数据结构概念
文章目录
1. 概念
2. 数据结构和算法的关系
3. 内存
4. 数据的逻辑结构
5. 数据的存储结构
1. 顺序存储结构
2. 链式存储结构
3. 索引存储结构
4. 散列存储结构
6. 数据的运算
1. 概念
定义1(宏观):
数据结构是为了高效访问数据而设计出的一种数据的组织和存储方式。
- 数据结构从宏观角度来看,重点在于如何组织和存储数据,以便我们能够快速、高效地访问和操作数据。
- 比如,在数组这种数据结构中,数据是按顺序存储的,所以可以通过索引快速访问每一个元素。
定义2(微观):
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
- 从微观角度看,数据结构是数据元素之间存在特定关系的集合。
- 比如,在链表中,每个元素(节点)包含一个数据部分和一个指向下一个元素的引用(指针),这种关系使得链表的插入和删除操作非常高效。
简言之,数据结构是带结构的数据元素的集合。其中,“结构”指的是数据元素之间存在的关系。
- 数据结构关注的是对这些数据元素的操作和数据元素之间的关系,而不是关心具体的数据项内容。
- 目的是为了高效的访问数据。
- 数据结构 = 数据对象 + 结构
- 数据对象是具有相同性质的数据元素的集合。
- 结构是数据元素之间的关系构成的结构。
数据结构是一种有效组织和存储数据的方式,通过定义数据元素之间的关系和对数据元素的操作,来实现对数据的高效访问和处理。理解数据结构的定义和特点有助于我们选择合适的数据结构来解决实际问题,并优化程序的性能。
2. 数据结构和算法的关系
-
数据结构是算法的基础:
- 数据结构提供了一种组织和存储数据的方式,而算法是在这些数据结构上执行操作的步骤和方法。
- 良好的数据结构可以使算法更加高效和简洁。
-
算法依赖于数据结构:
- 每种算法的设计和实现都依赖于特定的数据结构。例如,排序算法可能使用数组或链表,搜索算法可能使用树或图。
- 不同的数据结构会影响算法的性能。例如,使用哈希表进行查找操作通常比使用链表快得多。
-
数据结构选择影响算法的效率:
- 选择合适的数据结构可以显著提高算法的效率。例如,使用堆数据结构可以实现高效的优先队列操作,而使用数组则可能效率较低。
- 不同的数据结构有不同的时间和空间复杂度,算法的性能分析通常基于所使用的数据结构的复杂度。
3. 内存
在学习数据结构之前,需要先对内存有一个基本的了解,因为数据结构主要是针对内存中的数据进行操作的。
内存的基本概念
- 内存单元:内存由许多存储单元组成,每个存储单元可以存储一个固定大小的数据块,通常以字节(Byte)为单位。
