ResNet50V2
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、ResNetV1和ResNetV2的区别
ResNetV2 和 ResNetV1 都是深度残差网络(ResNet)的变体,它们的主要区别在于残差块的设计和批归一化(Batch Normalization, BN)的使用方式。ResNetV2 是在 ResNetV1 的基础上进行改进的一种版本,旨在提高模型的性能和稳定性。以下是它们之间的一些关键区别:
1. 残差块中的批归一化位置
ResNetV1:
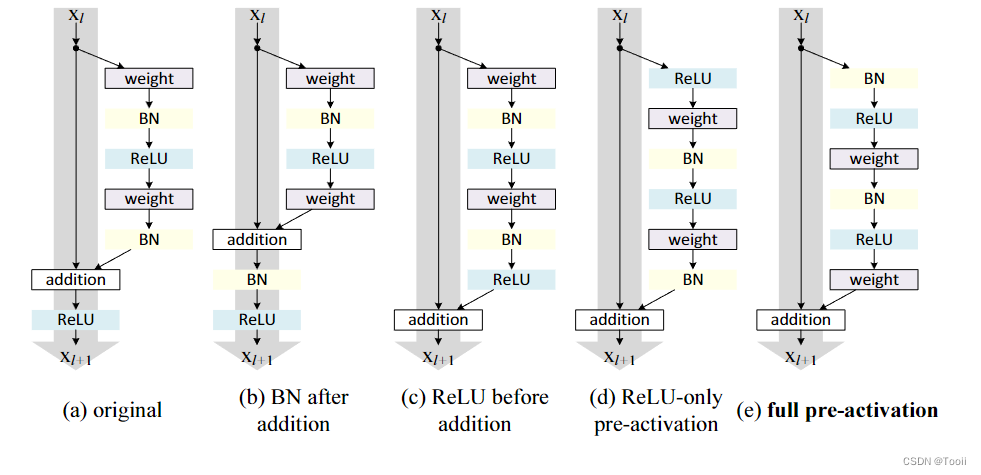
在 ResNetV1 中,批归一化层位于每个卷积层的后面,ReLU 激活函数在批归一化之后。具体来说,每个残差块的顺序是:
卷积层 -> 批归一化 -> ReLU -> 卷积层 -> 批归一化 -> 加和 -> ReLU

ResNetV2:
在 ResNetV2 中,批归一化和 ReLU 激活函数在每个卷积层之前进行。这种改变使得信息在模型中传播得更加顺畅,减轻了梯度消失的问题。具体来说,每个残差块的顺序是:
批归一化 -> ReLU -> 卷积层 -> 批归一化 -> ReLU -> 卷积层 -> 加和
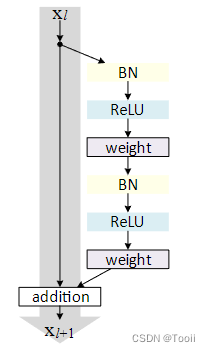
2. 预激活残差块
ResNetV2 引入了“预激活残差块”(Pre-activation Residual Block)的概念,即在每个残差块中的卷积操作之前进行批归一化和激活。这种设计有助于信息流动,特别是在深层网络中。
3. 全局平均池化和分类层
在 ResNetV1 中,最后一个残差模块的输出经过批归一化和 ReLU 激活之后,再通过全局平均池化层和全连接层进行分类。
在 ResNetV2 中,全局平均池化层和分类层之间没有额外的激活函数和归一化操作,直接对预激活的输出进行池化和分类。
4. 网络的深度和参数数量
ResNetV2 通常会采用更多的参数以提高性能,这包括在更深层次上引入更多的卷积层和更复杂的架构设计。
二、ResNetV2代码实现(PyTorch)
import torch
import torch .nn as nn
import torch.nn.functional as F
# BasicBlock用于ResNet-18和ResNet-34
class BasicBlockV2(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1, downsample=None):super(BasicBlockV2, self).__init__()# 在卷积层之前进行批归一化和 ReLU 激活,这是 ResNetV2 的主要区别之一self.bn1 = nn.BatchNorm2d(in_channels)self.relu = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)self.downsample = downsampledef forward(self, x):identity = x# 在卷积层之前进行批归一化和 ReLU 激活out = self.bn1(x)out = self.relu(out)out = self.conv1(out)out = self.bn2(out)out = self.relu(out)out = self.conv2(out)if self.downsample is not None:identity = self.downsample(x)out += identityreturn out
# Bottleneck用于ResNet-50, ResNet-101和ResNet-152
class BottleneckV2(nn.Module):expansion = 4 # 定义扩展因子def __init__(self, in_channels, out_channels, stride=1, downsample=None):super(BottleneckV2, self).__init__()# 在卷积层之前进行批归一化和 ReLU 激活,这是 ResNetV2 的主要区别之一self.bn1 = nn.BatchNorm2d(in_channels)self.relu = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channels)self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)self.downsample = downsampledef forward(self, x):identity = x# 在卷积层之前进行批归一化和 ReLU 激活out = self.bn1(x)out = self.relu(out)out = self.conv1(out)out = self.bn2(out)out = self.relu(out)out = self.conv2(out)out = self.bn3(out)out = self.relu(out)out = self.conv3(out)if self.downsample is not None:identity = self.downsample(x)out += identityreturn out
