现代信息检索笔记(二)——布尔检索
目录
信息检索概述
IR vs数据库: 结构化vs 非结构化数据
结构化数据
非结构化数据
半结构化数据
传统信息检索VS现代信息检索
布尔检索
倒排索引
一个例子
建立词项(可以是字、词、短语、一句话)-文档的关联矩阵。
关联向量
检索效果的评价
建立倒排索引表
索引构建过程:
布尔查询的处理
查询优化
信息检索概述
Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
信息检索是从大规模非结构化数据(通常是文本) 的集合(通常保存在计算机上)中找出满足用户 信息需求的资料(通常是文档)的过程。
Document –文档
Unstructured – 非结构化
Information need –信息需求
Collection—文档集、语料库
IR vs数据库: 结构化vs 非结构化数据
结构化数据
通常指表格中的数据。
数据库常常支持范围或者精确匹配查询。
非结构化数据
通常指自由文本
允许
- 关键词加上操作符号的查询
- 更复杂的概念性查询,
找出所有的有关药物滥用(drug abuse)的网页
经典的检索模型一般都针对自由文本进行处理
考虑文本之间的相似性 搜兵乓球,出现刘国梁
半结构化数据
没有数据是没有结构的。
不同位置的关键词权重是不一样的,如标题比正文权重更高。
传统信息检索VS现代信息检索
传统信息检索主要关注非结构化、半结构化数据
现代信息检索中也处理结构化数据
第一个检索只能使用结构化数据,而结构化数据仅占全部数据的20%,日志文件+机器数据又占非结构化数据的90%。如何利用日志文件等非结构化数据是现在信息检索发展的关键。
布尔检索
针对布尔查询的检索,布尔查询是指利用AND, OR 或 者NOT操作符将词项连接起来的查询
布尔模型是最简单的模型 第一个模型 但在现在最先进的模型中依然使用
输入信息,被切割为关键词
人工and 检索and not 教材
百度的高级检索中有。
1\And 2\or not 3排序
倒排索引
一个例子
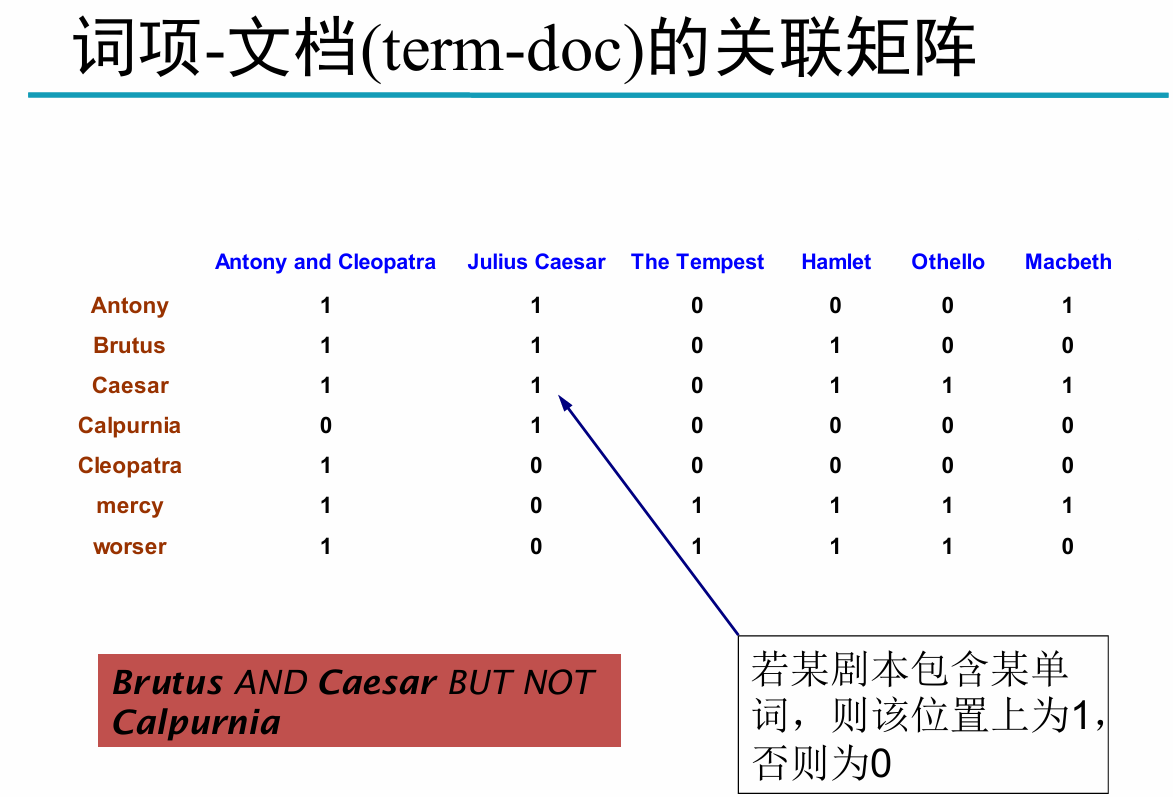
莎士比亚的哪部剧本包含Brutus及Caesar但是不包含 Calpurnia? 布尔表达式为Brutus AND Caesar AND NOT Calpurnia。
笨方法:从头到尾扫描所有剧本,对每部剧本判断它是否 包含Brutus AND Caesar ,同时又不包含Calpurnia
笨方法为什么不好?