- 地址:每个存储单元都有一个唯一的地址,操作系统就是根据这个地址去访问内存中的数据。
存储方式
我们讨论的数据结构中的数据元素存储在内存单元中,这些数据元素可以有两种存储方式:

-
连续存储:
- 数据元素存储在相邻的内存单元中。
- 例如,数组中的元素就是按连续的内存地址存储的。
- 优点:可以通过索引快速访问任意元素,访问速度快。
- 缺点:需要一块连续的内存空间,当需要扩展数组时可能需要搬移数据,插入和删除元素的操作比较费时。
-
分散存储:
- 数据元素存储在非连续的内存单元中,每个元素存储单元中还包含一个指向下一个元素的指针。
- 例如,链表中的元素就是按分散的内存地址存储的。
- 优点:内存利用效率高,可以方便地进行插入和删除操作。
- 缺点:访问速度相对较慢,因为需要通过指针逐个访问元素。
理解内存的基本概念和数据元素的存储方式对学习和实现数据结构非常重要。数据结构的性能和效率在很大程度上依赖于数据在内存中的存储方式。通过选择合适的存储方式,可以优化数据结构的操作,如查找、插入、删除等。
4. 数据的逻辑结构
数据元素之间逻辑关系的描述用以下形式表示:
D_S = (D, S)
这里有两个要素:数据元素 D 和 关系 S。其中,关系 S 是指数据元素间的逻辑关系。
根据数据元素间关系的不同特性,可以将数据的逻辑结构分类为以下四种基本类型:
- 集合结构
- 线性结构
- 树形结构
- 图形结构(或网状结构)
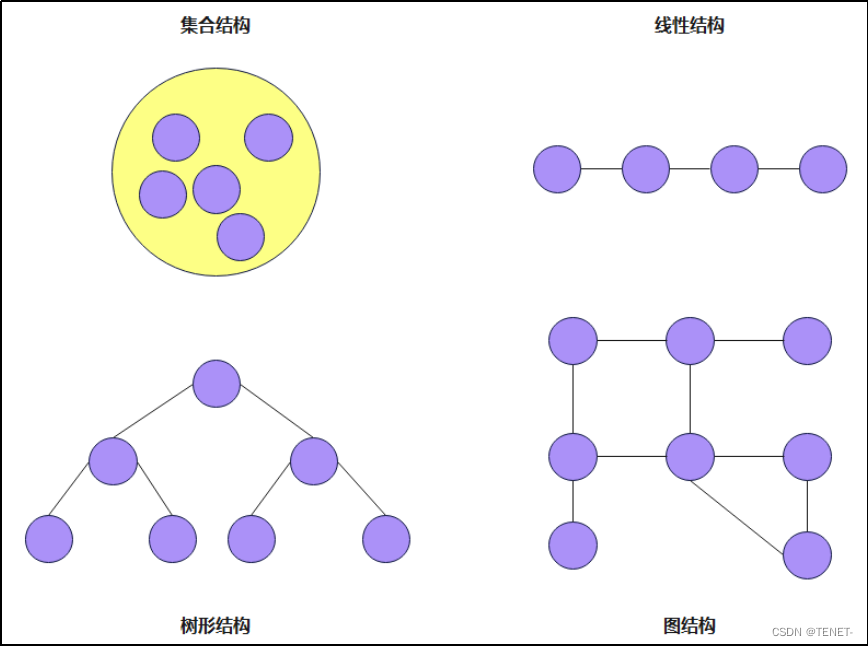
1. 集合结构
- 描述:集合结构中的数据元素除了同属于一个集合外,没有其他关系。
- 示例:一个圆圈内包含多个元素,这些元素之间没有其他关联,只是简单地聚集在一起。
2. 线性结构
- 描述:线性结构中的数据元素存在一对一的关系。
- 示例:一条直线或一条链上的节点,每个元素只有一个前驱和一个后继(第一个元素除外,只有后继;最后一个元素除外,只有前驱)。
3. 树形结构
- 描述:树形结构中的数据元素存在一对多的层次关系。
- 示例:一个树形图,顶点表示数据元素,边表示数据元素之间的关系。树形结构有一个根节点,每个节点可以有多个子节点,但每个子节点只有一个父节点。
4. 图形结构(或网状结构)
- 描述:图形结构中的数据元素存在多对多的关系。
- 示例:一个图形或网络,每个节点可以与多个其他节点连接,表示复杂的关系。图结构可以是有向图或无向图,表示不同的关系方向。
因为线性结构比较突出,所以又将逻辑结构分为:线性结构和非线性结构。
1. 线性结构
