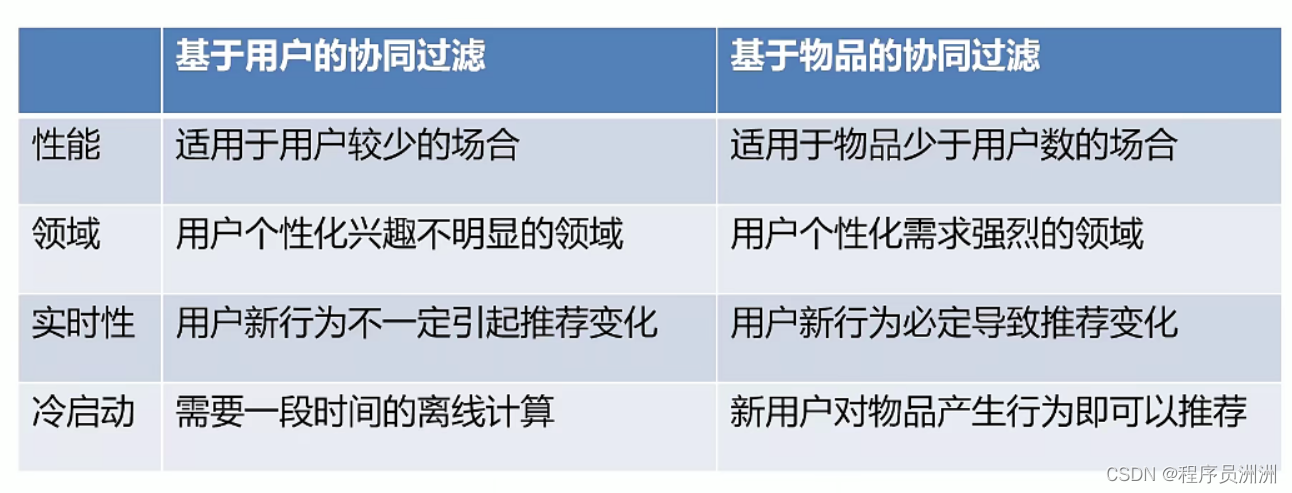
基于用户的协同过滤:是指兴趣相近的用户会对同样的物品感兴趣。
基于物品的协同过滤:是指推荐给用户他们喜欢的物品相似的物品。


协同过滤是为了解决数据稀疏,为此我们进行特征分解,把评分矩阵不全,进行降维。通过奇异值分解来进行特征分解,提出了SVD,但是SVD过于复杂,又提出了PMF。
3、推荐系统常见的问题
1、冷启动
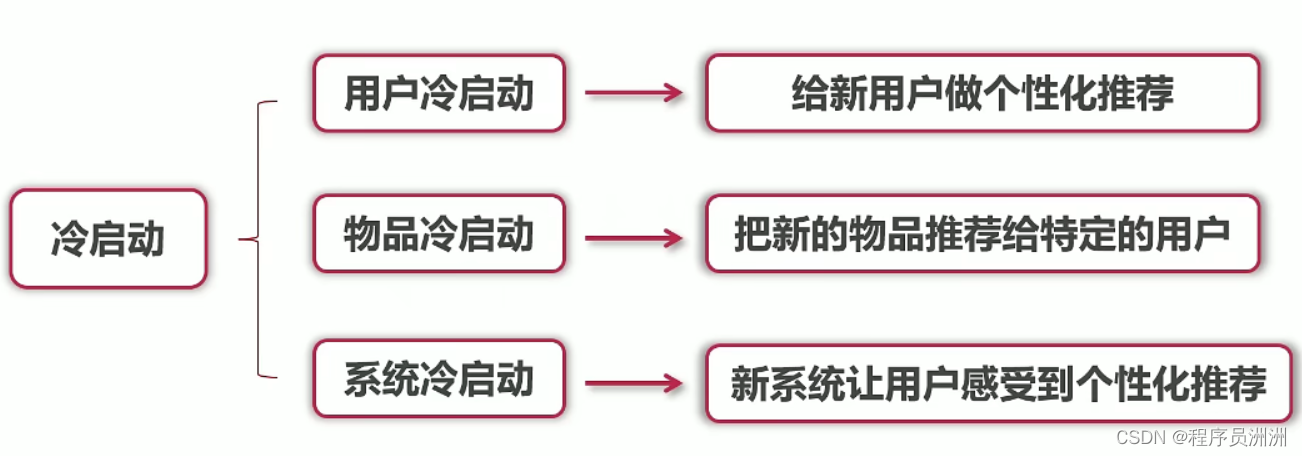
根据用户注册信息对用户进行分类,如手机号运营商、邮箱等等可以适当解决用户冷启动。
也可以通过推荐热门的排行榜、基于深度学习的语义模型理解来解决。
所以需要引导用户把自己的属性表达起来。
对于物品冷启动,则需要通过文本分析、主题模型、给物品打标签、排行榜单等来做到。
2、数据稀疏
用户-物品矩阵是稀疏矩阵。其解决方案如下:

但降低维度也会有一定丢失属性。
3、不断变化的用户喜好
需要对用户行为的存储有实时性,另外推荐算法要考虑到用户近期行为和长期行为,并且不断的挖掘用户新的兴趣爱好。
4、推荐系统效果评测
4.2 模型离线实验
1、模型离线实验:将数据集分为训练数据和测试数据集。在训练集上训练推荐模型,在测试集上进行预测。最后通过预定的指标来评测测试集上的预测结果。
模型离线实验是推荐系统中的一个基石,路径短,方便完成闭环以此来完成快速迭代,同时不会影响线上的用户体验。
最大的优点就是无需真实的用户参与。
但最大的缺点也是没有用户数据集真实,无法获得真实的用户关心指标。
4.2 用户A\B Test在线实验