class ResNetV2(nn.Module):def __init__(self, block, layers, num_classes=1000):"""初始化ResNetV2模型参数:block: 使用的残差块类型(BasicBlockV2 或 BottleneckV2)layers: 每个残差模块中的残差块数量列表,例如[3, 4, 6, 3]num_classes: 分类任务的类别数, 默认为1000(适用于ImageNet数据集)"""super(ResNetV2, self).__init__()self.in_channels = 64# 初始卷积层,7x7卷积,步幅2,填充3self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 创建四个残差模块self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=2)self.layer4 = self._make_layer(block, 512, layers[3], stride=2)# 最后一个批归一化层,ResNetV2 的特点self.bn_last = nn.BatchNorm2d(512 * block.expansion)# 平均池化层和全连接层self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, out_channels, blocks, stride=1):"""构建残差模块参数:block: 使用的残差块类型(BasicBlockV2 或 BottleneckV2)out_channels: 残差块的输出通道数blocks: 残差块数量stride: 第一个残差块的步幅, 默认为1返回: 残差模块序列"""downsample = None# 如果步幅不为1或输入通道数不匹配,则进行下采样if stride != 1 or self.in_channels != out_channels * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels * block.expansion),)layers = []# 第一个残差块,可能需要下采样layers.append(block(self.in_channels, out_channels, stride, downsample))self.in_channels = out_channels * block.expansion# 其余残差块for _ in range(1, blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)# 最后的批归一化和 ReLU 激活x = self.bn_last(x)x = self.relu(x)# 全局平均池化和全连接层x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return x
def resnet18_v2(num_classes=1000):"""构建ResNet-18模型"""return ResNetV2(BasicBlockV2, [2, 2, 2, 2], num_classes)def resnet34_v2(num_classes=1000):"""构建ResNet-34模型"""return ResNetV2(BasicBlockV2, [3, 4, 6, 3], num_classes)def resnet50_v2(num_classes=1000):"""构建ResNet-50模型"""return ResNetV2(BottleneckV2, [3, 4, 6, 3], num_classes)def resnet101_v2(num_classes=1000):"""构建ResNet-101模型"""return ResNetV2(BottleneckV2, [3, 4, 23, 3], num_classes)def resnet152_v2(num_classes=1000):"""构建ResNet-152模型"""return ResNetV2(BottleneckV2, [3, 8, 36, 3], num_classes)
from torchinfo import summarymodel = resnet50_v2(num_classes=1000)
summary(model)

三、个人小结
通过对比 ResNetV1 和 ResNetV2,我们可以看出 ResNetV2 通过将批归一化和 ReLU 激活函数移动到卷积层之前,提出了预激活残差块的概念。这一改进不仅简化了梯度流动,减轻了梯度消失的问题,还提高了模型的训练稳定性和性能。本文还通过具体的代码实现,展示了如何在 PyTorch 中构建和训练 ResNetV2 模型,包括 ResNet-18, ResNet-34, ResNet-50, ResNet-101, 和 ResNet-152 各种变体。