- 定义:线性结构中的数据元素按顺序排列,存在一对一的相互关系。
- 特点:每个元素有唯一的前驱和后继(第一个元素除外,只有后继;最后一个元素除外,只有前驱)。
- 示例:
- 顺序表:数组是一种典型的顺序表,数据元素按连续的内存地址排列。
- 链表:元素通过指针链接,形成一个线性链条。
- 栈:后进先出(LIFO)的数据结构,元素按顺序存取。
- 队列:先进先出(FIFO)的数据结构,元素按顺序存取。
- 字符串:字符按顺序排列形成的线性结构。
- 数组:固定大小的线性结构,支持随机访问。
- 广义表:一种递归定义的线性结构,元素可以是原子或子表。
2. 非线性结构
- 定义:非线性结构中的数据元素不按顺序排列,存在多对多的相互关系。
- 特点:数据元素之间的关系更加复杂,不再按线性顺序排列。
- 示例:
- 集合结构:数据元素除了同属于一个集合外,没有其他关系。
- 树结构:层次结构,每个节点可以有多个子节点,但只有一个父节点。
- 图结构:顶点和边组成的复杂网络,每个顶点可以与多个顶点相连。
5. 数据的存储结构
数据的存储结构,又称为物理结构,是数据的逻辑结构在计算机中的表示(或映像)。它包含数据元素的表示和关系的表示(即逻辑关系)。数据的存储结构依赖于计算机语言的实现。为了合理利用计算机的存储空间,研究出了两种基本的存储方式:
1. 顺序存储结构
定义:顺序存储结构把逻辑上相邻的数据元素存储在物理位置上也相邻的存储单元中,即所有的元素依次存放在一片连续的存储空间中。
- 在C语言中:使用一维数组表示顺序存储结构。
- 优点:数据元素存放的地址是连续的,支持下标访问,计算机能够随机存取表中的元素。
- 缺点:插入和删除操作需要移动大量元素,不适合频繁的插入和删除操作。
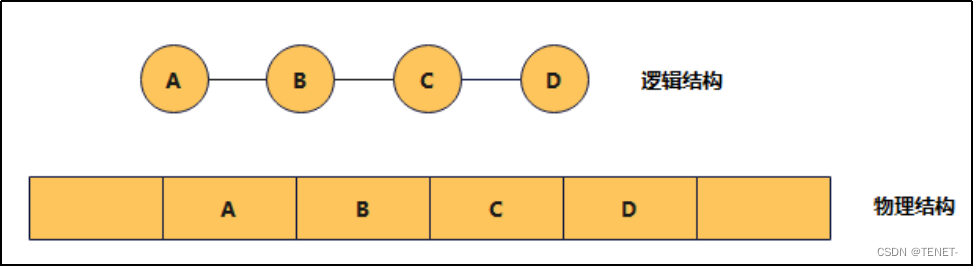
- 逻辑结构:如图中的A、B、C、D四个元素按顺序排列。
- 物理结构:这些元素在内存中也是连续存储的,每个元素占据一个连续的内存位置。
顺序存储结构的具体实现
- 数组:顺序存储结构的最常见形式是数组。在数组中,所有元素按顺序排列,每个元素占据连续的内存位置。
- 优点详细解释:
- 高效访问:因为存储空间是连续的,所以可以通过下标快速访问任意元素。
- 内存局部性:顺序存储结构利用了内存的局部性原理,访问一个元素时,相邻元素很可能也会被访问,从而提高缓存命中率。
- 缺点详细解释:
- 插入和删除操作效率低:在数组中间插入或删除元素,需要移动大量元素,以保证数据的连续性。这对于长数组来说,开销很大。