§ 速度超慢(特别是大型文档集) § 处理NOT Calpurnia 并不容易(一旦包含即可停止判断) § 不太容易支持其他操作(e.g., find the word Romans near countrymen) § 不支持检索结果的排序(即只返回较好的结果)
因为现在语料库太长,从头到尾不现实。
建立词项(可以是字、词、短语、一句话)-文档的关联矩阵。
关联向量
关联矩阵的每一列都是0/1向量,每个0/1都对应 一个词项
给定查询Brutus AND Caesar AND NOT Calpurnia
取出三个行向量,并对Calpurnia 的行向量求补, 最后按位进行与操作
110100 AND 110111 AND 101111 = 100100.
检索效果的评价
正确率(Precision) : 返回结果文档中正确的比例。 如返回80篇文档,其中20篇相关,正确率1/4
召回率(Recall) : 全部相关文档中被返回的比例, 如返回80篇文档,其中20篇相关,但是总的应该 相关的文档是100篇,召回率1/5
正确率和召回率反映检索效果的两个方面,缺一 不可。
全部返回,正确率低,召回率100%
只返回一个非常可靠的结果,正确率100%
召回率低F是P R的调和平均
词项-文档的关联矩阵应该是高度稀疏的矩阵(就是1的占比很少)
为了降低占用空间,我们只把1的位置保留下来。
建立倒排索引表
把1保留下来,把0去掉。从稀疏矩阵到存储docID的向量。
对每个词项t, 记录所有包含t的文档列表.
每篇文档用一个唯一的docID来表示,通常是正整数, 如1,2,3…
通常采用变长表方式
磁盘上,顺序存储方式较好,便于快速读取
内存中,采用链表或者可变长数组方式
索引构建过程:
词条序列、排序、词典&倒排记录表
布尔查询的处理
And查询的处理 合并(Merge)两个倒排记录表,即求交集
每个倒排记录表都有一个定位指针,两个指针同 时从前往后扫描, 每次比较当前指针对应倒排记录, 然后移动某个或两个指针。合并时间为两个表长 之和的线性时间
OR表达式:Brutus OR Caesar 两个倒排记录表的并集
NOT表达式:Brutus AND NOT Caesar 两个倒排记录表的减
查询优化
合并索引表!实现and操作。
一、先最短的两个合并,DF小的先合并。//保留DF的原因之一
二、或者将布尔表达式转化为合取范式,
获得每个词项的df,(保守)估算每个子合取范式的df,最后将子合取范式的df从小到大排序。
布尔检索可以限定很多条件。
布尔检索构造复杂,对用户极其不友好。
布尔检索没有排序。
没有利用词频信息。