MySQL之聚簇索引和非聚簇索引
1、什么是聚簇索引和非聚簇索引?
聚簇索引,通常也叫聚集索引。
非聚簇索引,指的是二级索引。
下面看一下它们的含义:
1.1、聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一索引作为聚集索引。
- 如果没有主键或唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
说到聚集索引,就不得不提到“回表查询”了。
2、什么是回表查询?
通过二级索引找到对应的主键值,到聚集索引中查找整行数据,这个过程就是回表。
示例:有user表如下:
CREATE TABLE `user` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '技术主键',`name` varchar(100) DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年龄',PRIMARY KEY (`id`),KEY `idx_1` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';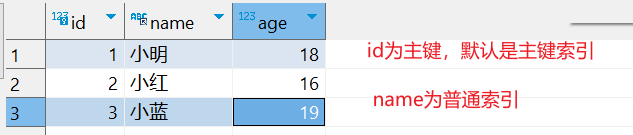
这里,id作为主键,也就是聚集索引。name字段为普通索引,就是二级索引。
(1)假如此时有sql1:select * from user where id=1;
那么,id作为聚集索引,数据存储与索引放到了一块,索引结构的叶子节点保存了行数据,直接就可以得到整行数据【id=1,name=小明,age=18】
(2)假如又有sql2:select * from user where name='小明';
那么,此时就需要“回表查询”了。回表过程如下:
①因为建了“name”这个二级索引,(“select *”需要查整行数据);
②先用“小明”去二级索引中找到“小明”的id=1;
③再用“1”去找聚集索引,最终拿到整行数据。