- 扩展困难:如果数组需要扩展(例如存储的元素超过了数组的容量),通常需要分配一块更大的连续内存空间,并将所有元素复制到新的空间中,这也会带来性能开销。
使用场景
- 适用于:元素数量相对固定、插入和删除操作较少的情况。例如,用于实现查找表、常量数组等。
- 不适用于:需要频繁插入和删除操作的场景。例如,实时数据处理、动态列表等。
2. 链式存储结构
定义: 链式存储结构把逻辑上相邻的数据元素存储在物理位置上不相邻的存储空间中。每个数据元素构造一个结点(用结构体类型表示),结点中除了存放数据本身以外,还存放指向下一个结点的指针(pointer)。
在C语言中用指针来表示数据元素之间的这种结构。

- 链表结点A:包含数据域(data)和指针域(next),指向下一个结点。
- 下一个结点:也包含数据域和指针域,以此类推,直到最后一个结点,其指针域指向NULL,表示链表的结束。

- 逻辑结构:A -> B -> C -> D,表示链表中数据元素的顺序关系。
- 物理结构:内存中的存储位置是非连续的,但通过指针链接每个结点,形成逻辑上的顺序。
优点:
- 灵活性:克服顺序存储结构中预知元素个数的缺点,插入、删除操作灵活,不需要移动元素,只需改变指针。
- 空间利用率高:无需预先分配连续空间,内存利用率高。
缺点:
- 额外空间:需要额外的空间来存储指针,每个结点都由数据域和指针域组成,整体占用的内存较多。
- 访问效率:无法随机访问元素,必须从头开始逐个遍历,访问效率较低。
3. 索引存储结构
索引存储结构类似于书的目录,通过创建数据元素的目录,可以快速检索数据。索引在存储数据元素的同时,还创建了数据元素的目录,便于快速查找。
索引存储结构的特点
- 优点:利用节点的索引号来确定结点的存储地址,检索速度快。比如在MySQL数据库中,通过索引可以快速找到需要的数据。
- 缺点:增加了附加的索引表,会占用较多的存储空间。此外,插入和删除数据时需要修改索引表,因此操作开销较大。
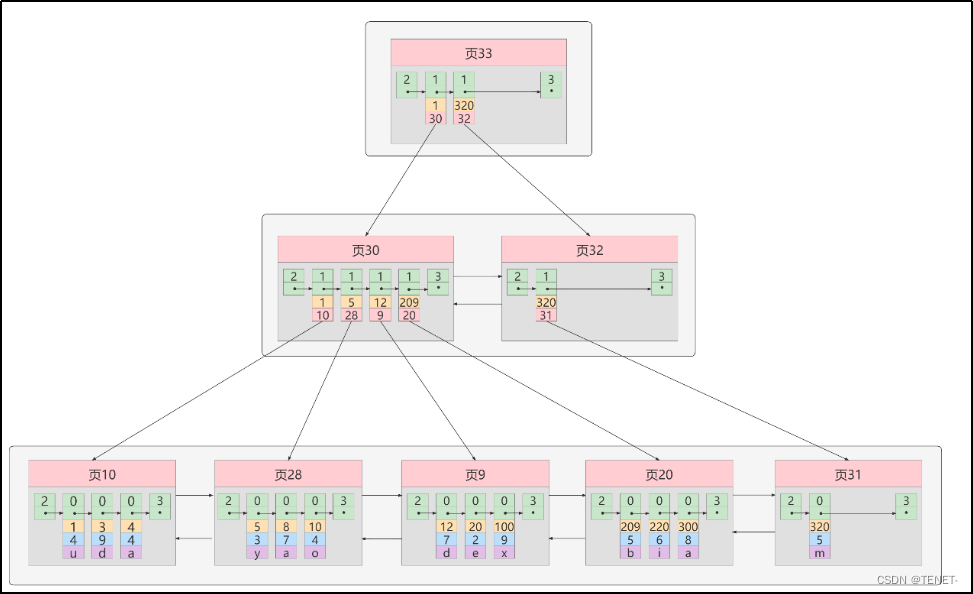
图示中展示了一个多级索引结构,通过不同层次的索引页指向数据页:
- 顶部索引页(页33):包含指向下一级索引页的指针,帮助快速定位到下一级索引页。
- 中间索引页(页30、页32等):包含指向底层数据页的指针,进一步缩小搜索范围。
- 底层数据页(页10、页28、页9等):实际存储数据的页,每个页包含数据记录。
4. 散列存储结构
散列存储结构根据数据元素的关键字直接计算出该元素的关键码,由关键码决定其存储地址。这种方法称为哈希存储(Hash Storage)。我们通过一个哈希函数(Hash Function)将数据元素的关键字映射到存储位置。
