苹果提出RLAIF:轻量级语言模型编写代码
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
代码生成一直是一个充满挑战的领域。随着大型语言模型(LLM)的出现,我们见证了在自然语言理解和生成方面的显著进步。然而,当涉及到代码生成,尤其是在需要正确使用API调用的任务中,即使是先进的LLM也会面临所谓的“幻觉”问题,即生成不切实际或错误的代码片段。
为了解决这一问题,本文介绍了一种基于AI反馈的强化学习(RLAIF)框架,旨在提高轻量级LLM(参数少于1B)在代码生成任务中的表现。
- 论文标题: Applying RLAIF for Code Generation with API-usage in Lightweight LLMs
- 机构: Rochester Institute of Technology, Apple
- 论文链接:https://arxiv.org/pdf/2406.20060.pdf
RLAIF框架介绍
1. RLAIF的概念与发展
Reinforcement Learning from AI Feedback (RLAIF) 是一种新兴的强化学习方法,它利用大型语言模型(LLM)生成的反馈来训练小型模型。这种方法首次由Bai等人在2022年提出,并迅速在多个领域展示了其潜力,例如在减少LLM输出中的伤害、增强文本摘要和数学推理方面。RLAIF通过专门的提示策略从更大的LLM(例如GPT-3.5)中提取AI反馈,并使用这些数据训练奖励模型,以改善小型LLM的表现。
2. 为何选择RLAIF替代传统RLHF
传统的强化学习与人类反馈(RLHF)方法通过整合人类评估来训练模型,以提高模型在复杂任务上的表现。然而,这种技术因高质量人类反馈的需求而成本高昂。RLAIF作为一种替代方案,使用AI反馈代替人类反馈,使得微调过程更具可扩展性。此外,RLAIF能够在资源较少的情况下通过AI反馈显著提高代码生成质量,超越简单微调基线。
3. RLAIF在轻量级LLM中的应用
在本研究中,我们将RLAIF框架应用于轻量级LLM(参数少于1B)的代码生成任务中,特别是在需要正确编写API调用的任务上。我们使用RLAIF微调了GPT-2-large(780M参数),不仅在API调用正确性上与先前的研究相当,还在代码生成性能上有所超越。
方法详解:从大模型获取反馈到训练奖励模型
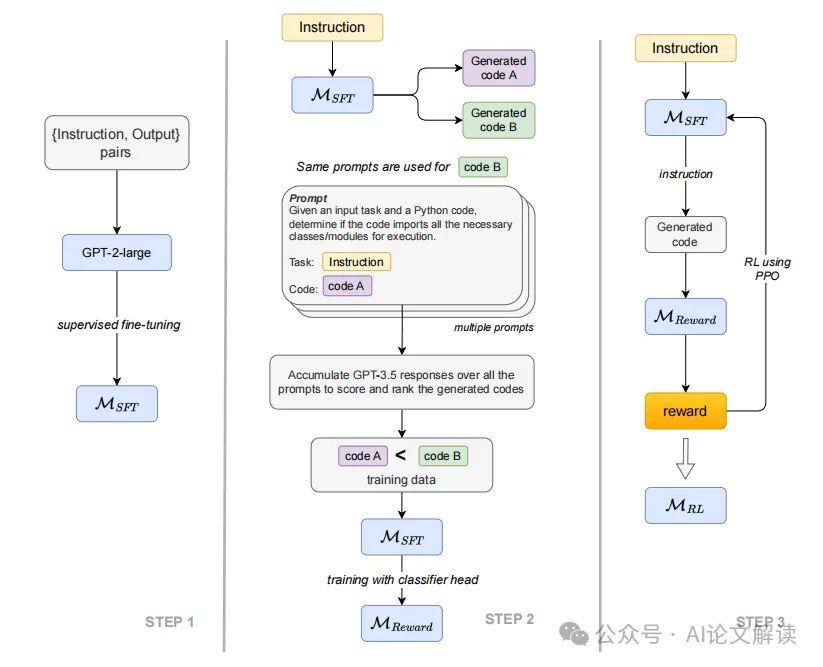
1. 初始模型的微调
我们首先在Gorilla数据集上微调了一个基础模型GPT-2-large,使用了监督式微调技术。这个微调的模型被称为MSFT,为后续的奖励模型训练提供了基础。
2. 使用GPT-3.5生成反馈
为了获取训练奖励模型所需的数据,我们没有采用人类注释员,而是使用了更大的LLM(GPT-3.5)来生成标签。我们设计了一系列问题,通过GPT-3.5对这些问题进行回答,以评估生成代码的质量。这些问题是二元的(是/否),我们根据GPT-3.5的回答计算每个输入-输出对的得分。
3. 奖励模型的训练与应用
使用上述方法获得的得分,我们标记训练数据中的输出(接受或拒绝),并将这些数据用于训练奖励模型Mreward。Mreward的训练目标是分类机器生成的代码是否对给定的输入指令可接受。最后,我们使用近端策略优化(PPO)算法微调MSFT,其中Mreward提供的逻辑分数作为奖励信号,最终得到的微调模型称为MRL。
实验设置:Gorilla数据集的应用
1. 数据集的结构与特点
Gorilla数据集由Patil等人在2023年发布,主要包括三个部分:HuggingFace、TensorFlow和PyTorch。本研究主要关注其中的HuggingFace部分,这是三者中最大的一个,包含超过925个独特的API,涵盖37个不同的领域,如多模态文本到图像、计算机视觉图像分类、音频文本到语音等。每个API都有十个独特的指令。数据集中的每个实例包含一个指令(任务描述)、领域、API调用(单行代码)、解释(如何使用API解决任务)以及完成任务的完整Python脚本。
2. 训练与评估过程
我们的实验使用了GPT-2-large模型(780M参数),通过监督式微调技术对其进行训练。训练过程中,我们没有进行超参数搜索,而是使用了固定的学习率。训练集占数据集的90%,剩余的10%用于评估。我们在NVIDIA A100 40GB GPU集群上进行了实验,总共花费了约60个GPU小时。
实验结果与分析
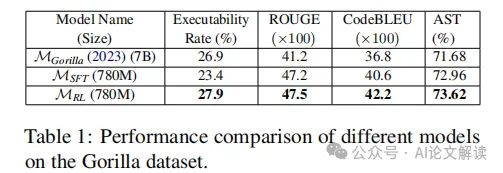
1. 代码生成质量的多指标评估
我们采用了多种指标来评估生成代码的质量,包括ROUGE和Code-BLEU。ROUGE指标是ROUGE-1、ROUGE-2、ROUGE-L和ROUGE-sum的平均值。Code-BLEU则是标准BLEU、加权n-gram匹配(BLEUweight)、语法AST匹配(Matchast)和语义数据流匹配(Matchdf)的加权平均。此外,我们还报告了生成代码的成功执行率(Executability Rate),这是一个衡量代码是否能在隔离环境中正确运行的指标。
2. 轻量级模型与大模型的性能比较
在我们的实验中,经过RLAIF框架训练的轻量级模型(GPT-2-large,780M参数)不仅在API调用的正确性上与Patil等人的LLaMA-7B模型相当,而且在代码生成性能上还有所超越。特别是在代码的可执行率上,轻量级模型比7B参数的大模型高出1.0%。这一结果表明,即使是参数较少的模型,通过AI反馈也能显著提高代码生成的质量。