散列存储结构的工作原理
-
关键码和哈希函数:
- 关键码:数据元素的标识符,用于计算存储地址。
- 哈希函数:将数据元素的关键码转换为存储地址的函数。
- 映射过程:通过哈希函数h,将数据元素 x 的关键码转换为存储位置 y。y=h(x)
-
散列实现:
- 数据元素通过哈希函数映射到一个数组或表中。
- 当发生冲突(即两个不同元素映射到相同存储位置)时,采用一定的方法解决,如链地址法、开放地址法等。
-
优点:
- 快速检索:直接通过关键码计算存储位置,检索速度非常快。
- 高效操作:插入、删除操作都非常高效,不需要移动大量数据。
-
缺点:
- 不支持排序:数据元素存储位置是由哈希函数计算的,无法保证顺序存储。
- 空间需求较大:一般比线性表存储需要更多的空间。
- 关键字唯一性:记录的关键字不能重复,否则会产生冲突。
-
哈希函数映射:
- 图中展示了一个哈希函数将数据元素的关键码映射到存储位置。
- 关键码 xxx 通过哈希函数 hhh 计算得到存储位置 yyy。

-
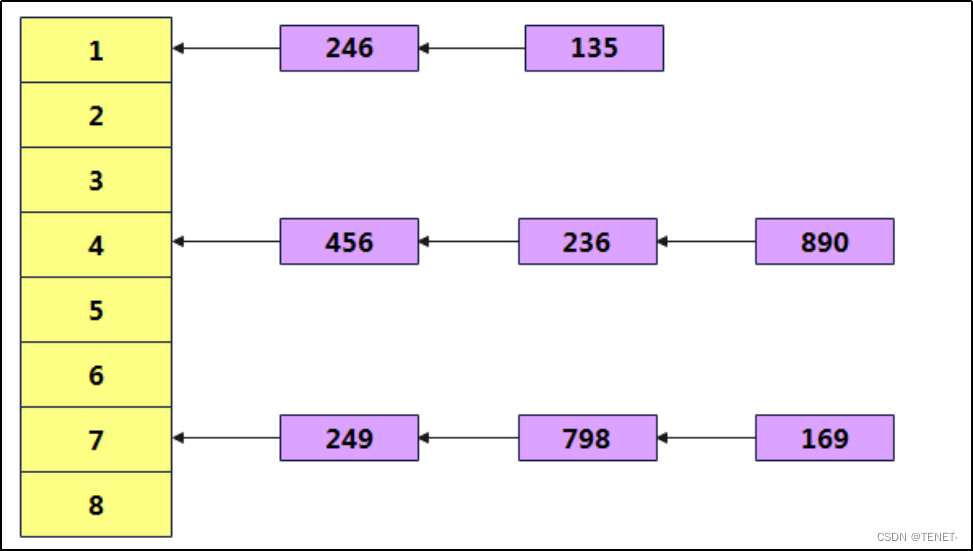
哈希表结构:
- 图中展示了一个哈希表,使用链地址法解决冲突。
- 每个表项是一个链表,用于存储多个映射到同一位置的元素。
6. 数据的运算
施加在数据上的运算包括运算的定义和实现。运算的实现是针对存储结构的,指出运算的具体操作步骤。
分配资源、建立结构、释放资源
- 分配资源:在使用数据结构之前,必须为其分配内存。例如,在C语言中使用
malloc函数分配动态数组或链表节点的内存。 - 建立结构:初始化数据结构。例如,创建一个空的链表头节点,或初始化一个空的栈。
- 释放资源:当数据结构不再需要时,必须释放其占用的内存资源。例如,在C语言中使用
free函数释放动态分配的内存。
插入和删除
- 插入:根据需要将新元素插入到数据结构的适当位置。例如,在链表中插入节点时,需要更新前驱节点和新节点的指针。
- 删除:移除数据结构中的元素,并适当调整其余元素。例如,从二叉搜索树中删除节点时,可能需要重排树结构以保持其性质。
获取和遍历
- 获取:直接访问数据结构中的特定元素。例如,使用数组索引访问元素或使用哈希表的键访问对应的值。
- 遍历:访问数据结构中的每一个元素。例如,使用循环遍历数组中的每一个元素,或使用递归遍历二叉树。
修改和排序
- 修改:更改数据结构中某个元素的值。例如,更新链表节点的数据或修改堆中某个元素的优先级。
- 排序:对数据结构中的元素进行排序。例如,使用快速排序算法对数组进行排序或使用堆排序对优先队列进行排序。